 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenieDrive: Towards Physics-Aware Driving World Model with 4D Occupancy Guided Video Generation
Dec 14, 2025Physics-aware driving world model is essential for drive planning, out-of-distribution data synthesis, and closed-loop evaluation. However, existing methods often rely on a single diffusion model to directly map driving actions to videos, which makes learning difficult and leads to physically inconsistent outputs. To overcome these challenges, we propose GenieDrive, a novel framework designed for physics-aware driving video generation. Our approach starts by generating 4D occupancy, which serves as a physics-informed foundation for subsequent video generation. 4D occupancy contains rich physical information, including high-resolution 3D structures and dynamics. To facilitate effective compression of such high-resolution occupancy, we propose a VAE that encodes occupancy into a latent tri-plane representation, reducing the latent size to only 58% of that used in previous methods. We further introduce Mutual Control Attention (MCA) to accurately model the influence of control on occupancy evolution, and we jointly train the VAE and the subsequent prediction module in an end-to-end manner to maximize forecasting accuracy. Together, these designs yield a 7.2% improvement in forecasting mIoU at an inference speed of 41 FPS, while using only 3.47 M parameters. Additionally, a Normalized Multi-View Attention is introduced in the video generation model to generate multi-view driving videos with guidance from our 4D occupancy, significantly improving video quality with a 20.7% reduction in FVD. Experiments demonstrate that GenieDrive enables highly controllable, multi-view consistent, and physics-aware driving video generation.
Grounding Everything in Tokens for Multimodal Large Language Models
Dec 11, 2025Multimodal large language models (MLLMs) have made significant advancements in vision understanding and reasoning. However, the autoregressive Transformer architecture used by MLLMs requries tokenization on input images, which limits their ability to accurately ground objects within the 2D image space. This raises an important question: how can sequential language tokens be improved to better ground objects in 2D spatial space for MLLMs? To address this, we present a spatial representation method for grounding objects, namely GETok, that integrates a specialized vocabulary of learnable tokens into MLLMs. GETok first uses grid tokens to partition the image plane into structured spatial anchors, and then exploits offset tokens to enable precise and iterative refinement of localization predictions. By embedding spatial relationships directly into tokens, GETok significantly advances MLLMs in native 2D space reasoning without modifying the autoregressive architecture. Extensive experiments demonstrate that GETok achieves superior performance over the state-of-the-art methods across various referring tasks in both supervised fine-tuning and reinforcement learning settings.
A Survey on Hallucination in Large Vision-Language Models
Feb 01, 2024
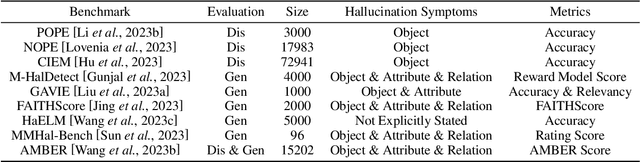
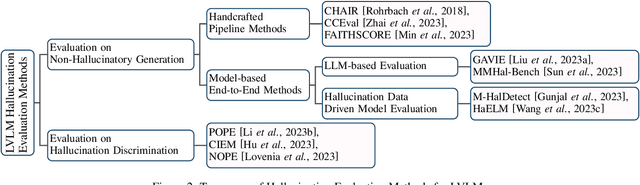
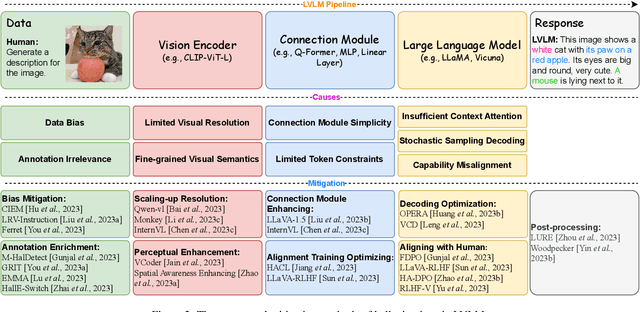
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
G-Rep: Gaussian Representation for Arbitrary-Oriented Object Detection
May 24, 2022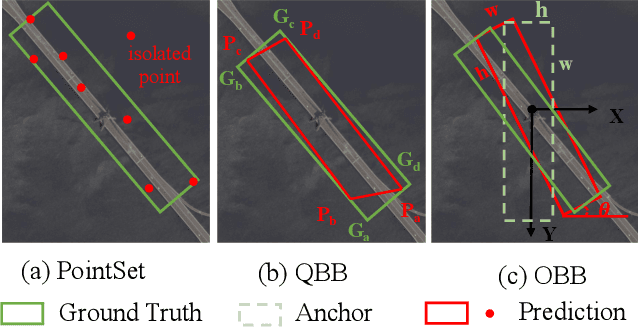

