 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelayGR: Scaling Long-Sequence Generative Recommendation via Cross-Stage Relay-Race Inference
Jan 05, 2026Real-time recommender systems execute multi-stage cascades (retrieval, pre-processing, fine-grained ranking) under strict tail-latency SLOs, leaving only tens of milliseconds for ranking. Generative recommendation (GR) models can improve quality by consuming long user-behavior sequences, but in production their online sequence length is tightly capped by the ranking-stage P99 budget. We observe that the majority of GR tokens encode user behaviors that are independent of the item candidates, suggesting an opportunity to pre-infer a user-behavior prefix once and reuse it during ranking rather than recomputing it on the critical path. Realizing this idea at industrial scale is non-trivial: the prefix cache must survive across multiple pipeline stages before the final ranking instance is determined, the user population implies cache footprints far beyond a single device, and indiscriminate pre-inference would overload shared resources under high QPS. We present RelayGR, a production system that enables in-HBM relay-race inference for GR. RelayGR selectively pre-infers long-term user prefixes, keeps their KV caches resident in HBM over the request lifecycle, and ensures the subsequent ranking can consume them without remote fetches. RelayGR combines three techniques: 1) a sequence-aware trigger that admits only at-risk requests under a bounded cache footprint and pre-inference load, 2) an affinity-aware router that co-locates cache production and consumption by routing both the auxiliary pre-infer signal and the ranking request to the same instance, and 3) a memory-aware expander that uses server-local DRAM to capture short-term cross-request reuse while avoiding redundant reloads. We implement RelayGR on Huawei Ascend NPUs and evaluate it with real queries. Under a fixed P99 SLO, RelayGR supports up to 1.5$\times$ longer sequences and improves SLO-compliant throughput by up to 3.6$\times$.
Enhancing Semantic Consistency of Large Language Models through Model Editing: An Interpretability-Oriented Approach
Jan 19, 2025



A Large Language Model (LLM) tends to generate inconsistent and sometimes contradictory outputs when presented with a prompt that has equivalent semantics but is expressed differently from the original prompt. To achieve semantic consistency of an LLM, one of the key approaches is to finetune the model with prompt-output pairs with semantically equivalent meanings. Despite its effectiveness, a data-driven finetuning method incurs substantial computation costs in data preparation and model optimization. In this regime, an LLM is treated as a ``black box'', restricting our ability to gain deeper insights into its internal mechanism. In this paper, we are motivated to