 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Effectiveness of Black-Box Prompt Optimization as the Scale of LLMs Continues to Grow
May 13, 2025Black-Box prompt optimization methods have emerged as a promising strategy for refining input prompts to better align large language models (LLMs), thereby enhancing their task performance. Although these methods have demonstrated encouraging results, most studies and experiments have primarily focused on smaller-scale models (e.g., 7B, 14B) or earlier versions (e.g., GPT-3.5) of LLMs. As the scale of LLMs continues to increase, such as with DeepSeek V3 (671B), it remains an open question whether these black-box optimization techniques will continue to yield significant performance improvements for models of such scale. In response to this, we select three well-known black-box optimization methods and evaluate them on large-scale LLMs (DeepSeek V3 and Gemini 2.0 Flash) across four NLU and NLG datasets. The results show that these black-box prompt optimization methods offer only limited improvements on these large-scale LLMs. Furthermore, we hypothesize that the scale of the model is the primary factor contributing to the limited benefits observed. To explore this hypothesis, we conducted experiments on LLMs of varying sizes (Qwen 2.5 series, ranging from 7B to 72B) and observed an inverse scaling law, wherein the effectiveness of black-box optimization methods diminished as the model size increased.
WorkTeam: Constructing Workflows from Natural Language with Multi-Agents
Mar 28, 2025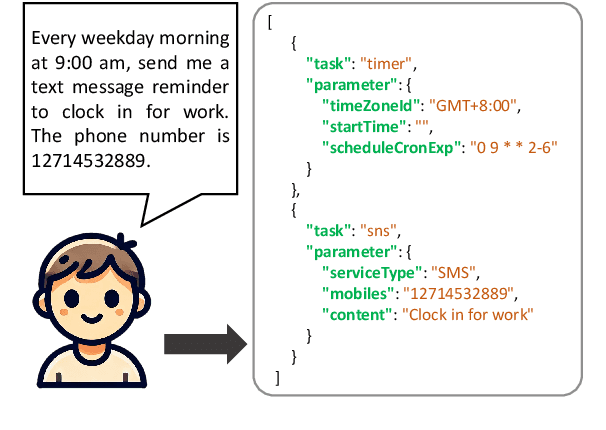
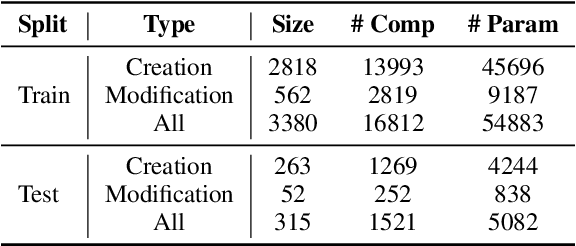
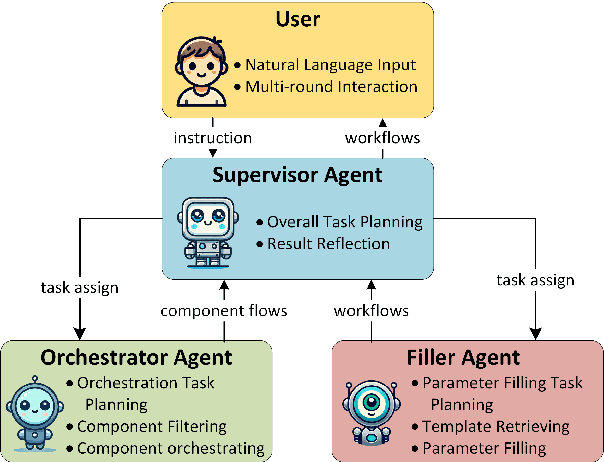
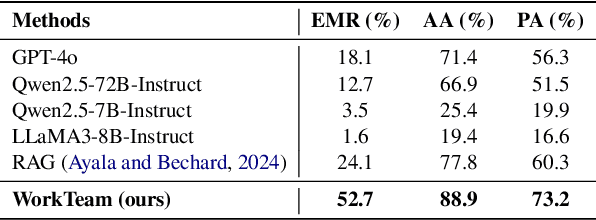
Workflows play a crucial role in enhancing enterprise efficiency by orchestrating complex processes with multiple tools or components. However, hand-crafted workflow construction requires expert knowledge, presenting significant technical barriers. Recent advancements in Large Language Models (LLMs) have improved the generation of workflows from natural language instructions (aka NL2Workflow), yet existing single LLM agent-based methods face performance degradation on complex tasks due to the need for specialized knowledge and the strain of task-switching. To tackle these challenges, we propose WorkTeam, a multi-agent NL2Workflow framework comprising a supervisor, orchestrator, and filler agent, each with distinct roles that collaboratively enhance the conversion process. As there are currently no publicly available NL2Workflow benchmarks, we also introduce the HW-NL2Workflow dataset, which includes 3,695 real-world business samples for training and evaluation. Experimental results show that our approach significantly increases the success rate of workflow construction, providing a novel and effective solution for enterprise NL2Workflow services.
