 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrating Probabilistic Object Detectors with Annotator Disagreement
May 23, 2026High degrees of disagreement among annotators can exist for ambiguous objects, e.g. in medical images, underscoring the challenges of establishing ground truth annotations in object detection tasks. Despite this, all existing object detectors implicitly require access to ground truth annotations for either training or evaluation. The fundamental questions we target are: How can we learn an object detector with multiple annotators' annotations but without objective ground truth annotations due to object ambiguity, and how can we enable the learned detector to express meaningful model predictive uncertainties in detecting ambiguous objects? To answer these questions, we present an interpretable approach to calibrate probabilistic object detectors, where the calibration goal is to align the class confidence and bounding box variance estimates to the annotators' annotation distribution. We introduce an efficient yet effective framework to calibrate probabilistic object detectors by designing four evaluation metrics to measure calibration errors regarding classification and localization, and proposing a train-time calibration and post-hoc calibrator, all without the need to access any ground truth. This framework is generalizable to many existing probabilistic object detectors, such as the YOLO families and two-stage detectors. Empirical results with real-world and synthetic datasets of medical and natural images demonstrate the superior performance of the proposed framework with three popular object detectors.
Efficient Learning of Deep State Space Models via Importance Smoothing
May 20, 2026Latent state space systems are ubiquitous in statistical modelling, arising naturally when a time series is observed through a noisy measurement function, however training deep state space models (DSSM) at scale remains difficult. Two largely distinct strategies and literatures have developed around the training of DSSMs. Firstly, auto-encoding DSSMs train generative DSSMs by optimising a variational lower bound. Secondly, DSSMs trained by back-propagating the outputs of a classical sequential Monte Carlo algorithm (SMC). Such approaches can train DSSMs for discriminative as well as generative tasks, however, due to the sequentiality of their forward pass, scale poorly on modern hardware. We propose a new training method \emph{parallel variational Monte Carlo} (PVMC) that bridges the gap between the paradigms, and can be used robustly to train DSSMs for both discriminative and generative tasks. Our method achieves state-of-the-art or better results on a set of baseline experiments and trains $10\times$ faster than the fastest competing SMC approach.
S^2tory: Story Spine Distillation for Movie Script Summarization
May 05, 2026Movie scripts pose a fundamental challenge for automatic summarization due to their non-linear, cross-cut narrative structure, which makes surface-level saliency methods ineffective at preserving core story progression. To address this, we introduce S^2tory (Story Spine Distillation), a narratology-grounded framework that leverages character development trajectories to identify plot nuclei, the essential events that drive the narrative forward, while filtering out peripheral satellite events that merely enrich atmosphere or emotion. Our Narrative Expert Agent (NEAgent) performs theory-constrained reasoning, whose distilled knowledge conditions a small model to identify plot nuclei. Another model then uses these plot nuclei to generate the summary. Experiments on the MovieSum dataset demonstrate state-of-the-art semantic fidelity at approximately 3.5x compression, and zero-shot evaluation on BookSum confirms strong out-of-domain generalization. Human evaluation further validates that narratological theory provides an indispensable foundation for modeling complex, non-linear narratives.
TSegAgent: Zero-Shot Tooth Segmentation via Geometry-Aware Vision-Language Agents
Mar 20, 2026Automatic tooth segmentation and identification from intra-oral scanned 3D models are fundamental problems in digital dentistry, yet most existing approaches rely on task-specific 3D neural networks trained with densely annotated datasets, resulting in high annotation cost and limited generalization to scans from unseen sources. Thus, we propose TSegAgent, which addresses these challenges by reformulating dental analysis as a zero-shot geometric reasoning problem rather than a purely data-driven recognition task. The key idea is to combine the representational capacity of general-purpose foundation models with explicit geometric inductive biases derived from dental anatomy. Instead of learning dental-specific features, the proposed framework leverages multi-view visual abstraction and geometry-grounded reasoning to infer tooth instances and identities without task-specific training. By explicitly encoding structural constraints such as dental arch organization and volumetric relationships, the method reduces uncertainty in ambiguous cases and mitigates overfitting to particular shape distributions. Experimental results demonstrate that this reasoning-oriented formulation enables accurate and reliable tooth segmentation and identification with low computational and annotation cost, while exhibiting strong generalization across diverse and previously unseen dental scans.