enhance the semantic consistency of LLMs through a more interpretable method (i.e., model editing) to this end. We first identify the model components (i.e., attention heads) that have a key impact on the semantic consistency of an LLM. We subsequently inject biases into the output of these model components along the semantic-consistency activation direction. It is noteworthy that these modifications are cost-effective, without reliance on mass manipulations of the original model parameters. Through comprehensive experiments on the constructed NLU and open-source NLG datasets, our method demonstrates significant improvements in the semantic consistency and task performance of LLMs. Additionally, our method exhibits promising generalization capabilities by performing well on tasks beyond the primary tasks.
P/D-Serve: Serving Disaggregated Large Language Model at Scale
Aug 15, 2024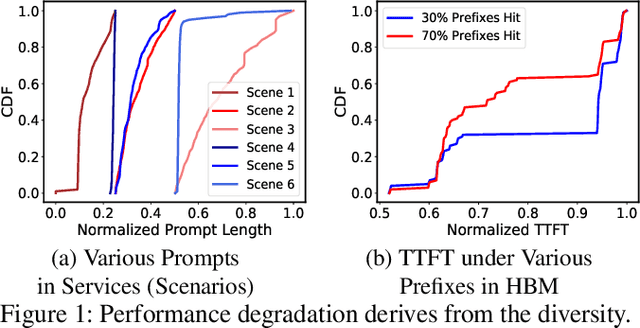
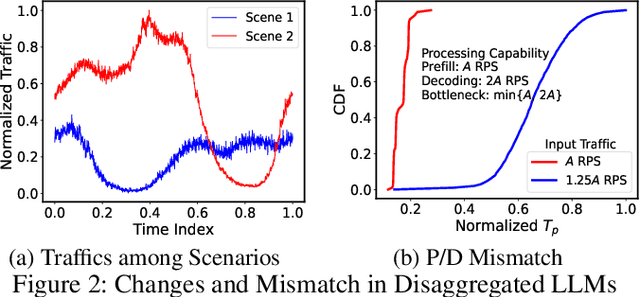
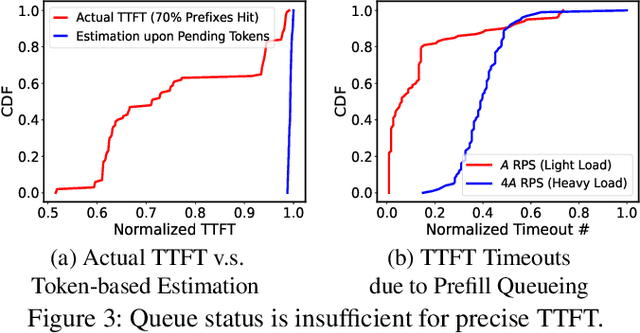
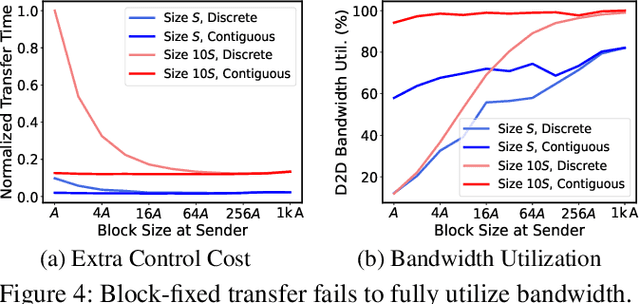
Serving disaggregated large language models (LLMs) over tens of thousands of xPU devices (GPUs or NPUs) with reliable performance faces multiple challenges. 1) Ignoring the diversity (various prefixes and tidal requests), treating all the prompts in a mixed pool is inadequate. To facilitate the similarity per scenario and minimize the inner mismatch on P/D (prefill and decoding) processing, fine-grained organization is required, dynamically adjusting P/D ratios for better performance. 2) Due to inaccurate estimation on workload (queue status or maintained connections), the global scheduler easily incurs unnecessary timeouts in prefill. 3) Block-fixed device-to-device (D2D) KVCache transfer over cluster-level RDMA (remote direct memory access) fails to achieve desired D2D utilization as expected. To overcome previous problems, this paper proposes an end-to-end system P/D-Serve, complying with the paradigm of MLOps (machine learning operations), which models end-to-end (E2E) P/D performance and enables: 1) fine-grained P/D organization, mapping the service with RoCE (RDMA over converged ethernet) as needed, to facilitate similar processing and dynamic adjustments on P/D ratios; 2) on-demand forwarding upon rejections for idle prefill, decoupling the scheduler from regular inaccurate reports and local queues, to avoid timeouts in prefill; and 3) efficient KVCache transfer via optimized D2D access. P/D-Serve is implemented upon Ascend and MindSpore, has been deployed over tens of thousands of NPUs for more than eight months in commercial use, and further achieves 60\%, 42\% and 46\% improvements on E2E throughput, time-to-first-token (TTFT) SLO (service level objective) and D2D transfer time. As the E2E system with optimizations, P/D-Serve achieves 6.7x increase on throughput, compared with aggregated LLMs.
