 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiMo-V2-Flash Technical Report
Jan 08, 2026We present MiMo-V2-Flash, a Mixture-of-Experts (MoE) model with 309B total parameters and 15B active parameters, designed for fast, strong reasoning and agentic capabilities. MiMo-V2-Flash adopts a hybrid attention architecture that interleaves Sliding Window Attention (SWA) with global attention, with a 128-token sliding window under a 5:1 hybrid ratio. The model is pre-trained on 27 trillion tokens with Multi-Token Prediction (MTP), employing a native 32k context length and subsequently extended to 256k. To efficiently scale post-training compute, MiMo-V2-Flash introduces a novel Multi-Teacher On-Policy Distillation (MOPD) paradigm. In this framework, domain-specialized teachers (e.g., trained via large-scale reinforcement learning) provide dense and token-level reward, enabling the student model to perfectly master teacher expertise. MiMo-V2-Flash rivals top-tier open-weight models such as DeepSeek-V3.2 and Kimi-K2, despite using only 1/2 and 1/3 of their total parameters, respectively. During inference, by repurposing MTP as a draft model for speculative decoding, MiMo-V2-Flash achieves up to 3.6 acceptance length and 2.6x decoding speedup with three MTP layers. We open-source both the model weights and the three-layer MTP weights to foster open research and community collaboration.
MiMo-Audio: Audio Language Models are Few-Shot Learners
Dec 29, 2025Existing audio language models typically rely on task-specific fine-tuning to accomplish particular audio tasks. In contrast, humans are able to generalize to new audio tasks with only a few examples or simple instructions. GPT-3 has shown that scaling next-token prediction pretraining enables strong generalization capabilities in text, and we believe this paradigm is equally applicable to the audio domain. By scaling MiMo-Audio's pretraining data to over one hundred million of hours, we observe the emergence of few-shot learning capabilities across a diverse set of audio tasks. We develop a systematic evaluation of these capabilities and find that MiMo-Audio-7B-Base achieves SOTA performance on both speech intelligence and audio understanding benchmarks among open-source models. Beyond standard metrics, MiMo-Audio-7B-Base generalizes to tasks absent from its training data, such as voice conversion, style transfer, and speech editing. MiMo-Audio-7B-Base also demonstrates powerful speech continuation capabilities, capable of generating highly realistic talk shows, recitations, livestreaming and debates. At the post-training stage, we curate a diverse instruction-tuning corpus and introduce thinking mechanisms into both audio understanding and generation. MiMo-Audio-7B-Instruct achieves open-source SOTA on audio understanding benchmarks (MMSU, MMAU, MMAR, MMAU-Pro), spoken dialogue benchmarks (Big Bench Audio, MultiChallenge Audio) and instruct-TTS evaluations, approaching or surpassing closed-source models. Model checkpoints and full evaluation suite are available at https://github.com/XiaomiMiMo/MiMo-Audio.
Mitigating Overthinking through Reasoning Shaping
Oct 10, 2025Large reasoning models (LRMs) boosted by Reinforcement Learning from Verifier Reward (RLVR) have shown great power in problem solving, yet they often cause overthinking: excessive, meandering reasoning that inflates computational cost. Prior designs of penalization in RLVR manage to reduce token consumption while often harming model performance, which arises from the oversimplicity of token-level supervision. In this paper, we argue that the granularity of supervision plays a crucial role in balancing efficiency and accuracy, and propose Group Relative Segment Penalization (GRSP), a step-level method to regularize reasoning. Since preliminary analyses show that reasoning segments are strongly correlated with token consumption and model performance, we design a length-aware weighting mechanism across segment clusters. Extensive experiments demonstrate that GRSP achieves superior token efficiency without heavily compromising accuracy, especially the advantages with harder problems. Moreover, GRSP stabilizes RL training and scales effectively across model sizes.
