 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuron-Level Emotion Control in Speech-Generative Large Audio-Language Models
Mar 18, 2026Large audio-language models (LALMs) can produce expressive speech, yet reliable emotion control remains elusive: conversions often miss the target affect and may degrade linguistic fidelity through refusals, hallucinations, or paraphrase. We present, to our knowledge, the first neuron-level study of emotion control in speech-generative LALMs and demonstrate that compact emotion-sensitive neurons (ESNs) are causally actionable, enabling training-free emotion steering at inference time. ESNs are identified via success-filtered activation aggregation enforcing both emotion realization and content preservation. Across three LALMs (Qwen2.5-Omni-7B, MiniCPM-o 4.5, Kimi-Audio), ESN interventions yield emotion-specific gains that generalize to unseen speakers and are supported by automatic and human evaluation. Controllability depends on selector design, mask sparsity, filtering, and intervention strength. Our results establish a mechanistic framework for training-free emotion control in speech generation.
Discovering and Causally Validating Emotion-Sensitive Neurons in Large Audio-Language Models
Jan 06, 2026Emotion is a central dimension of spoken communication, yet, we still lack a mechanistic account of how modern large audio-language models (LALMs) encode it internally. We present the first neuron-level interpretability study of emotion-sensitive neurons (ESNs) in LALMs and provide causal evidence that such units exist in Qwen2.5-Omni, Kimi-Audio, and Audio Flamingo 3. Across these three widely used open-source models, we compare frequency-, entropy-, magnitude-, and contrast-based neuron selectors on multiple emotion recognition benchmarks. Using inference-time interventions, we reveal a consistent emotion-specific signature: ablating neurons selected for a given emotion disproportionately degrades recognition of that emotion while largely preserving other classes, whereas gain-based amplification steers predictions toward the target emotion. These effects arise with modest identification data and scale systematically with intervention strength. We further observe that ESNs exhibit non-uniform layer-wise clustering with partial cross-dataset transfer. Taken together, our results offer a causal, neuron-level account of emotion decisions in LALMs and highlight targeted neuron interventions as an actionable handle for controllable affective behaviors.
An Electoral Approach to Diversify LLM-based Multi-Agent Collective Decision-Making
Oct 19, 2024



Modern large language models (LLMs) have exhibited cooperative synergy on complex task-solving, and collective decision-making (CDM) is a pivotal component in LLM-based multi-agent collaboration frameworks. Our survey on 52 recent such systems uncovers a severe lack of diversity, with a heavy reliance on dictatorial and plurality voting for CDM. Through the lens of social choice theory, we scrutinize widely-adopted CDM methods and identify their limitations. To enrich current landscape of LLM-based CDM, we present GEDI, an electoral CDM module that incorporates various ordinal preferential voting mechanisms. Our empirical case study across three benchmarks shows that the integration of certain CDM methods can markedly improve the reasoning capabilities and robustness of some leading LLMs, all without requiring intricate system designs. Additionally, we find that some CDM mechanisms generate positive synergies even with as few as three agents. The voting-based methods also demonstrate robustness against single points of failure, as well as diversity in terms of hit-rate@k and subject-wise impacts.
ORCHID: A Chinese Debate Corpus for Target-Independent Stance Detection and Argumentative Dialogue Summarization
Oct 17, 2024



Dialogue agents have been receiving increasing attention for years, and this trend has been further boosted by the recent progress of large language models (LLMs). Stance detection and dialogue summarization are two core tasks of dialogue agents in application scenarios that involve argumentative dialogues. However, research on these tasks is limited by the insufficiency of public datasets, especially for non-English languages. To address this language resource gap in Chinese, we present ORCHID (Oral Chinese Debate), the first Chinese dataset for benchmarking target-independent stance detection and debate summarization. Our dataset consists of 1,218 real-world debates that were conducted in Chinese on 476 unique topics, containing 2,436 stance-specific summaries and 14,133 fully annotated utterances. Besides providing a versatile testbed for future research, we also conduct an empirical study on the dataset and propose an integrated task. The results show the challenging nature of the dataset and suggest a potential of incorporating stance detection in summarization for argumentative dialogue.
Measuring the Inconsistency of Large Language Models in Preferential Ranking
Oct 11, 2024