Knowledge-augmented Frame Semantic Parsing with Hybrid Prompt-tuning
Mar 25, 2023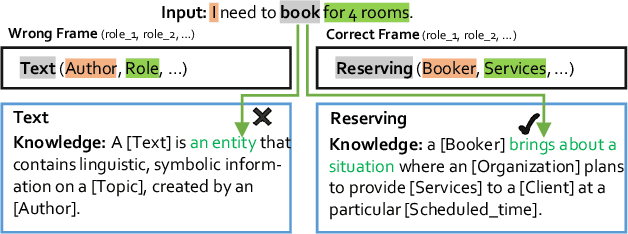
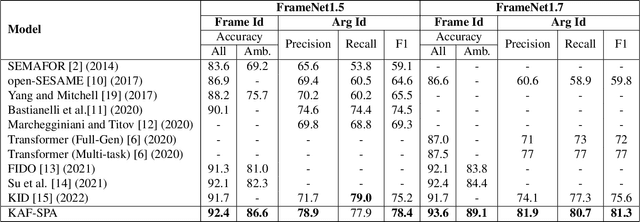
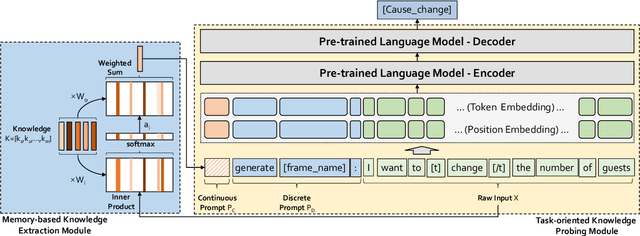
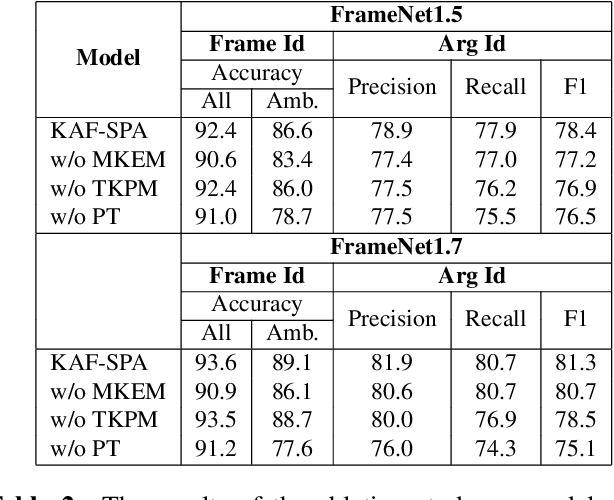
Frame semantics-based approaches have been widely used in semantic parsing tasks and have become mainstream. It remains challenging to disambiguate frame representations evoked by target lexical units under different contexts. Pre-trained Language Models (PLMs) have been used in semantic parsing and significantly improve the accuracy of neural parsers. However, the PLMs-based approaches tend to favor collocated patterns presented in the training data, leading to inaccurate outcomes. The intuition here is to design a mechanism to optimally use knowledge captured in semantic frames in conjunction with PLMs to disambiguate frames. We propose a novel Knowledge-Augmented Frame Semantic Parsing Architecture (KAF-SPA) to enhance semantic representation by incorporating accurate frame knowledge into PLMs during frame semantic parsing. Specifically, a Memory-based Knowledge Extraction Module (MKEM) is devised to select accurate frame knowledge and construct the continuous templates in the high dimensional vector space. Moreover, we design a Task-oriented Knowledge Probing Module (TKPM) using hybrid prompts (in terms of continuous and discrete prompts) to incorporate the selected knowledge into the PLMs and adapt PLMs to the tasks of frame and argument identification. Experimental results on two public FrameNet datasets demonstrate that our method significantly outperforms strong baselines (by more than +3$\%$ in F1), achieving state-of-art results on the current benchmark. Ablation studies verify the effectiveness of KAF-SPA.
Do You Know My Emotion? Emotion-Aware Strategy Recognition towards a Persuasive Dialogue System
Jun 24, 2022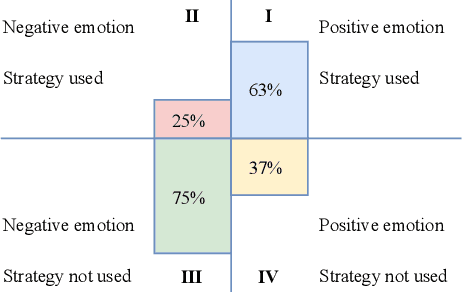
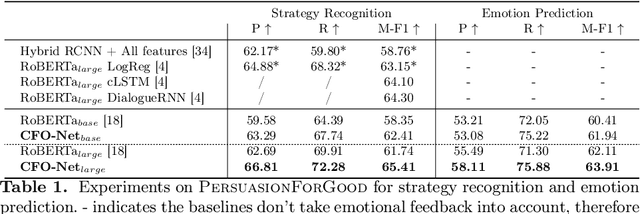
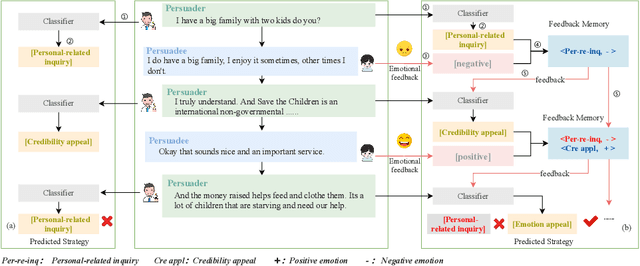

Persuasive strategy recognition task requires the system to recognize the adopted strategy of the persuader according to the conversation. However, previous methods mainly focus on the contextual information, little is known about incorporating the psychological feedback, i.e. emotion of the persuadee, to predict the strategy. In this paper, we propose a Cross-channel Feedback memOry Network (CFO-Net) to leverage the emotional feedback to iteratively measure the potential benefits of strategies and incorporate them into the contextual-aware dialogue information. Specifically, CFO-Net designs a feedback memory module, including strategy pool and feedback pool, to obtain emotion-aware strategy representation. The strategy pool aims to store historical strategies and the feedback pool is to obtain updated strategy weight based on feedback emotional information. Furthermore, a cross-channel fusion predictor is developed to make a mutual interaction between the emotion-aware strategy representation and the contextual-aware dialogue information for strategy recognition. Experimental results on \textsc{PersuasionForGood} confirm that the proposed model CFO-Net is effective to improve the performance on M-F1 from 61.74 to 65.41.