P-Aligner: Enabling Pre-Alignment of Language Models via Principled Instruction Synthesis
Aug 06, 2025
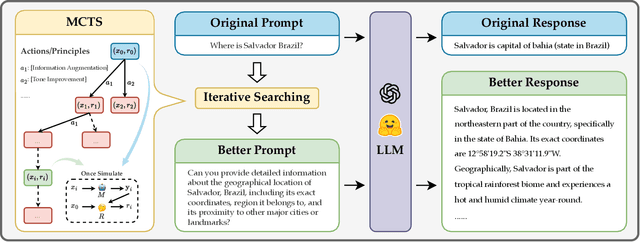
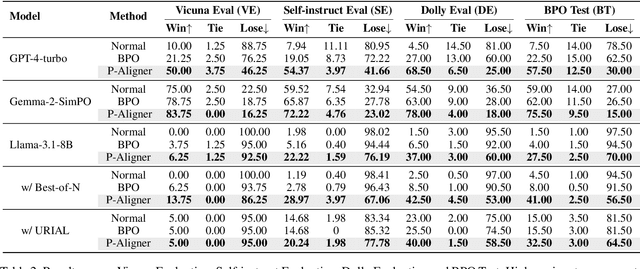
Large Language Models (LLMs) are expected to produce safe, helpful, and honest content during interaction with human users, but they frequently fail to align with such values when given flawed instructions, e.g., missing context, ambiguous directives, or inappropriate tone, leaving substantial room for improvement along multiple dimensions. A cost-effective yet high-impact way is to pre-align instructions before the model begins decoding. Existing approaches either rely on prohibitive test-time search costs or end-to-end model rewrite, which is powered by a customized training corpus with unclear objectives. In this work, we demonstrate that the goal of efficient and effective preference alignment can be achieved by P-Aligner, a lightweight module generating instructions that preserve the original intents while being expressed in a more human-preferred form. P-Aligner is trained on UltraPrompt, a new dataset synthesized via a proposed principle-guided pipeline using Monte-Carlo Tree Search, which systematically explores the space of candidate instructions that are closely tied to human preference. Experiments across different methods show that P-Aligner generally outperforms strong baselines across various models and benchmarks, including average win-rate gains of 28.35% and 8.69% on GPT-4-turbo and Gemma-2-SimPO, respectively. Further analyses validate its effectiveness and efficiency through multiple perspectives, including data quality, search strategies, iterative deployment, and time overhead.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
WorkTeam: Constructing Workflows from Natural Language with Multi-Agents
Mar 28, 2025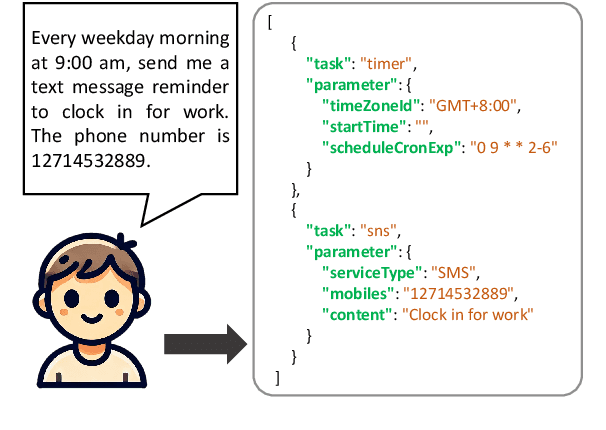
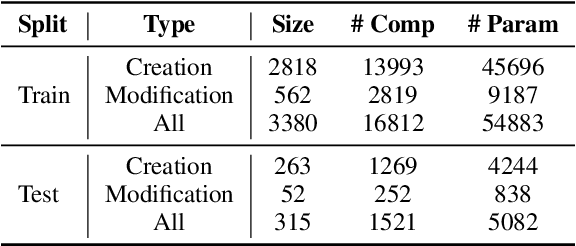
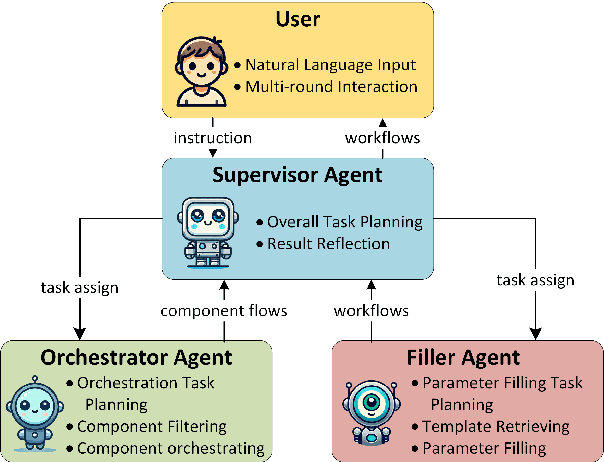
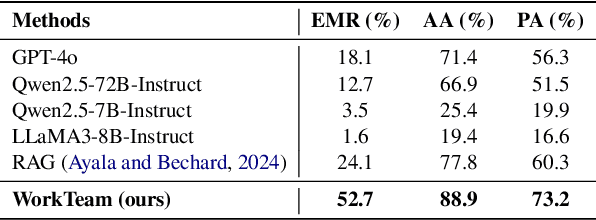
