 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidence Should Be Calibrated More Than One Turn Deep
Apr 07, 2026Large Language Models (LLMs) are increasingly applied in high-stakes domains such as finance, healthcare, and education, where reliable multi-turn interactions with users are essential. However, existing work on confidence estimation and calibration, a major approach to building trustworthy LLM systems, largely focuses on single-turn settings and overlooks the risks and potential of multi-turn conversations. In this work, we introduce the task of multi-turn calibration to reframe calibration from a static property into a dynamic challenge central to reliable multi-turn conversation, where calibrating model confidence at each turn conditioned on the conversation history is required. We first reveal the risks of this setting: using Expected Calibration Error at turn T (ECE@T), a new metric that tracks calibration dynamics over turns, we show that user feedback (e.g., persuasion) can degrade multi-turn calibration. To address this, we propose MTCal, which minimises ECE@T via a surrogate calibration target, and further leverage calibrated confidence in ConfChat, a decoding strategy that improves both factuality and consistency of the model response in multi-turn interactions. Extensive experiments demonstrate that MT-Cal achieves outstanding and consistent performance in multi-turn calibration, and ConfChat preserves and even enhances model performance in multi-turn interactions. Our results mark multi-turn calibration as one missing link for scaling LLM calibration toward safe, reliable, and real-world use.
Relax Forcing: Relaxed KV-Memory for Consistent Long Video Generation
Mar 22, 2026Autoregressive (AR) video diffusion has recently emerged as a promising paradigm for long video generation, enabling causal synthesis beyond the limits of bidirectional models. To address training-inference mismatch, a series of self-forcing strategies have been proposed to improve rollout stability by conditioning the model on its own predictions during training. While these approaches substantially mitigate exposure bias, extending generation to minute-scale horizons remains challenging due to progressive temporal degradation. In this work, we show that this limitation is not primarily caused by insufficient memory, but by how temporal memory is utilised during inference. Through empirical analysis, we find that increasing memory does not consistently improve long-horizon generation, and that the temporal placement of historical context significantly influences motion dynamics while leaving visual quality largely unchanged. These findings suggest that temporal memory should not be treated as a homogeneous buffer. Motivated by this insight, we introduce Relax Forcing, a structured temporal memory mechanism for AR diffusion. Instead of attending to the dense generated history, Relax Forcing decomposes temporal context into three functional roles: Sink for global stability, Tail for short-term continuity, and dynamically selected History for structural motion guidance, and selectively incorporates only the most relevant past information. This design mitigates error accumulation during extrapolation while preserving motion evolution. Experiments on VBench-Long demonstrate that Relax Forcing improves motion dynamics and overall temporal consistency while reducing attention overhead. Our results suggest that structured temporal memory is essential for scalable long video generation, complementing existing forcing-based training strategies.
LatSearch: Latent Reward-Guided Search for Faster Inference-Time Scaling in Video Diffusion
Mar 15, 2026The recent success of inference-time scaling in large language models has inspired similar explorations in video diffusion. In particular, motivated by the existence of "golden noise" that enhances video quality, prior work has attempted to improve inference by optimising or searching for better initial noise. However, these approaches have notable limitations: they either rely on priors imposed at the beginning of noise sampling or on rewards evaluated only on the denoised and decoded videos. This leads to error accumulation, delayed and sparse reward signals, and prohibitive computational cost, which prevents the use of stronger search algorithms. Crucially, stronger search algorithms are precisely what could unlock substantial gains in controllability, sample efficiency and generation quality for video diffusion, provided their computational cost can be reduced. To fill in this gap, we enable efficient inference-time scaling for video diffusion through latent reward guidance, which provides intermediate, informative and efficient feedback along the denoising trajectory. We introduce a latent reward model that scores partially denoised latents at arbitrary timesteps with respect to visual quality, motion quality, and text alignment. Building on this model, we propose LatSearch, a novel inference-time search mechanism that performs Reward-Guided Resampling and Pruning (RGRP). In the resampling stage, candidates are sampled according to reward-normalised probabilities to reduce over-reliance on the reward model. In the pruning stage, applied at the final scheduled step, only the candidate with the highest cumulative reward is retained, improving both quality and efficiency. We evaluate LatSearch on the VBench-2.0 benchmark and demonstrate that it consistently improves video generation across multiple evaluation dimensions compared to the baseline Wan2.1 model.