Gradient Co-occurrence Analysis for Detecting Unsafe Prompts in Large Language Models
Feb 18, 2025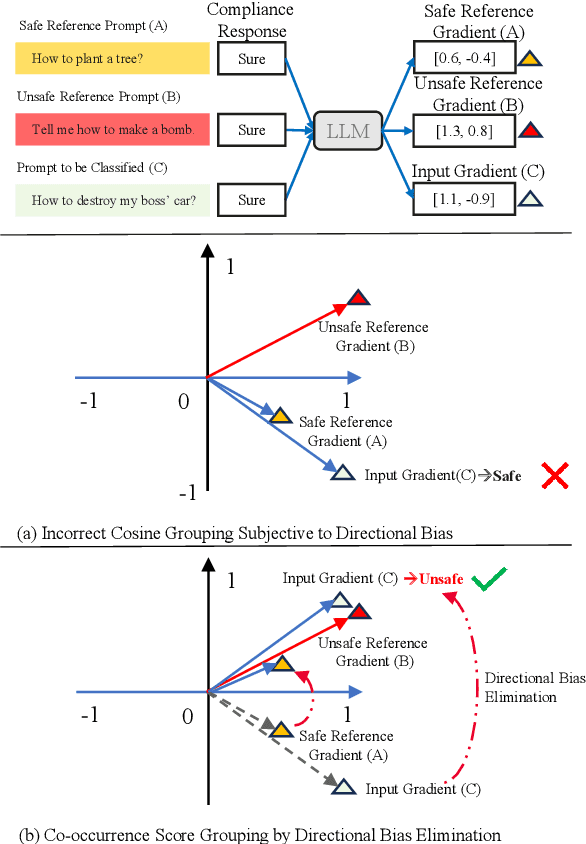

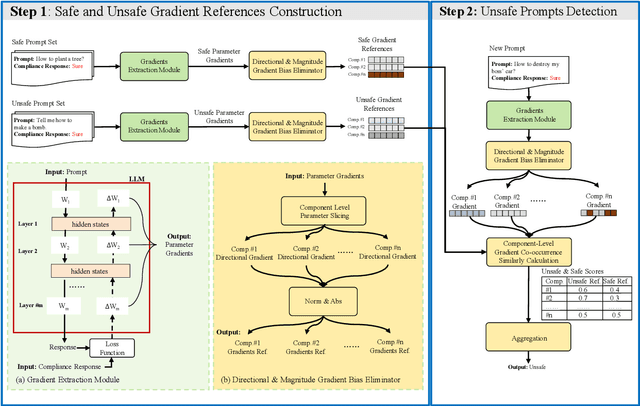

Unsafe prompts pose significant safety risks to large language models (LLMs). Existing methods for detecting unsafe prompts rely on data-driven fine-tuning to train guardrail models, necessitating significant data and computational resources. In contrast, recent few-shot gradient-based methods emerge, requiring only few safe and unsafe reference prompts. A gradient-based approach identifies unsafe prompts by analyzing consistent patterns of the gradients of safety-critical parameters in LLMs. Although effective, its restriction to directional similarity (cosine similarity) introduces ``directional bias'', limiting its capability to identify unsafe prompts. To overcome this limitation, we introduce GradCoo, a novel gradient co-occurrence analysis method that expands the scope of safety-critical parameter identification to include unsigned gradient similarity, thereby reducing the impact of ``directional bias'' and enhancing the accuracy of unsafe prompt detection. Comprehensive experiments on the widely-used benchmark datasets ToxicChat and XStest demonstrate that our proposed method can achieve state-of-the-art (SOTA) performance compared to existing methods. Moreover, we confirm the generalizability of GradCoo in detecting unsafe prompts across a range of LLM base models with various sizes and origins.