Workflows play a crucial role in enhancing enterprise efficiency by orchestrating complex processes with multiple tools or components. However, hand-crafted workflow construction requires expert knowledge, presenting significant technical barriers. Recent advancements in Large Language Models (LLMs) have improved the generation of workflows from natural language instructions (aka NL2Workflow), yet existing single LLM agent-based methods face performance degradation on complex tasks due to the need for specialized knowledge and the strain of task-switching. To tackle these challenges, we propose WorkTeam, a multi-agent NL2Workflow framework comprising a supervisor, orchestrator, and filler agent, each with distinct roles that collaboratively enhance the conversion process. As there are currently no publicly available NL2Workflow benchmarks, we also introduce the HW-NL2Workflow dataset, which includes 3,695 real-world business samples for training and evaluation. Experimental results show that our approach significantly increases the success rate of workflow construction, providing a novel and effective solution for enterprise NL2Workflow services.
MPO: Boosting LLM Agents with Meta Plan Optimization
Mar 04, 2025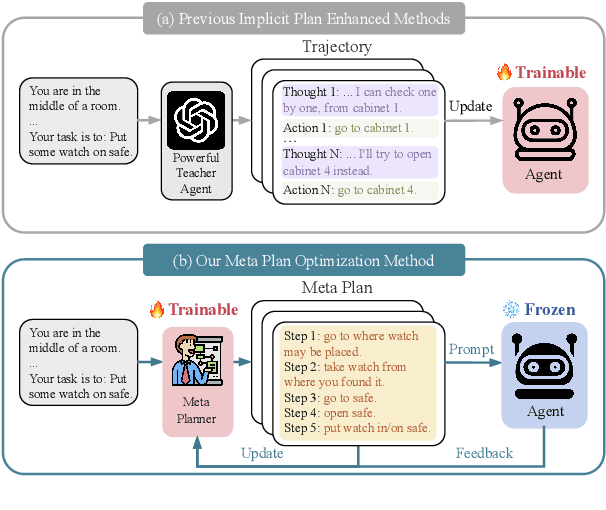

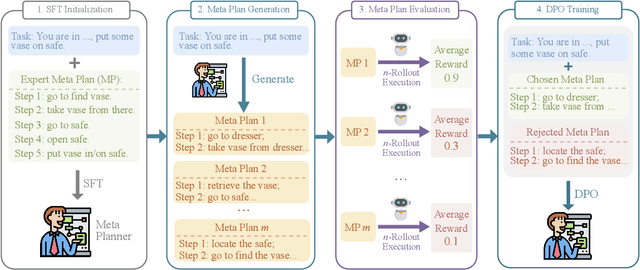
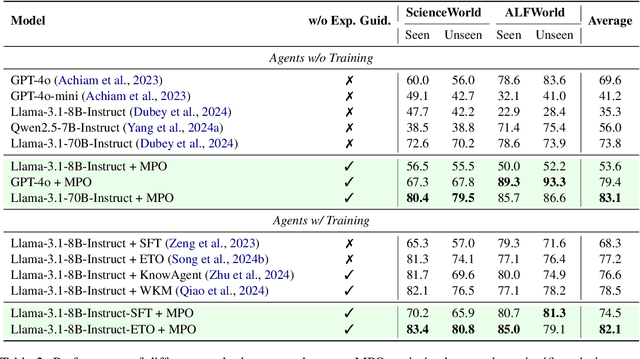
Recent advancements in large language models (LLMs) have enabled LLM-based agents to successfully tackle interactive planning tasks. However, despite their successes, existing approaches often suffer from planning hallucinations and require retraining for each new agent. To address these challenges, we propose the Meta Plan Optimization (MPO) framework, which enhances agent planning capabilities by directly incorporating explicit guidance. Unlike previous methods that rely on complex knowledge, which either require significant human effort or lack quality assurance, MPO leverages high-level general guidance through meta plans to assist agent planning and enables continuous