CogIntAc: Modeling the Relationships between Intention, Emotion and Action in Interactive Process from Cognitive Perspective
May 16, 2022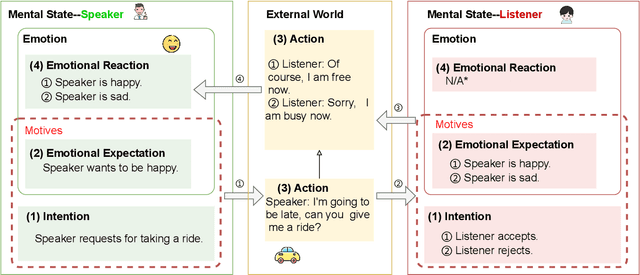
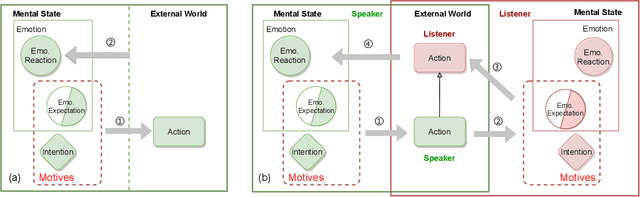
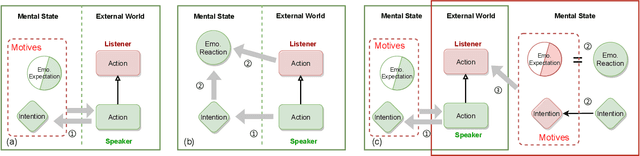
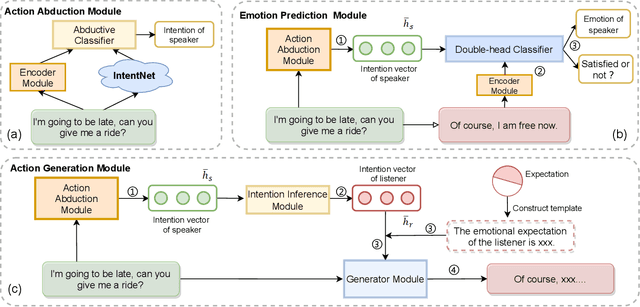
Intention, emotion and action are important psychological factors in human activities, which play an important role in the interaction between individuals. How to model the interaction process between individuals by analyzing the relationship of their intentions, emotions, and actions at the cognitive level is challenging. In this paper, we propose a novel cognitive framework of individual interaction. The core of the framework is that individuals achieve interaction through external action driven by their inner intention. Based on this idea, the interactions between individuals can be constructed by establishing relationships between the intention, emotion and action. Furthermore, we conduct analysis on the interaction between individuals and give a reasonable explanation for the predicting results. To verify the effectiveness of the framework, we reconstruct a dataset and propose three tasks as well as the corresponding baseline models, including action abduction, emotion prediction and action generation. The novel framework shows an interesting perspective on mimicking the mental state of human beings in cognitive science.