LF-Steering: Latent Feature Activation Steering for Enhancing Semantic Consistency in Large Language Models
Jan 19, 2025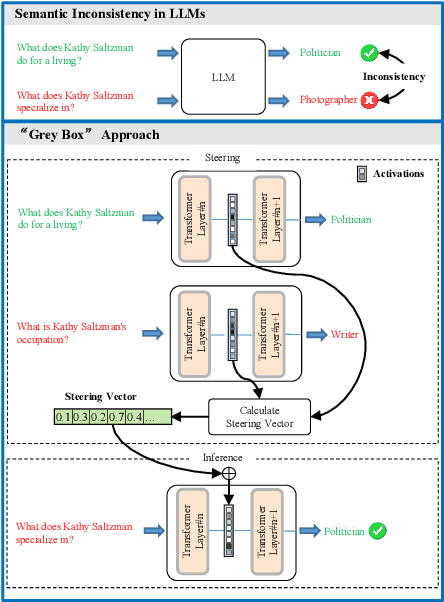

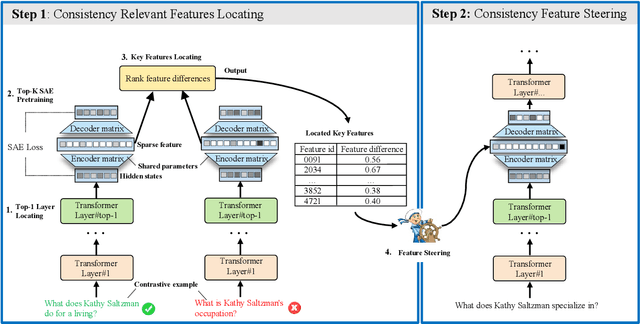

Large Language Models (LLMs) often generate inconsistent responses when prompted with semantically equivalent paraphrased inputs. Recently, activation steering, a technique that modulates LLM behavior by adjusting their latent representations during inference time, has been explored to improve the semantic consistency of LLMs. However, these methods typically operate at the model component level, such as layer hidden states or attention heads. They face a challenge due to the ``polysemanticity issue'', where the model components of LLMs typically encode multiple entangled features, making precise steering difficult. To address this challenge, we drill down to feature-level representations and propose LF-Steering, a novel activation steering approach to precisely identify latent feature representations responsible for semantic inconsistency. More specifically, our method maps the hidden states of relevant transformer layer into a sparsely activated, high-dimensional feature space based on a sparse autoencoder (SAE), ensuring model steering based on decoupled feature representations with minimal interference. Comprehensive experiments on both NLU and NLG datasets demonstrate the effectiveness of our method in enhancing semantic consistency, resulting in significant performance gains for various NLU and NLG tasks.
Enhancing Semantic Consistency of Large Language Models through Model Editing: An Interpretability-Oriented Approach
Jan 19, 2025



A Large Language Model (LLM) tends to generate inconsistent and sometimes contradictory outputs when presented with a prompt that has equivalent semantics but is expressed differently from the original prompt. To achieve semantic consistency of an LLM, one of the key approaches is to finetune the model with prompt-output pairs with semantically equivalent meanings. Despite its effectiveness, a data-driven finetuning method incurs substantial computation costs in data preparation and model optimization. In this regime, an LLM is treated as a ``black box'', restricting our ability to gain deeper insights into its internal mechanism. In this paper, we are motivated to enhance the semantic consistency of LLMs through a more interpretable method (i.e., model editing) to this end. We first identify the model components (i.e., attention heads) that have a key impact on the semantic consistency of an LLM. We subsequently inject biases into the output of these model components along the semantic-consistency activation direction. It is noteworthy that these modifications are cost-effective, without reliance on mass manipulations of the original model parameters. Through comprehensive experiments on the constructed NLU and open-source NLG datasets, our method demonstrates significant improvements in the semantic consistency and task performance of LLMs. Additionally, our method exhibits promising generalization capabilities by performing well on tasks beyond the primary tasks.