BioDCASE 2026 Challenge Baseline for Cross-Domain Mosquito Species Classification
Mar 20, 2026Mosquito-borne diseases affect more than one billion people each year and cause close to one million deaths. Traditional surveillance methods rely on traps and manual identification that are slow, labor-intensive, and difficult to scale. Audio-based mosquito monitoring offers a non-destructive, lower-cost, and more scalable complement to trap-based surveillance, but reliable species classification remains difficult under real-world recording conditions. Mosquito flight tones are narrow-band, often low in signal-to-noise ratio, and easily masked by background noise, and recordings for several epidemiologically relevant species remain limited, creating pronounced class imbalance. Variation across devices, environments, and collection protocols further increases the difficulty of robust classification. Such variation can cause models to rely on domain-specific recording artefacts rather than species-relevant acoustic cues, which makes transfer to new acquisition settings difficult. The BioDCASE 2026 Cross-Domain Mosquito Species Classification (CD-MSC) challenge is designed around this deployment problem by evaluating performance on both seen and unseen domains. This paper presents the official baseline system and evaluation pipeline as a simple, fully reproducible reference for the CD-MSC challenge task. The baseline uses log-mel features and a multitemporal resolution convolutional neural network (MTRCNN) with species and auxiliary domain outputs, together with complete training and test scripts. The baseline system performs strongly on seen domains but degrades markedly on unseen domains, showing that cross-domain generalisation, rather than within-domain recognition, is the central challenge for practical mosquito species classification from multi-source bioacoustic recordings.
DentalX: Context-Aware Dental Disease Detection with Radiographs
Jan 13, 2026Diagnosing dental diseases from radiographs is time-consuming and challenging due to the subtle nature of diagnostic evidence. Existing methods, which rely on object detection models designed for natural images with more distinct target patterns, struggle to detect dental diseases that present with far less visual support. To address this challenge, we propose {\bf DentalX}, a novel context-aware dental disease detection approach that leverages oral structure information to mitigate the visual ambiguity inherent in radiographs. Specifically, we introduce a structural context extraction module that learns an auxiliary task: semantic segmentation of dental anatomy. The module extracts meaningful structural context and integrates it into the primary disease detection task to enhance the detection of subtle dental diseases. Extensive experiments on a dedicated benchmark demonstrate that DentalX significantly outperforms prior methods in both tasks. This mutual benefit arises naturally during model optimization, as the correlation between the two tasks is effectively captured. Our code is available at https://github.com/zhiqin1998/DentYOLOX.
LitVISTA: A Benchmark for Narrative Orchestration in Literary Text
Jan 10, 2026Computational narrative analysis aims to capture rhythm, tension, and emotional dynamics in literary texts. Existing large language models can generate long stories but overly focus on causal coherence, neglecting the complex story arcs and orchestration inherent in human narratives. This creates a structural misalignment between model- and human-generated narratives. We propose VISTA Space, a high-dimensional representational framework for narrative orchestration that unifies human and model narrative perspectives. We further introduce LitVISTA, a structurally annotated benchmark grounded in literary texts, enabling systematic evaluation of models' narrative orchestration capabilities. We conduct oracle evaluations on a diverse selection of frontier LLMs, including GPT, Claude, Grok, and Gemini. Results reveal systematic deficiencies: existing models fail to construct a unified global narrative view, struggling to jointly capture narrative function and structure. Furthermore, even advanced thinking modes yield only limited gains for such literary narrative understanding.
Restrictive Hierarchical Semantic Segmentation for Stratified Tooth Layer Detection
Dec 22, 2025Accurate understanding of anatomical structures is essential for reliably staging certain dental diseases. A way of introducing this within semantic segmentation models is by utilising hierarchy-aware methodologies. However, existing hierarchy-aware segmentation methods largely encode anatomical structure through the loss functions, providing weak and indirect supervision. We introduce a general framework that embeds an explicit anatomical hierarchy into semantic segmentation by coupling a recurrent, level-wise prediction scheme with restrictive output heads and top-down feature conditioning. At each depth of the class tree, the backbone is re-run on the original image concatenated with logits from the previous level. Child class features are conditioned using Feature-wise Linear Modulation of their parent class probabilities, to modulate child feature spaces for fine grained detection. A probabilistic composition rule enforces consistency between parent and descendant classes. Hierarchical loss combines per-level class weighted Dice and cross entropy loss and a consistency term loss, ensuring parent predictions are the sum of their children. We validate our approach on our proposed dataset, TL-pano, containing 194 panoramic radiographs with dense instance and semantic segmentation annotations, of tooth layers and alveolar bone. Utilising UNet and HRNet as donor models across a 5-fold cross validation scheme, the hierarchical variants consistently increase IoU, Dice, and recall, particularly for fine-grained anatomies, and produce more anatomically coherent masks. However, hierarchical variants also demonstrated increased recall over precision, implying increased false positives. The results demonstrate that explicit hierarchical structuring improves both performance and clinical plausibility, especially in low data dental imaging regimes.
SpectroStream: A Versatile Neural Codec for General Audio
Aug 07, 2025We propose SpectroStream, a full-band multi-channel neural audio codec. Successor to the well-established SoundStream, SpectroStream extends its capability beyond 24 kHz monophonic audio and enables high-quality reconstruction of 48 kHz stereo music at bit rates of 4--16 kbps. This is accomplished with a new neural architecture that leverages audio representation in the time-frequency domain, which leads to better audio quality especially at higher sample rate. The model also uses a delayed-fusion strategy to handle multi-channel audio, which is crucial in balancing per-channel acoustic quality and cross-channel phase consistency.