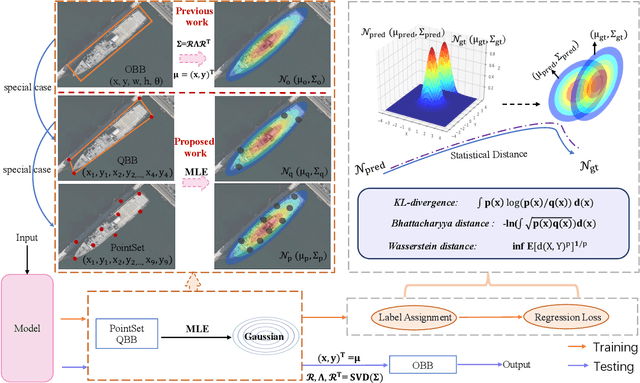

Arbitrary-oriented object representations contain the oriented bounding box (OBB), quadrilateral bounding box (QBB), and point set (PointSet). Each representation encounters problems that correspond to its characteristics, such as the boundary discontinuity, square-like problem, representation ambiguity, and isolated points, which lead to inaccurate detection. Although many effective strategies have been proposed for various representations, there is still no unified solution. Current detection methods based on Gaussian modeling have demonstrated the possibility of breaking this dilemma; however, they remain limited to OBB. To go further, in this paper, we propose a unified Gaussian representation called G-Rep to construct Gaussian distributions for OBB, QBB, and PointSet, which achieves a unified solution to various representations and problems. Specifically, PointSet or QBB-based objects are converted into Gaussian distributions, and their parameters are optimized using the maximum likelihood estimation algorithm. Then, three optional Gaussian metrics are explored to optimize the regression loss of the detector because of their excellent parameter optimization mechanisms. Furthermore, we also use Gaussian metrics for sampling to align label assignment and regression loss. Experimental results on several public available datasets, DOTA, HRSC2016, UCAS-AOD, and ICDAR2015 show the excellent performance of the proposed method for arbitrary-oriented object detection. The code has been open sourced at https://github.com/open-mmlab/mmrotate.
MMRotate: A Rotated Object Detection Benchmark using Pytorch
Apr 28, 2022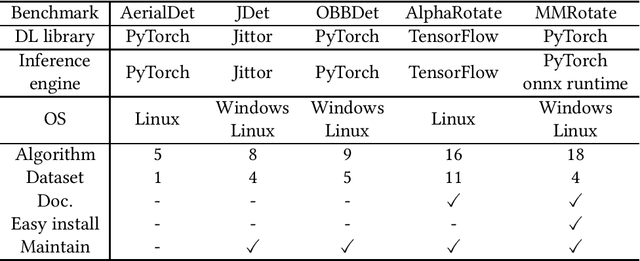
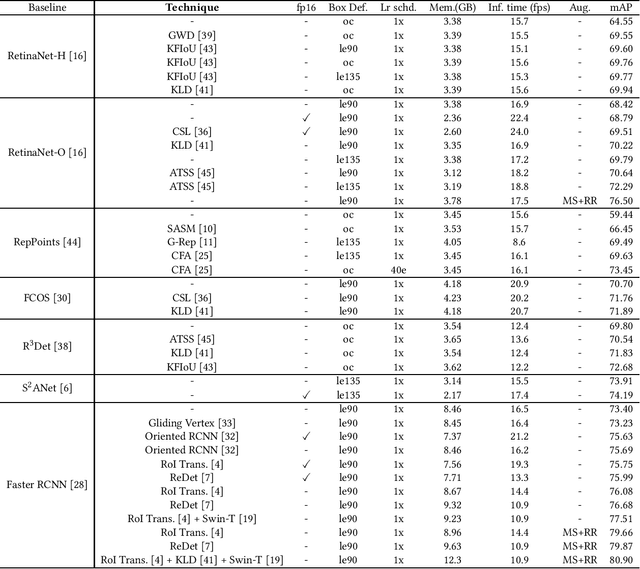
We present an open-source toolbox, named MMRotate, which provides a coherent algorithm framework of training, inferring, and evaluation for the popular rotated object detection algorithm based on deep learning. MMRotate implements 18 state-of-the-art algorithms and supports the three most frequently used angle definition methods. To facilitate future research and industrial applications of rotated object detection-related problems, we also provide a large number of trained models and detailed benchmarks to give insights into the performance of rotated object detection. MMRotate is publicly released at https://github.com/open-mmlab/mmrotate.
Dense Label Encoding for Boundary Discontinuity Free Rotation Detection
Nov 19, 2020


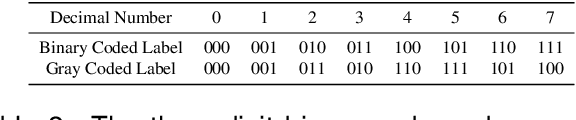
Rotation detection serves as a fundamental building block in many visual applications involving aerial image, scene text, and face etc. Differing from the dominant regression-based approaches for orientation estimation, this paper explores a relatively less-studied methodology based on classification. The hope is to inherently dismiss the boundary discontinuity issue as encountered by the regression-based detectors. We propose new techniques to push its frontier in two aspects: i) new encoding mechanism: the design of two Densely Coded Labels (DCL) for angle classification, to replace the Sparsely Coded Label (SCL) in existing classification-based detectors, leading to three times training speed increase as empirically observed across benchmarks, further with notable improvement in detection accuracy; ii) loss re-weighting: we propose Angle Distance and Aspect Ratio Sensitive Weighting (ADARSW), which improves the detection accuracy especially for square-like objects, by making DCL-based detectors sensitive to angular distance and object's aspect ratio. Extensive experiments and visual analysis on large-scale public datasets for aerial images i.e. DOTA, UCAS-AOD, HRSC2016, as well as scene text dataset ICDAR2015 and MLT, show the effectiveness of our approach. The source code is available at https://github.com/Thinklab-SJTU/DCL_RetinaNet_Tensorflow and is also integrated in our open source rotation detection benchmark: https://github.com/yangxue0827/RotationDetection.