Control Globally, Understand Locally: A Global-to-Local Hierarchical Graph Network for Emotional Support Conversation
Apr 27, 2022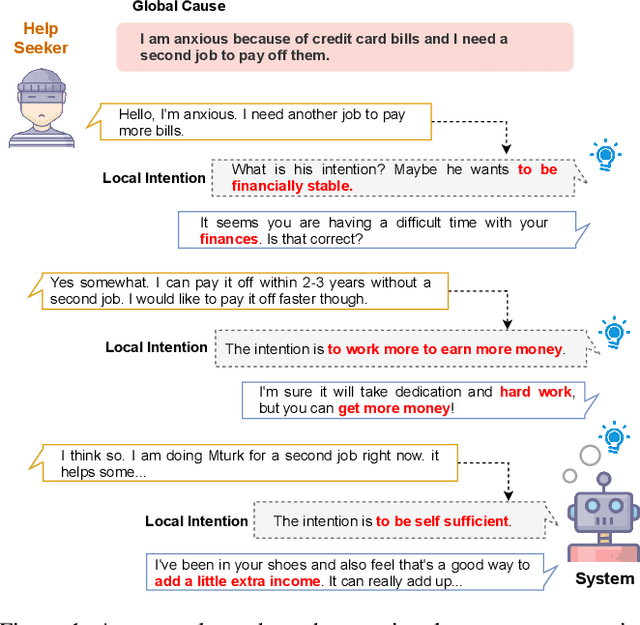
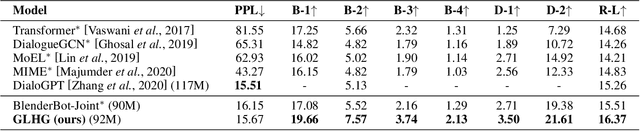
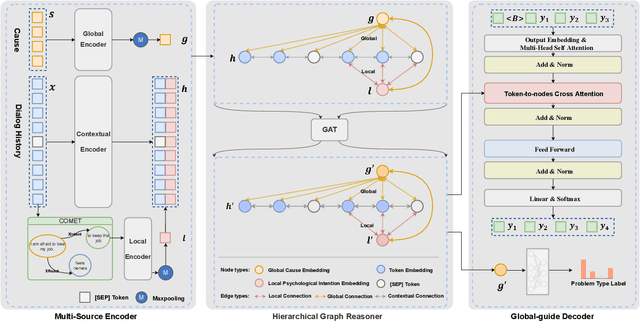
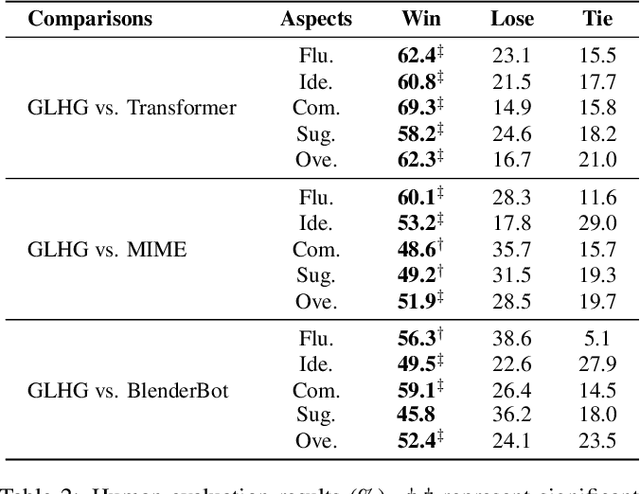
Emotional support conversation aims at reducing the emotional distress of the help-seeker, which is a new and challenging task. It requires the system to explore the cause of help-seeker's emotional distress and understand their psychological intention to provide supportive responses. However, existing methods mainly focus on the sequential contextual information, ignoring the hierarchical relationships with the global cause and local psychological intention behind conversations, thus leads to a weak ability of emotional support. In this paper, we propose a Global-to-Local Hierarchical Graph Network to capture the multi-source information (global cause, local intentions and dialog history) and model hierarchical relationships between them, which consists of a multi-source encoder, a hierarchical graph reasoner, and a global-guide decoder. Furthermore, a novel training objective is designed to monitor semantic information of the global cause. Experimental results on the emotional support conversation dataset, ESConv, confirm that the proposed GLHG has achieved the state-of-the-art performance on the automatic and human evaluations.