Foundational Models for 3D Point Clouds: A Survey and Outlook
Jan 30, 2025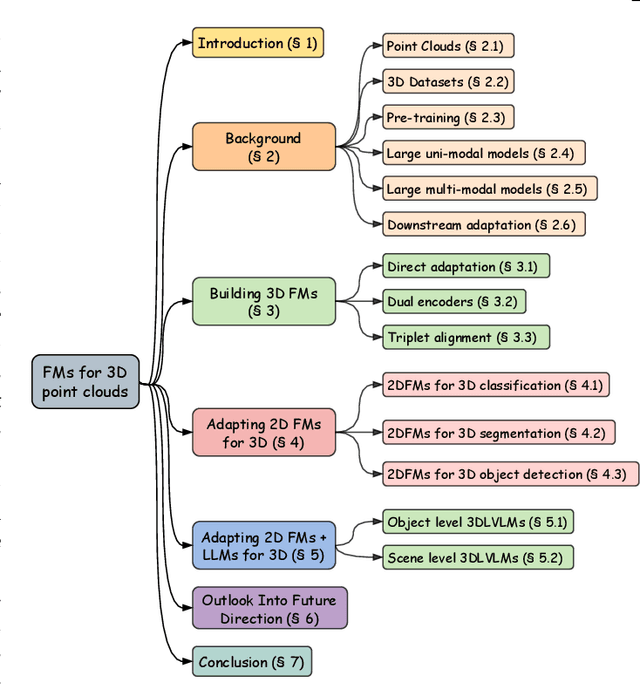
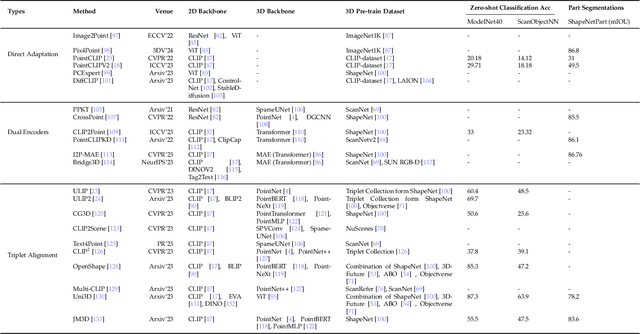
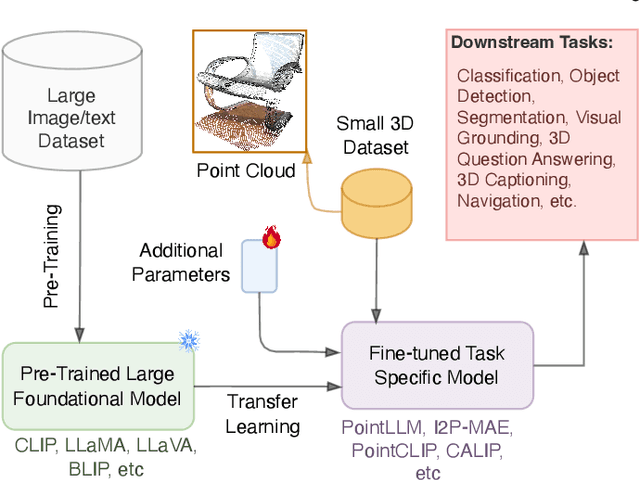

The 3D point cloud representation plays a crucial role in preserving the geometric fidelity of the physical world, enabling more accurate complex 3D environments. While humans naturally comprehend the intricate relationships between objects and variations through a multisensory system, artificial intelligence (AI) systems have yet to fully replicate this capacity. To bridge this gap, it becomes essential to incorporate multiple modalities. Models that can seamlessly integrate and reason across these modalities are known as foundation models (FMs). The development of FMs for 2D modalities, such as images and text, has seen significant progress, driven by the abundant availability of large-scale datasets. However, the 3D domain has lagged due to the scarcity of labelled data and high computational overheads. In response, recent research has begun to explore the potential of applying FMs to 3D tasks, overcoming these challenges by leveraging existing 2D knowledge. Additionally, language, with its capacity for abstract reasoning and description of the environment, offers a promising avenue for enhancing 3D understanding through large pre-trained language models (LLMs). Despite the rapid development and adoption of FMs for 3D vision tasks in recent years, there remains a gap in comprehensive and in-depth literature reviews. This article aims to address this gap by presenting a comprehensive overview of the state-of-the-art methods that utilize FMs for 3D visual understanding. We start by reviewing various strategies employed in the building of various 3D FMs. Then we categorize and summarize use of different FMs for tasks such as perception tasks. Finally, the article offers insights into future directions for research and development in this field. To help reader, we have curated list of relevant papers on the topic: https://github.com/vgthengane/Awesome-FMs-in-3D.