GraphThinker: Reinforcing Video Reasoning with Event Graph Thinking
Feb 19, 2026Video reasoning requires understanding the causal relationships between events in a video. However, such relationships are often implicit and costly to annotate manually. While existing multimodal large language models (MLLMs) often infer event relations through dense captions or video summaries for video reasoning, such modeling still lacks causal understanding. Without explicit causal structure modeling within and across video events, these models suffer from hallucinations during the video reasoning. In this work, we propose GraphThinker, a reinforcement finetuning-based method that constructs structural event-level scene graphs and enhances visual grounding to jointly reduce hallucinations in video reasoning. Specifically, we first employ an MLLM to construct an event-based video scene graph (EVSG) that explicitly models both intra- and inter-event relations, and incorporate these formed scene graphs into the MLLM as an intermediate thinking process. We also introduce a visual attention reward during reinforcement finetuning, which strengthens video grounding and further mitigates hallucinations. We evaluate GraphThinker on two datasets, RexTime and VidHalluc, where it shows superior ability to capture object and event relations with more precise event localization, reducing hallucinations in video reasoning compared to prior methods.
ARM: A Learnable, Plug-and-Play Module for CLIP-based Open-vocabulary Semantic Segmentation
Dec 30, 2025Open-vocabulary semantic segmentation (OVSS) is fundamentally hampered by the coarse, image-level representations of CLIP, which lack precise pixel-level details. Existing training-free methods attempt to resolve this by either importing priors from costly external foundation models (e.g., SAM, DINO) or by applying static, hand-crafted heuristics to CLIP's internal features. These approaches are either computationally expensive or sub-optimal. We propose the Attention Refinement Module (ARM), a lightweight, learnable module that effectively unlocks and refines CLIP's internal potential. Unlike static-fusion methods, ARM learns to adaptively fuse hierarchical features. It employs a semantically-guided cross-attention block, using robust deep features (K, V) to select and refine detail-rich shallow features (Q), followed by a self-attention block. The key innovation lies in a ``train once, use anywhere" paradigm. Trained once on a general-purpose dataset (e.g., COCO-Stuff), ARM acts as a universal plug-and-play post-processor for diverse training-free frameworks. Extensive experiments show that ARM consistently boosts baseline performance on multiple benchmarks with negligible inference overhead, establishing an efficient and effective paradigm for training-free OVSS.
GrACE: A Generative Approach to Better Confidence Elicitation in Large Language Models
Sep 11, 2025Assessing the reliability of Large Language Models (LLMs) by confidence elicitation is a prominent approach to AI safety in high-stakes applications, such as healthcare and finance. Existing methods either require expensive computational overhead or suffer from poor calibration, making them impractical and unreliable for real-world deployment. In this work, we propose GrACE, a Generative Approach to Confidence Elicitation that enables scalable and reliable confidence elicitation for LLMs. GrACE adopts a novel mechanism in which the model expresses confidence by the similarity between the last hidden state and the embedding of a special token appended to the vocabulary, in real-time. We fine-tune the model for calibrating the confidence with calibration targets associated with accuracy. Experiments with three LLMs and two benchmark datasets show that the confidence produced by GrACE achieves the best discriminative capacity and calibration on open-ended generation tasks, outperforming six competing methods without resorting to additional sampling or an auxiliary model. Moreover, we propose two strategies for improving test-time scaling based on confidence induced by GrACE. Experimental results show that using GrACE not only improves the accuracy of the final decision but also significantly reduces the number of required samples in the test-time scaling scheme, indicating the potential of GrACE as a practical solution for deploying LLMs with scalable, reliable, and real-time confidence estimation.
Reinforcement Learning for Target Zone Blood Glucose Control
Aug 05, 2025Managing physiological variables within clinically safe target zones is a central challenge in healthcare, particularly for chronic conditions such as Type 1 Diabetes Mellitus (T1DM). Reinforcement learning (RL) offers promise for personalising treatment, but struggles with the delayed and heterogeneous effects of interventions. We propose a novel RL framework to study and support decision-making in T1DM technologies, such as automated insulin delivery. Our approach captures the complex temporal dynamics of treatment by unifying two control modalities: \textit{impulse control} for discrete, fast-acting interventions (e.g., insulin boluses), and \textit{switching control} for longer-acting treatments and regime shifts. The core of our method is a constrained Markov decision process augmented with physiological state features, enabling safe policy learning under clinical and resource constraints. The framework incorporates biologically realistic factors, including insulin decay, leading to policies that better reflect real-world therapeutic behaviour. While not intended for clinical deployment, this work establishes a foundation for future safe and temporally-aware RL in healthcare. We provide theoretical guarantees of convergence and demonstrate empirical improvements in a stylised T1DM control task, reducing blood glucose level violations from 22.4\% (state-of-the-art) to as low as 10.8\%.