Modeling Intention, Emotion and External World in Dialogue Systems
Feb 14, 2022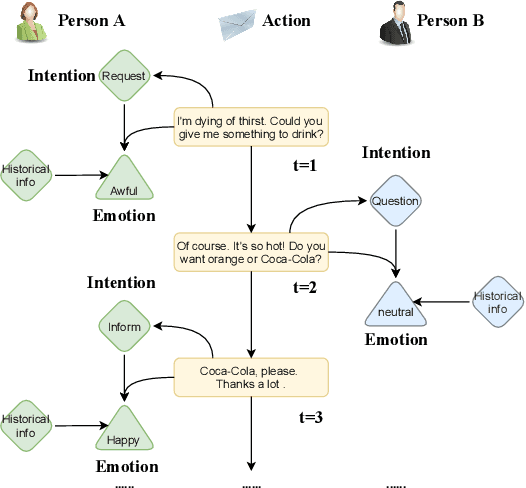
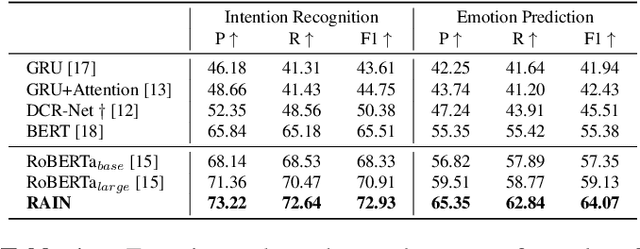
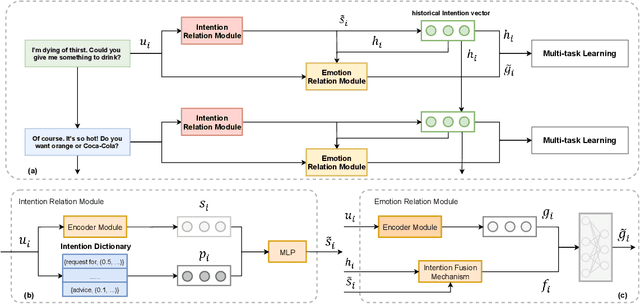
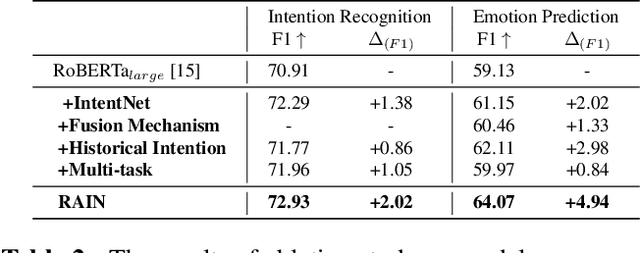
Intention, emotion and action are important elements in human activities. Modeling the interaction process between individuals by analyzing the relationships between these elements is a challenging task. However, previous work mainly focused on modeling intention and emotion independently, and neglected of exploring the mutual relationships between intention and emotion. In this paper, we propose a RelAtion Interaction Network (RAIN), consisting of Intention Relation Module and Emotion Relation Module, to jointly model mutual relationships and explicitly integrate historical intention information. The experiments on the dataset show that our model can take full advantage of the intention, emotion and action between individuals and achieve a remarkable improvement over BERT-style baselines. Qualitative analysis verifies the importance of the mutual interaction between the intention and emotion.
