 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiViBench: Benchmarking Think-in-Video Reasoning for Video Generative Models
Nov 17, 2025The rapid evolution of video generative models has shifted their focus from producing visually plausible outputs to tackling tasks requiring physical plausibility and logical consistency. However, despite recent breakthroughs such as Veo 3's chain-of-frames reasoning, it remains unclear whether these models can exhibit reasoning capabilities similar to large language models (LLMs). Existing benchmarks predominantly evaluate visual fidelity and temporal coherence, failing to capture higher-order reasoning abilities. To bridge this gap, we propose TiViBench, a hierarchical benchmark specifically designed to evaluate the reasoning capabilities of image-to-video (I2V) generation models. TiViBench systematically assesses reasoning across four dimensions: i) Structural Reasoning & Search, ii) Spatial & Visual Pattern Reasoning, iii) Symbolic & Logical Reasoning, and iv) Action Planning & Task Execution, spanning 24 diverse task scenarios across 3 difficulty levels. Through extensive evaluations, we show that commercial models (e.g., Sora 2, Veo 3.1) demonstrate stronger reasoning potential, while open-source models reveal untapped potential that remains hindered by limited training scale and data diversity. To further unlock this potential, we introduce VideoTPO, a simple yet effective test-time strategy inspired by preference optimization. By performing LLM self-analysis on generated candidates to identify strengths and weaknesses, VideoTPO significantly enhances reasoning performance without requiring additional training, data, or reward models. Together, TiViBench and VideoTPO pave the way for evaluating and advancing reasoning in video generation models, setting a foundation for future research in this emerging field.
Linear-MoE: Linear Sequence Modeling Meets Mixture-of-Experts
Mar 07, 2025
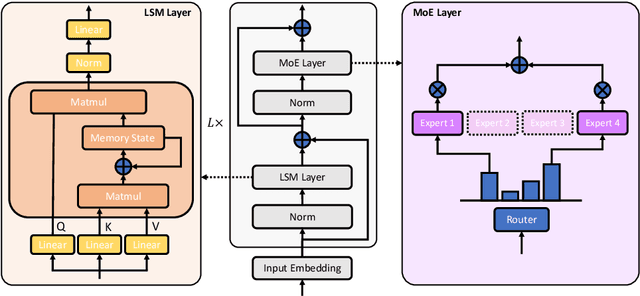
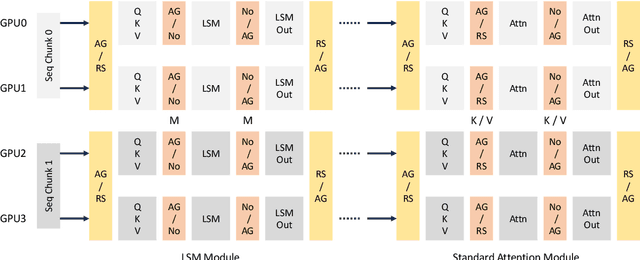
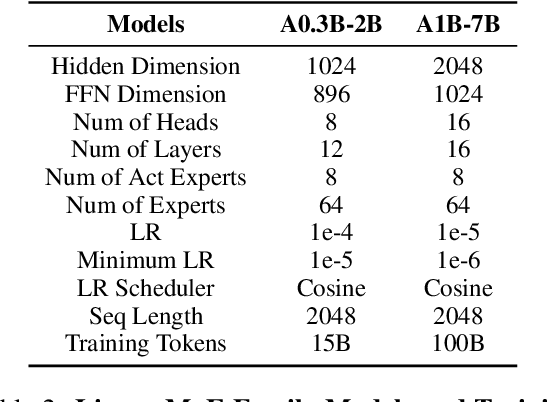
Linear Sequence Modeling (LSM) like linear attention, state space models and linear RNNs, and Mixture-of-Experts (MoE) have recently emerged as significant architectural improvements. In this paper, we introduce Linear-MoE, a production-level system for modeling and training large-scale models that integrate LSM with MoE. Linear-MoE leverages the advantages of both LSM modules for linear-complexity sequence modeling and MoE layers for sparsely activation, aiming to offer high performance with efficient training. The Linear-MoE system comprises: 1) Modeling subsystem, which provides a unified framework supporting all instances of LSM. and 2) Training subsystem, which facilitates efficient training by incorporating various advanced parallelism technologies, particularly Sequence Parallelism designed for Linear-MoE models. Additionally, we explore hybrid models that combine Linear-MoE layers with standard Transformer-MoE layers with its Sequence Parallelism to further enhance model flexibility and performance. Evaluations on two model series, A0.3B-2B and A1B-7B, demonstrate Linear-MoE achieves efficiency gains while maintaining competitive performance on various benchmarks, showcasing its potential as a next-generation foundational model architecture. Code: https://github.com/OpenSparseLLMs/Linear-MoE.
Liger: Linearizing Large Language Models to Gated Recurrent Structures
Mar 03, 2025