optimization of the meta plans based on feedback from the agent's task execution. Our experiments conducted on two representative tasks demonstrate that MPO significantly outperforms existing baselines. Moreover, our analysis indicates that MPO provides a plug-and-play solution that enhances both task completion efficiency and generalization capabilities in previous unseen scenarios.
AgentBank: Towards Generalized LLM Agents via Fine-Tuning on 50000+ Interaction Trajectories
Oct 10, 2024



Fine-tuning on agent-environment interaction trajectory data holds significant promise for surfacing generalized agent capabilities in open-source large language models (LLMs). In this work, we introduce AgentBank, by far the largest trajectory tuning data collection featuring more than 50k diverse high-quality interaction trajectories which comprises 16 tasks covering five distinct agent skill dimensions. Leveraging a novel annotation pipeline, we are able to scale the annotated trajectories and generate a trajectory dataset with minimized difficulty bias. Furthermore, we fine-tune LLMs on AgentBank to get a series of agent models, Samoyed. Our comparative experiments demonstrate the effectiveness of scaling the interaction trajectory data to acquire generalized agent capabilities. Additional studies also reveal some key observations regarding trajectory tuning and agent skill generalization.
Reconstruction-based Multi-Normal Prototypes Learning for Weakly Supervised Anomaly Detection
Aug 23, 2024
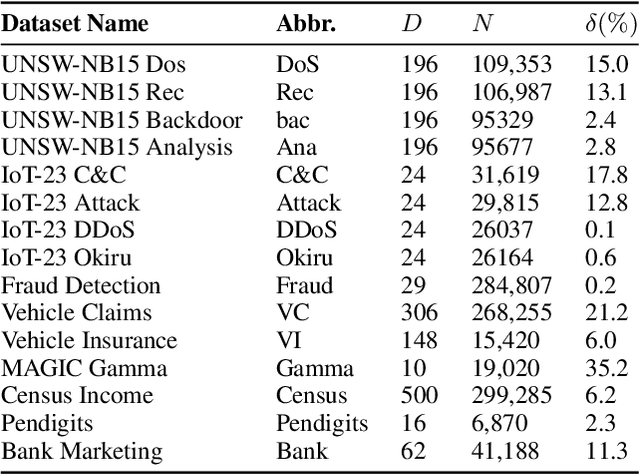

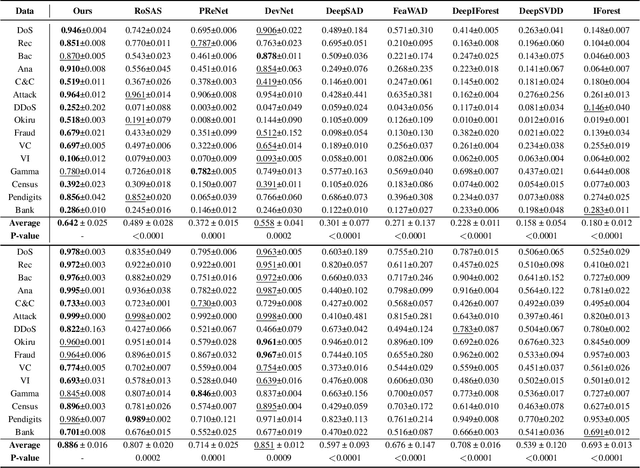
Anomaly detection is a crucial task in various domains. Most of the existing methods assume the normal sample data clusters around a single central prototype while the real data may consist of multiple categories or subgroups. In addition, existing methods always assume all unlabeled data are normal while they inevitably contain some anomalous samples. To address these issues, we propose a reconstruction-based multi-normal prototypes