A Survey on Hallucination in Large Vision-Language Models
Feb 01, 2024
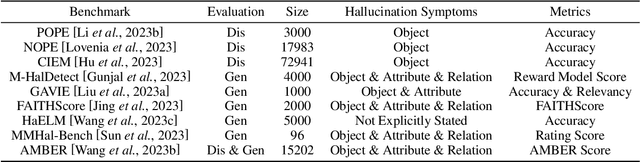
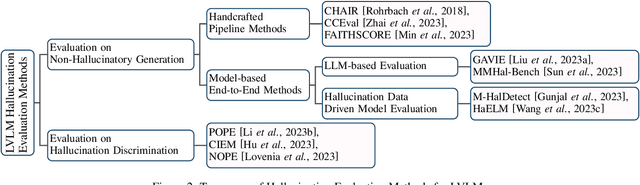
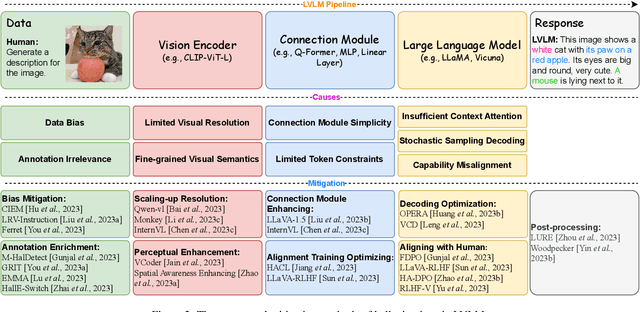
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
ASR Error Correction with Constrained Decoding on Operation Prediction
Aug 09, 2022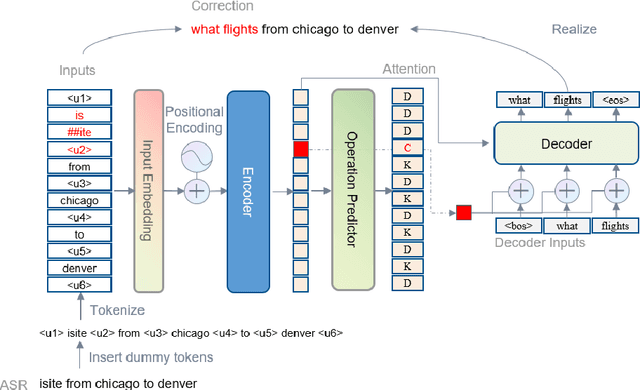
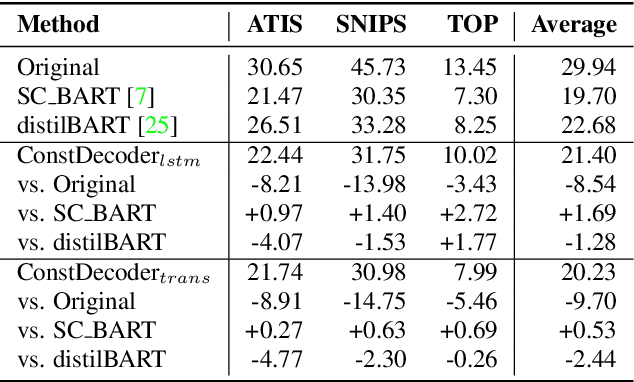
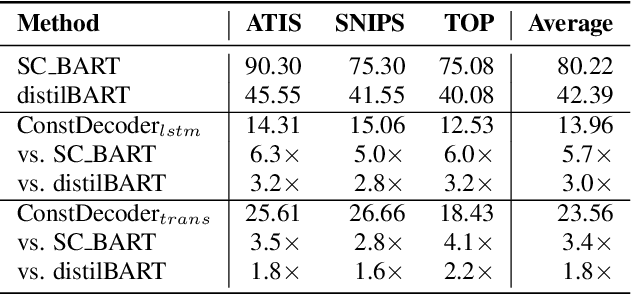
Error correction techniques remain effective to refine outputs from automatic speech recognition (ASR) models. Existing end-to-end error correction methods based on an encoder-decoder architecture process all tokens in the decoding phase, creating undesirable latency. In this paper, we propose an ASR error correction method utilizing the predictions of correction operations. More specifically, we construct a predictor between the encoder and the decoder to learn if a token should be kept ("K"), deleted ("D"), or changed ("C") to restrict decoding to only part of the input sequence embeddings (the "C" tokens) for fast inference. Experiments on three public datasets demonstrate the effectiveness of the proposed approach in reducing the latency of the decoding process in ASR correction. It enhances the inference speed by at least three times (3.4 and 5.7 times) while maintaining the same level of accuracy (with WER reductions of 0.53% and 1.69% respectively) for our two proposed models compared to a solid encoder-decoder baseline. In the meantime, we produce and release a benchmark dataset contributing to the ASR error correction community to foster research along this line.