 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Exchange-Aware Token Pruning for Efficient Audio-Visual Captioning
Jun 09, 2026Audio-visual captioning generates natural language descriptions from video and audio content. Multimodal LLMs have advanced this task, but both modalities contribute many tokens to the LLM input, where prefill self-attention scales quadratically. Existing token-pruning methods usually retain tokens by attention, saliency, or cross-entropy loss, yet the hard threshold selection makes it difficult to retain tokens that are truly valuable, especially for high-confusing tokens near the decision boundary. To this end, we propose a AVEX-Prune, an RL-based audio-visual dynamic token pruning method in this work. In our AVEX-Prune, an audio-visual token exchange strategy is proposed to select truly valuable tokens by replacing low-confidence retained tokens with high-confidence candidate tokens from the same or the other modality, and measuring the differences in caption generation from token swaps. AVEX-Prune preserves full-token quality at a 40% retention ratio on both VILA 1.5-8B (54.5 vs. 54.6) and VideoLLaMA 2 (57.0 vs. 56.8).
FlyRoute: Self-Evolving Agent Profiling via Data Flywheel for Adaptive Task Routing
May 21, 2026Enterprise routers assign queries to expert agents, yet deployed profiles stay static while agents evolve (prompts, tools, models), and developers rarely keep descriptions or exemplars current. We present FlyRoute, a self-evolving profiling framework that grows capability evidence from real traffic: dispatch candidates, quality-gate successful pairs into each agent's success store, periodically distill evidence into learned capability descriptions, and inject those descriptions together with BM25-retrieved successes into an LLM router. To make this flywheel data-efficient, FlyRoute introduces a targeted exploration policy that combines profile uncertainty, BM25 relevance, and lexical novelty, prioritizing under-profiled agents only for plausible queries and avoiding redundant evidence collection. In experiments on our proprietary enterprise developer-support dataset of real routed queries, FlyRoute improves a same-backbone zero-shot LLM router from 72.57% to 78.04% with only five seed queries per agent, showing that profile retrieval already strengthens cold-start routing. After streaming 7,211 labeled training queries through the flywheel, accuracy rises to 89.83% (+17.26pp over zero-shot; +11.79pp over cold start), with consistent gains across four expert domains under standard routing accuracy on single-gold test queries.
KEPIL: Knowledge-Enhanced Prompt-Image Learning for Prompt-Robust Disease Detection
May 09, 2026Vision--language models (VLMs) show promise for clinical decision support in radiology because they enable joint reasoning over radiological images and clinical text, thereby leveraging complementary clinical information. However, radiological findings are long-tailed in practice, leaving some conditions underrepresented and making zero-shot inference essential. Yet current CLIP-style medical VLMs are sensitive to prompt variations and often lack trustworthy external knowledge at inference time, which hinders reliable clinical deployment. We present \textit{KEPIL}, a prompt-robust framework that integrates curated medical knowledge to stabilize zero-shot generalization. KEPIL comprises: (i) \emph{dynamic prompt enrichment} using ontologies with LLM assistance, (ii) a \emph{semantic-aware contrastive loss} aligning embeddings of equivalent prompt variants via a dual-embedding objective, and (iii) \emph{entity-centric report standardization} to yield ontology-aligned representations. Across seven benchmarks, KEPIL achieves state-of-the-art zero-shot inference performance; under prompt-variation tests, it improves AUC by \(6.37\%\) on \textit{CheXpert} and by \(4.11\%\) on average. These results suggest that structured knowledge and robust prompt design are key to clinically reliable radiology-facing VLMs. Code will be released at https://github.com/Roypic/KEPIL.
Does Pass Rate Tell the Whole Story? Evaluating Design Constraint Compliance in LLM-based Issue Resolution
Apr 07, 2026Repository-level issue resolution benchmarks have become a standard testbed for evaluating LLM-based agents, yet success is still predominantly measured by test pass rates. In practice, however, acceptable patches must also comply with project-specific design constraints, such as architectural conventions, error-handling policies, and maintainability requirements, which are rarely encoded in tests and are often documented only implicitly in code review discussions. This paper introduces \textit{design-aware issue resolution} and presents \bench{}, a benchmark that makes such implicit design constraints explicit and measurable. \bench{} is constructed by mining and validating design constraints from real-world pull requests, linking them to issue instances, and automatically checking patch compliance using an LLM-based verifier, yielding 495 issues and 1,787 validated constraints across six repositories, aligned with SWE-bench-Verified and SWE-bench-Pro. Experiments with state-of-the-art agents show that test-based correctness substantially overestimates patch quality: fewer than half of resolved issues are fully design-satisfying, design violations are widespread, and functional correctness exhibits negligible statistical association with design satisfaction. While providing issue-specific design guidance reduces violations, substantial non-compliance remains, highlighting a fundamental gap in current agent capabilities and motivating design-aware evaluation beyond functional correctness.