Know Deeper: Knowledge-Conversation Cyclic Utilization Mechanism for Open-domain Dialogue Generation
Jul 16, 2021
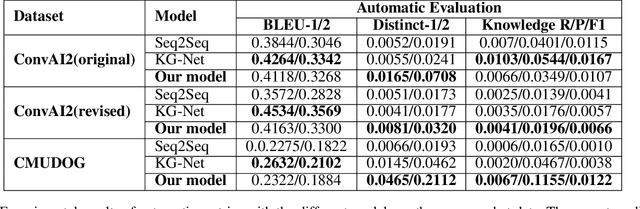
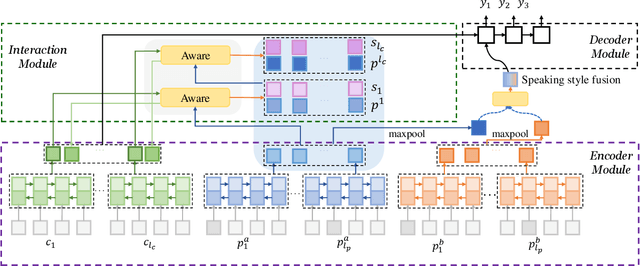
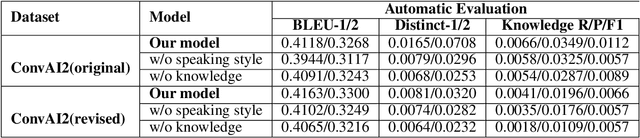
End-to-End intelligent neural dialogue systems suffer from the problems of generating inconsistent and repetitive responses. Existing dialogue models pay attention to unilaterally incorporating personal knowledge into the dialog while ignoring the fact that incorporating the personality-related conversation information into personal knowledge taken as the bilateral information flow boosts the quality of the subsequent conversation. Besides, it is indispensable to control personal knowledge utilization over the conversation level. In this paper, we propose a conversation-adaption multi-view persona aware response generation model that aims at enhancing conversation consistency and alleviating the repetition from two folds. First, we consider conversation consistency from multiple views. From the view of the persona profile, we design a novel interaction module that not only iteratively incorporates personalized knowledge into each turn conversation but also captures the personality-related information from conversation to enhance personalized knowledge semantic representation. From the view of speaking style, we introduce the speaking style vector and feed it into the decoder to keep the speaking style consistency. To avoid conversation repetition, we devise a coverage mechanism to keep track of the activation of personal knowledge utilization. Experiments on both automatic and human evaluation verify the superiority of our model over previous models.
MCR-Net: A Multi-Step Co-Interactive Relation Network for Unanswerable Questions on Machine Reading Comprehension
Mar 08, 2021
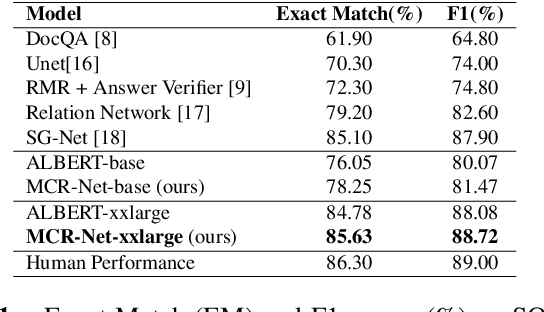
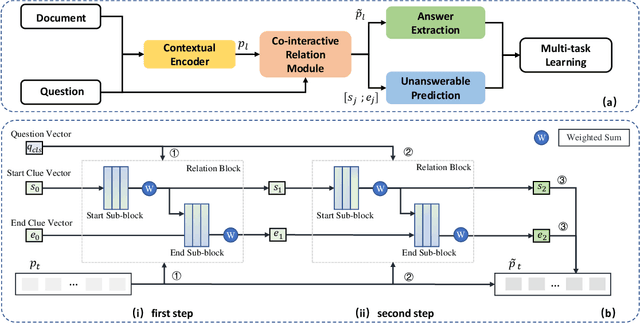
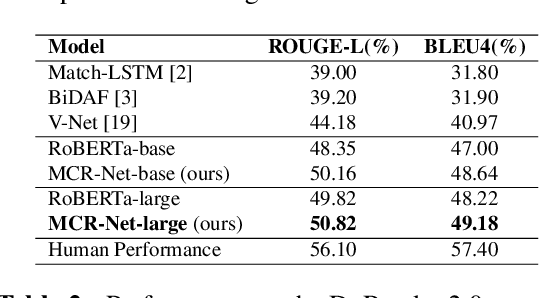
Question answering systems usually use keyword searches to retrieve potential passages related to a question, and then extract the answer from passages with the machine reading comprehension methods. However, many questions tend to be unanswerable in the real world. In this case, it is significant and challenging how the model determines when no answer is supported by the passage and abstains from answering. Most of the existing systems design a simple classifier to determine answerability implicitly without explicitly modeling mutual interaction and relation between the question and passage, leading to the poor performance for determining the unanswerable questions. To tackle this problem, we propose a Multi-Step Co-Interactive Relation Network (MCR-Net) to explicitly model the mutual interaction and locate key clues from coarse to fine by introducing a co-interactive relation module. The co-interactive relation module contains a stack of interaction and fusion blocks to continuously integrate and fuse history-guided and current-query-guided clues in an explicit way. Experiments on the SQuAD 2.0 and DuReader datasets show that our model achieves a remarkable improvement, outperforming the BERT-style baselines in literature. Visualization analysis also verifies the importance of the mutual interaction between the question and passage.