 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing the Failure of Ideal Noise Correction: A Three-Pillar Diagnosis
Mar 13, 2026Statistically consistent methods based on the noise transition matrix ($T$) offer a theoretically grounded solution to Learning with Noisy Labels (LNL), with guarantees of convergence to the optimal clean-data classifier. In practice, however, these methods are often outperformed by empirical approaches such as sample selection, and this gap is usually attributed to the difficulty of accurately estimating $T$. The common assumption is that, given a perfect $T$, noise-correction methods would recover their theoretical advantage. In this work, we put this longstanding hypothesis to a decisive test. We conduct experiments under idealized conditions, providing correction methods with a perfect, oracle transition matrix. Even under these ideal conditions, we observe that these methods still suffer from performance collapse during training. This compellingly demonstrates that the failure is not fundamentally a $T$-estimation problem, but stems from a more deeply rooted flaw. To explain this behaviour, we provide a unified analysis that links three levels: macroscopic convergence states, microscopic optimisation dynamics, and information-theoretic limits on what can be learned from noisy labels. Together, these results give a formal account of why ideal noise correction fails and offer concrete guidance for designing more reliable methods for learning with noisy labels.
VideoAgent2: Enhancing the LLM-Based Agent System for Long-Form Video Understanding by Uncertainty-Aware CoT
Apr 06, 2025Long video understanding has emerged as an increasingly important yet challenging task in computer vision. Agent-based approaches are gaining popularity for processing long videos, as they can handle extended sequences and integrate various tools to capture fine-grained information. However, existing methods still face several challenges: (1) they often rely solely on the reasoning ability of large language models (LLMs) without dedicated mechanisms to enhance reasoning in long video scenarios; and (2) they remain vulnerable to errors or noise from external tools. To address these issues, we propose a specialized chain-of-thought (CoT) process tailored for long video analysis. Our proposed CoT with plan-adjust mode enables the LLM to incrementally plan and adapt its information-gathering strategy. We further incorporate heuristic uncertainty estimation of both the LLM and external tools to guide the CoT process. This allows the LLM to assess the reliability of newly collected information, refine its collection strategy, and make more robust decisions when synthesizing final answers. Empirical experiments show that our uncertainty-aware CoT effectively mitigates noise from external tools, leading to more reliable outputs. We implement our approach in a system called VideoAgent2, which also includes additional modules such as general context acquisition and specialized tool design. Evaluation on three dedicated long video benchmarks (and their subsets) demonstrates that VideoAgent2 outperforms the previous state-of-the-art agent-based method, VideoAgent, by an average of 13.1% and achieves leading performance among all zero-shot approaches
Seeing and Reasoning with Confidence: Supercharging Multimodal LLMs with an Uncertainty-Aware Agentic Framework
Mar 11, 2025Multimodal large language models (MLLMs) show promise in tasks like visual question answering (VQA) but still face challenges in multimodal reasoning. Recent works adapt agentic frameworks or chain-of-thought (CoT) reasoning to improve performance. However, CoT-based multimodal reasoning often demands costly data annotation and fine-tuning, while agentic approaches relying on external tools risk introducing unreliable output from these tools. In this paper, we propose Seeing and Reasoning with Confidence (SRICE), a training-free multimodal reasoning framework that integrates external vision models with uncertainty quantification (UQ) into an MLLM to address these challenges. Specifically, SRICE guides the inference process by allowing MLLM to autonomously select regions of interest through multi-stage interactions with the help of external tools. We propose to use a conformal prediction-based approach to calibrate the output of external tools and select the optimal tool by estimating the uncertainty of an MLLM's output. Our experiment shows that the average improvement of SRICE over the base MLLM is 4.6% on five datasets and the performance on some datasets even outperforms fine-tuning-based methods, revealing the significance of ensuring reliable tool use in an MLLM agent.