SOON: Symmetric Orthogonal Operator Network for Global Subseasonal-to-Seasonal Climate Forecasting
Feb 04, 2026Accurate global Subseasonal-to-Seasonal (S2S) climate forecasting is critical for disaster preparedness and resource management, yet it remains challenging due to chaotic atmospheric dynamics. Existing models predominantly treat atmospheric fields as isotropic images, conflating the distinct physical processes of zonal wave propagation and meridional transport, and leading to suboptimal modeling of anisotropic dynamics. In this paper, we propose the Symmetric Orthogonal Operator Network (SOON) for global S2S climate forecasting. It couples: (1) an Anisotropic Embedding strategy that tokenizes the global grid into latitudinal rings, preserving the integrity of zonal periodic structures; and (2) a stack of SOON Blocks that models the alternating interaction of Zonal and Meridional Operators via a symmetric decomposition, structurally mitigating discretization errors inherent in long-term integration. Extensive experiments on the Earth Reanalysis 5 dataset demonstrate that SOON establishes a new state-of-the-art, significantly outperforming existing methods in both forecasting accuracy and computational efficiency.
SEDformer: Event-Synchronous Spiking Transformers for Irregular Telemetry Time Series Forecasting
Feb 03, 2026Telemetry streams from large-scale Internet-connected systems (e.g., IoT deployments and online platforms) naturally form an irregular multivariate time series (IMTS) whose accurate forecasting is operationally vital. A closer examination reveals a defining Sparsity-Event Duality (SED) property of IMTS, i.e., long stretches with sparse or no observations are punctuated by short, dense bursts where most semantic events (observations) occur. However, existing Graph- and Transformer-based forecasters ignore SED: pre-alignment to uniform grids with heavy padding violates sparsity by inflating sequences and forcing computation at non-informative steps, while relational recasting weakens event semantics by disrupting local temporal continuity. These limitations motivate a more faithful and natural modeling paradigm for IMTS that aligns with its SED property. We find that Spiking Neural Networks meet this requirement, as they communicate via sparse binary spikes and update in an event-driven manner, aligning naturally with the SED nature of IMTS. Therefore, we present SEDformer, an SED-enhanced Spiking Transformer for telemetry IMTS forecasting that couples: (1) a SED-based Spike Encoder converts raw observations into event synchronous spikes using an Event-Aligned LIF neuron, (2) an Event-Preserving Temporal Downsampling module compresses long gaps while retaining salient firings and (3) a stack of SED-based Spike Transformer blocks enable intra-series dependency modeling with a membrane-based linear attention driven by EA-LIF spiking features. Experiments on public telemetry IMTS datasets show that SEDformer attains state-of-the-art forecasting accuracy while reducing energy and memory usage, providing a natural and efficient path for modeling IMTS.
WordCraft: Scaffolding the Keyword Method for L2 Vocabulary Learning with Multimodal LLMs
Jan 31, 2026Applying the keyword method for vocabulary memorization remains a significant challenge for L1 Chinese-L2 English learners. They frequently struggle to generate phonologically appropriate keywords, construct coherent associations, and create vivid mental imagery to aid long-term retention. Existing approaches, including fully automated keyword generation and outcome-oriented mnemonic aids, either compromise learner engagement or lack adequate process-oriented guidance. To address these limitations, we conducted a formative study with L1 Chinese-L2 English learners and educators (N=18), which revealed key difficulties and requirements in applying the keyword method to vocabulary learning. Building on these insights, we introduce WordCraft, a learner-centered interactive tool powered by Multimodal Large Language Models (MLLMs). WordCraft scaffolds the keyword method by guiding learners through keyword selection, association construction, and image formation, thereby enhancing the effectiveness of vocabulary memorization. Two user studies demonstrate that WordCraft not only preserves the generation effect but also achieves high levels of effectiveness and usability.
Lamps: Learning Anatomy from Multiple Perspectives via Self-supervision in Chest Radiographs
Jan 02, 2026Foundation models have been successful in natural language processing and computer vision because they are capable of capturing the underlying structures (foundation) of natural languages. However, in medical imaging, the key foundation lies in human anatomy, as these images directly represent the internal structures of the body, reflecting the consistency, coherence, and hierarchy of human anatomy. Yet, existing self-supervised learning (SSL) methods often overlook these perspectives, limiting their ability to effectively learn anatomical features. To overcome the limitation, we built Lamps (learning anatomy from multiple perspectives via self-supervision) pre-trained on large-scale chest radiographs by harmoniously utilizing the consistency, coherence, and hierarchy of human anatomy as the supervision signal. Extensive experiments across 10 datasets evaluated through fine-tuning and emergent property analysis demonstrate Lamps' superior robustness, transferability, and clinical potential when compared to 10 baseline models. By learning from multiple perspectives, Lamps presents a unique opportunity for foundation models to develop meaningful, robust representations that are aligned with the structure of human anatomy.