Transformers with linear recurrent modeling offer linear-time training and constant-memory inference. Despite their demonstrated efficiency and performance, pretraining such non-standard architectures from scratch remains costly and risky. The linearization of large language models (LLMs) transforms pretrained standard models into linear recurrent structures, enabling more efficient deployment. However, current linearization methods typically introduce additional feature map modules that require extensive fine-tuning and overlook the gating mechanisms used in state-of-the-art linear recurrent models. To address these issues, this paper presents Liger, short for Linearizing LLMs to gated recurrent structures. Liger is a novel approach for converting pretrained LLMs into gated linear recurrent models without adding extra parameters. It repurposes the pretrained key matrix weights to construct diverse gating mechanisms, facilitating the formation of various gated recurrent structures while avoiding the need to train additional components from scratch. Using lightweight fine-tuning with Low-Rank Adaptation (LoRA), Liger restores the performance of the linearized gated recurrent models to match that of the original LLMs. Additionally, we introduce Liger Attention, an intra-layer hybrid attention mechanism, which significantly recovers 93\% of the Transformer-based LLM at 0.02\% pre-training tokens during the linearization process, achieving competitive results across multiple benchmarks, as validated on models ranging from 1B to 8B parameters. Code is available at https://github.com/OpenSparseLLMs/Linearization.
MoM: Linear Sequence Modeling with Mixture-of-Memories
Feb 19, 2025



Linear sequence modeling methods, such as linear attention, state space modeling, and linear RNNs, offer significant efficiency improvements by reducing the complexity of training and inference. However, these methods typically compress the entire input sequence into a single fixed-size memory state, which leads to suboptimal performance on recall-intensive downstream tasks. Drawing inspiration from neuroscience, particularly the brain's ability to maintain robust long-term memory while mitigating "memory interference", we introduce a novel architecture called Mixture-of-Memories (MoM). MoM utilizes multiple independent memory states, with a router network directing input tokens to specific memory states. This approach greatly enhances the overall memory capacity while minimizing memory interference. As a result, MoM performs exceptionally well on recall-intensive tasks, surpassing existing linear sequence modeling techniques. Despite incorporating multiple memory states, the computation of each memory state remains linear in complexity, allowing MoM to retain the linear-complexity advantage during training, while constant-complexity during inference. Our experimental results show that MoM significantly outperforms current linear sequence models on downstream language tasks, particularly recall-intensive tasks, and even achieves performance comparable to Transformer models. The code is released at https://github.com/OpenSparseLLMs/MoM and is also released as a part of https://github.com/OpenSparseLLMs/Linear-MoE.
LASP-2: Rethinking Sequence Parallelism for Linear Attention and Its Hybrid
Feb 11, 2025



Linear sequence modeling approaches, such as linear attention, provide advantages like linear-time training and constant-memory inference over sequence lengths. However, existing sequence parallelism (SP) methods are either not optimized for the right-product-first feature of linear attention or use a ring-style communication strategy, which results in lower computation parallelism, limits their scalability for longer sequences in distributed systems. In this paper, we introduce LASP-2, a new SP method to enhance both communication and computation parallelism when training linear attention transformer models with very-long input sequences. Compared to previous work LASP, LASP-2 rethinks the minimal communication requirement for SP on linear attention layers, reorganizes the whole communication-computation workflow of LASP. In this way, only one single AllGather collective communication is needed on intermediate memory states, whose sizes are independent of the sequence length, leading to significant improvements of both communication and computation parallelism, as well as their overlap. Additionally, we extend LASP-2 to LASP-2H by applying similar communication redesign to standard attention modules, offering an efficient SP solution for hybrid models that blend linear and standard attention layers. Our evaluation on a Linear-Llama3 model, a variant of Llama3 with linear attention replacing standard attention, demonstrates the effectiveness of LASP-2 and LASP-2H. Specifically, LASP-2 achieves training speed improvements of 15.2% over LASP and 36.6% over Ring Attention, with a sequence length of 2048K across 64 GPUs. The Code is released as a part of: https://github.com/OpenSparseLLMs/Linear-MoE.
Time-SSM: Simplifying and Unifying State Space Models for Time Series Forecasting
May 25, 2024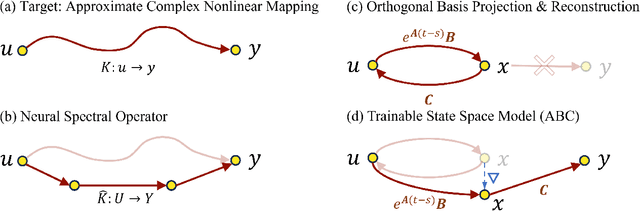

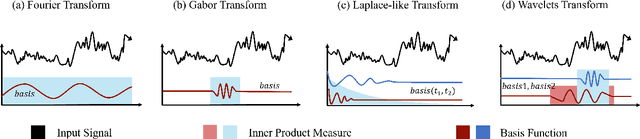
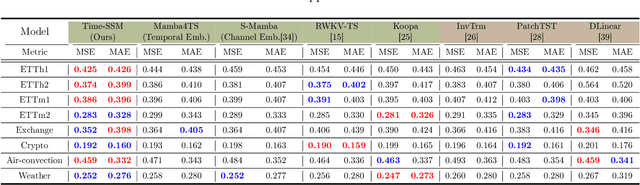
State Space Models (SSMs) have emerged as a potent tool in sequence modeling tasks in recent years. These models approximate continuous systems using a set of basis functions and discretize them to handle input data, making them well-suited for modeling time series data collected at specific frequencies from continuous systems. Despite its potential, the application of SSMs in time series forecasting remains underexplored, with most existing models treating SSMs as a black box for capturing temporal or channel dependencies. To address this gap, this paper proposes a novel theoretical framework termed Dynamic Spectral Operator, offering more intuitive and general guidance on applying SSMs to time series data. Building upon our theory, we introduce Time-SSM, a novel SSM-based foundation model with only one-seventh of the parameters compared to Mamba. Various experiments validate both our theoretical framework and the superior performance of Time-SSM.