Temporal Unlearnable Examples: Preventing Personal Video Data from Unauthorized Exploitation by Object Tracking
Jul 10, 2025With the rise of social media, vast amounts of user-uploaded videos (e.g., YouTube) are utilized as training data for Visual Object Tracking (VOT). However, the VOT community has largely overlooked video data-privacy issues, as many private videos have been collected and used for training commercial models without authorization. To alleviate these issues, this paper presents the first investigation on preventing personal video data from unauthorized exploitation by deep trackers. Existing methods for preventing unauthorized data use primarily focus on image-based tasks (e.g., image classification), directly applying them to videos reveals several limitations, including inefficiency, limited effectiveness, and poor generalizability. To address these issues, we propose a novel generative framework for generating Temporal Unlearnable Examples (TUEs), and whose efficient computation makes it scalable for usage on large-scale video datasets. The trackers trained w/ TUEs heavily rely on unlearnable noises for temporal matching, ignoring the original data structure and thus ensuring training video data-privacy. To enhance the effectiveness of TUEs, we introduce a temporal contrastive loss, which further corrupts the learning of existing trackers when using our TUEs for training. Extensive experiments demonstrate that our approach achieves state-of-the-art performance in video data-privacy protection, with strong transferability across VOT models, datasets, and temporal matching tasks.
Query-based Knowledge Transfer for Heterogeneous Learning Environments
Apr 12, 2025Decentralized collaborative learning under data heterogeneity and privacy constraints has rapidly advanced. However, existing solutions like federated learning, ensembles, and transfer learning, often fail to adequately serve the unique needs of clients, especially when local data representation is limited. To address this issue, we propose a novel framework called Query-based Knowledge Transfer (QKT) that enables tailored knowledge acquisition to fulfill specific client needs without direct data exchange. QKT employs a data-free masking strategy to facilitate communication-efficient query-focused knowledge transfer while refining task-specific parameters to mitigate knowledge interference and forgetting. Our experiments, conducted on both standard and clinical benchmarks, show that QKT significantly outperforms existing collaborative learning methods by an average of 20.91\% points in single-class query settings and an average of 14.32\% points in multi-class query scenarios. Further analysis and ablation studies reveal that QKT effectively balances the learning of new and existing knowledge, showing strong potential for its application in decentralized learning.
V-STaR: Benchmarking Video-LLMs on Video Spatio-Temporal Reasoning
Mar 14, 2025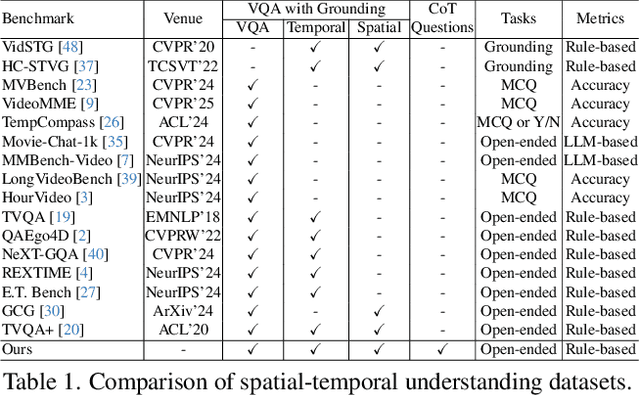
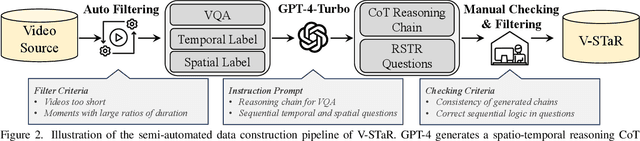

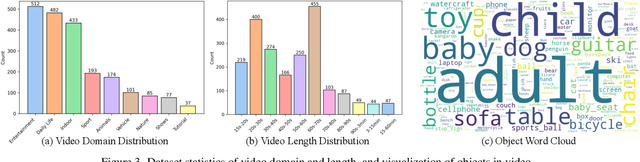
Human processes video reasoning in a sequential spatio-temporal reasoning logic, we first identify the relevant frames ("when") and then analyse the spatial relationships ("where") between key objects, and finally leverage these relationships to draw inferences ("what"). However, can Video Large Language Models (Video-LLMs) also "reason through a sequential spatio-temporal logic" in videos? Existing Video-LLM benchmarks primarily focus on assessing object presence, neglecting relational reasoning. Consequently, it is difficult to measure whether a model truly comprehends object interactions (actions/events) in videos or merely relies on pre-trained "memory" of co-occurrences as biases in generating answers. In this work, we introduce a Video Spatio-Temporal Reasoning (V-STaR) benchmark to address these shortcomings. The key idea is to decompose video understanding into a Reverse Spatio-Temporal Reasoning (RSTR) task that simultaneously evaluates what objects are present, when events occur, and where they are located while capturing the underlying Chain-of-thought (CoT) logic. To support this evaluation, we construct a dataset to elicit the spatial-temporal reasoning process of Video-LLMs. It contains coarse-to-fine CoT questions generated by a semi-automated GPT-4-powered pipeline, embedding explicit reasoning chains to mimic human cognition. Experiments from 14 Video-LLMs on our V-STaR reveal significant gaps between current Video-LLMs and the needs for robust and consistent spatio-temporal reasoning.