learning framework that leverages limited labeled anomalies in conjunction with abundant unlabeled data for anomaly detection. Specifically, we assume the normal sample data may satisfy multi-modal distribution, and utilize deep embedding clustering and contrastive learning to learn multiple normal prototypes to represent it. Additionally, we estimate the likelihood of each unlabeled sample being normal based on the multi-normal prototypes, guiding the training process to mitigate the impact of contaminated anomalies in the unlabeled data. Extensive experiments on various datasets demonstrate the superior performance of our method compared to state-of-the-art techniques.
EERPD: Leveraging Emotion and Emotion Regulation for Improving Personality Detection
Jun 23, 2024
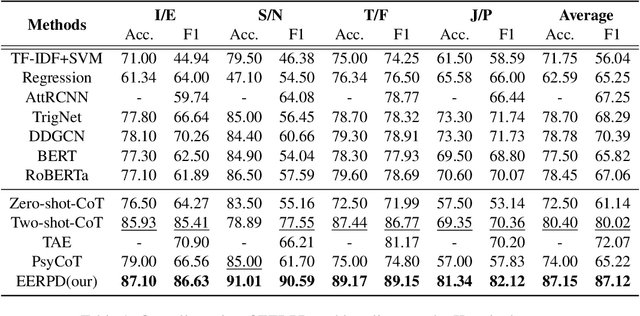
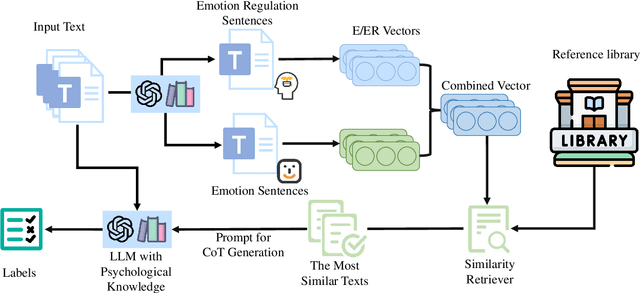
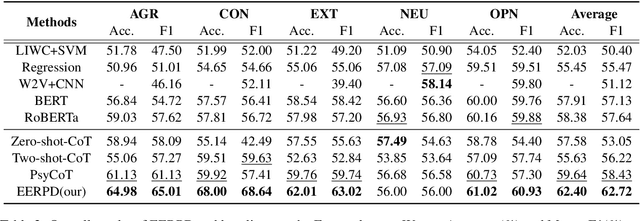
Personality is a fundamental construct in psychology, reflecting an individual's behavior, thinking, and emotional patterns. Previous researches have made some progress in personality detection, primarily by utilizing the whole text to predict personality. However, these studies generally tend to overlook psychological knowledge: they rarely apply the well-established correlations between emotion regulation and personality. Based on this, we propose a new personality detection method called EERPD. This method introduces the use of emotion regulation, a psychological concept highly correlated with personality, for personality prediction. By combining this feature with emotion features, it retrieves few-shot examples and provides process CoTs for inferring labels from text. This approach enhances the understanding of LLM for personality within text and improves the performance in personality detection. Experimental results demonstrate that EERPD significantly enhances the accuracy and robustness of personality detection, outperforming previous SOTA by 15.05/4.29 in average F1 on the two benchmark datasets.