Despite large language models' (LLMs) recent advancements, their bias and hallucination issues persist, and their ability to offer consistent preferential rankings remains underexplored. This study investigates the capacity of LLMs to provide consistent ordinal preferences, a crucial aspect in scenarios with dense decision space or lacking absolute answers. We introduce a formalization of consistency based on order theory, outlining criteria such as transitivity, asymmetry, reversibility, and independence from irrelevant alternatives. Our diagnostic experiments on selected state-of-the-art LLMs reveal their inability to meet these criteria, indicating a strong positional bias and poor transitivity, with preferences easily swayed by irrelevant alternatives. These findings highlight a significant inconsistency in LLM-generated preferential rankings, underscoring the need for further research to address these limitations.
AgentBank: Towards Generalized LLM Agents via Fine-Tuning on 50000+ Interaction Trajectories
Oct 10, 2024



Fine-tuning on agent-environment interaction trajectory data holds significant promise for surfacing generalized agent capabilities in open-source large language models (LLMs). In this work, we introduce AgentBank, by far the largest trajectory tuning data collection featuring more than 50k diverse high-quality interaction trajectories which comprises 16 tasks covering five distinct agent skill dimensions. Leveraging a novel annotation pipeline, we are able to scale the annotated trajectories and generate a trajectory dataset with minimized difficulty bias. Furthermore, we fine-tune LLMs on AgentBank to get a series of agent models, Samoyed. Our comparative experiments demonstrate the effectiveness of scaling the interaction trajectory data to acquire generalized agent capabilities. Additional studies also reveal some key observations regarding trajectory tuning and agent skill generalization.
Watch Every Step! LLM Agent Learning via Iterative Step-Level Process Refinement
Jun 17, 2024



Large language model agents have exhibited exceptional performance across a range of complex interactive tasks. Recent approaches have utilized tuning with expert trajectories to enhance agent performance, yet they primarily concentrate on outcome rewards, which may lead to errors or suboptimal actions due to the absence of process supervision signals. In this paper, we introduce the Iterative step-level Process Refinement (IPR) framework, which provides detailed step-by-step guidance to enhance agent training. Specifically, we adopt the Monte Carlo method to estimate step-level rewards. During each iteration, the agent explores along the expert trajectory and generates new actions. These actions are then evaluated against the corresponding step of expert trajectory using step-level rewards. Such comparison helps identify discrepancies, yielding contrastive action pairs that serve as training data for the agent. Our experiments on three complex agent tasks demonstrate that our framework outperforms a variety of strong baselines. Moreover, our analytical findings highlight the effectiveness of IPR in augmenting action efficiency and its applicability to diverse models.
A Survey on Hallucination in Large Vision-Language Models
Feb 01, 2024
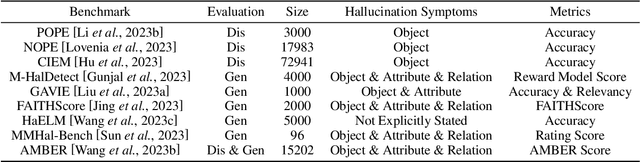
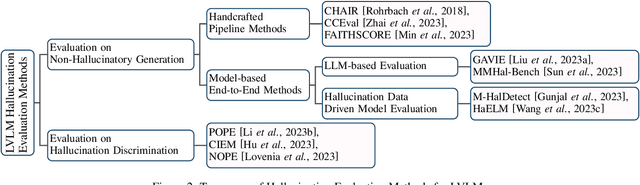
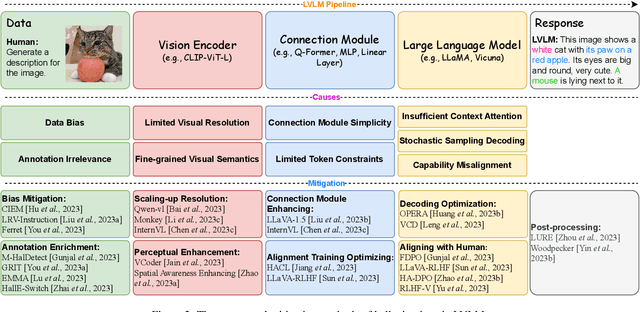
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.