Learning Anatomy from Multiple Perspectives via Self-supervision in Chest Radiographs
Dec 28, 2025Foundation models have been successful in natural language processing and computer vision because they are capable of capturing the underlying structures (foundation) of natural languages. However, in medical imaging, the key foundation lies in human anatomy, as these images directly represent the internal structures of the body, reflecting the consistency, coherence, and hierarchy of human anatomy. Yet, existing self-supervised learning (SSL) methods often overlook these perspectives, limiting their ability to effectively learn anatomical features. To overcome the limitation, we built Lamps (learning anatomy from multiple perspectives via self-supervision) pre-trained on large-scale chest radiographs by harmoniously utilizing the consistency, coherence, and hierarchy of human anatomy as the supervision signal. Extensive experiments across 10 datasets evaluated through fine-tuning and emergent property analysis demonstrate Lamps' superior robustness, transferability, and clinical potential when compared to 10 baseline models. By learning from multiple perspectives, Lamps presents a unique opportunity for foundation models to develop meaningful, robust representations that are aligned with the structure of human anatomy.
Multi-Order Wavelet Derivative Transform for Deep Time Series Forecasting
May 17, 2025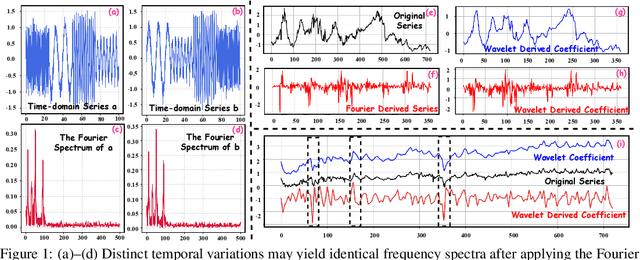
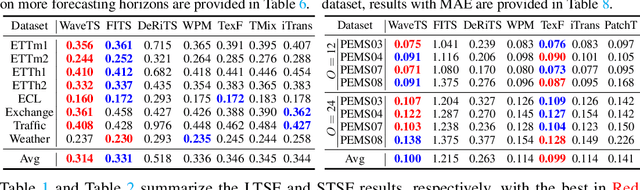
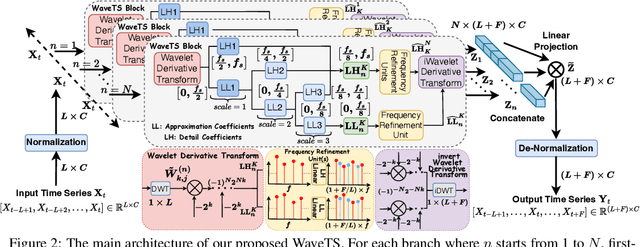
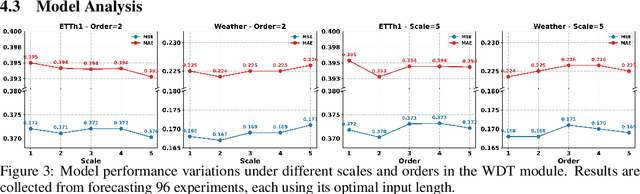
In deep time series forecasting, the Fourier Transform (FT) is extensively employed for frequency representation learning. However, it often struggles in capturing multi-scale, time-sensitive patterns. Although the Wavelet Transform (WT) can capture these patterns through frequency decomposition, its coefficients are insensitive to change points in time series, leading to suboptimal modeling. To mitigate these limitations, we introduce the multi-order Wavelet Derivative Transform (WDT) grounded in the WT, enabling the extraction of time-aware patterns spanning both the overall trend and subtle fluctuations. Compared with the standard FT and WT, which model the raw series, the WDT operates on the derivative of the series, selectively magnifying rate-of-change cues and exposing abrupt regime shifts that are particularly informative for time series modeling. Practically, we embed the WDT into a multi-branch framework named WaveTS, which decomposes the input series into multi-scale time-frequency coefficients, refines them via linear layers, and reconstructs them into the time domain via the inverse WDT. Extensive experiments on ten benchmark datasets demonstrate that WaveTS achieves state-of-the-art forecasting accuracy while retaining high computational efficiency.