Deep Learning-Based Noninvasive Screening of Type 2 Diabetes with Chest X-ray Images and Electronic Health Records
Dec 14, 2024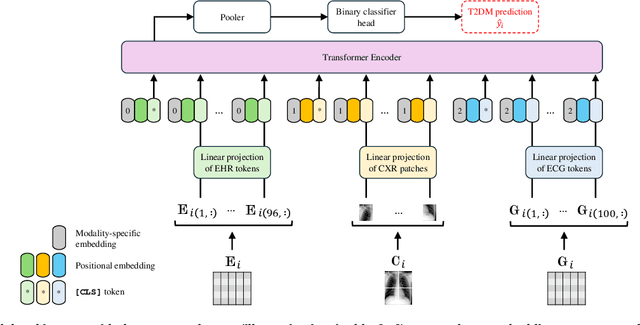



The imperative for early detection of type 2 diabetes mellitus (T2DM) is challenged by its asymptomatic onset and dependence on suboptimal clinical diagnostic tests, contributing to its widespread global prevalence. While research into noninvasive T2DM screening tools has advanced, conventional machine learning approaches remain limited to unimodal inputs due to extensive feature engineering requirements. In contrast, deep learning models can leverage multimodal data for a more holistic understanding of patients' health conditions. However, the potential of chest X-ray (CXR) imaging, one of the most commonly performed medical procedures, remains underexplored. This study evaluates the integration of CXR images with other noninvasive data sources, including electronic health records (EHRs) and electrocardiography signals, for T2DM detection. Utilising datasets meticulously compiled from the MIMIC-IV databases, we investigated two deep fusion paradigms: an early fusion-based multimodal transformer and a modular joint fusion ResNet-LSTM architecture. The end-to-end trained ResNet-LSTM model achieved an AUROC of 0.86, surpassing the CXR-only baseline by 2.3% with just 9863 training samples. These findings demonstrate the diagnostic value of CXRs within multimodal frameworks for identifying at-risk individuals early. Additionally, the dataset preprocessing pipeline has also been released to support further research in this domain.
Borrowing Treasures from Neighbors: In-Context Learning for Multimodal Learning with Missing Modalities and Data Scarcity
Mar 26, 2024Multimodal machine learning with missing modalities is an increasingly relevant challenge arising in various applications such as healthcare. This paper extends the current research into missing modalities to the low-data regime, i.e., a downstream task has both missing modalities and limited sample size issues. This problem setting is particularly challenging and also practical as it is often expensive to get full-modality data and sufficient annotated training samples. We propose to use retrieval-augmented in-context learning to address these two crucial issues by unleashing the potential of a transformer's in-context learning ability. Diverging from existing methods, which primarily belong to the parametric paradigm and often require sufficient training samples, our work exploits the value of the available full-modality data, offering a novel perspective on resolving the challenge. The proposed data-dependent framework exhibits a higher degree of sample efficiency and is empirically demonstrated to enhance the classification model's performance on both full- and missing-modality data in the low-data regime across various multimodal learning tasks. When only 1% of the training data are available, our proposed method demonstrates an average improvement of 6.1% over a recent strong baseline across various datasets and missing states. Notably, our method also reduces the performance gap between full-modality and missing-modality data compared with the baseline.
PROSAC: Provably Safe Certification for Machine Learning Models under Adversarial Attacks
Feb 04, 2024It is widely known that state-of-the-art machine learning models, including vision and language models, can be seriously compromised by adversarial perturbations. It is therefore increasingly relevant to develop capabilities to certify their performance in the presence of the most effective adversarial attacks. Our paper offers a new approach to certify the performance of machine learning models in the presence of adversarial attacks with population level risk guarantees. In particular, we introduce the notion of $(\alpha,\zeta)$ machine learning model safety. We propose a hypothesis testing procedure, based on the availability of a calibration set, to derive statistical guarantees providing that the probability of declaring that the adversarial (population) risk of a machine learning model is less than $\alpha$ (i.e. the model is safe), while the model is in fact unsafe (i.e. the model adversarial population risk is higher than $\alpha$), is less than $\zeta$. We also propose Bayesian optimization algorithms to determine efficiently whether a machine learning model is $(\alpha,\zeta)$-safe in the presence of an adversarial attack, along with statistical guarantees. We apply our framework to a range of machine learning models including various sizes of vision Transformer (ViT) and ResNet models impaired by a variety of adversarial attacks, such as AutoAttack, SquareAttack and natural evolution strategy attack, to illustrate the operation of our approach. Importantly, we show that ViT's are generally more robust to adversarial attacks than ResNets, and ViT-large is more robust than smaller models. Our approach goes beyond existing empirical adversarial risk-based certification guarantees. It formulates rigorous (and provable) performance guarantees that can be used to satisfy regulatory requirements mandating the use of state-of-the-art technical tools.
HgbNet: predicting hemoglobin level/anemia degree from EHR data
Jan 22, 2024Anemia is a prevalent medical condition that typically requires invasive blood tests for diagnosis and monitoring. Electronic health records (EHRs) have emerged as valuable data sources for numerous medical studies. EHR-based hemoglobin level/anemia degree prediction is non-invasive and rapid but still faces some challenges due to the fact that EHR data is typically an irregular multivariate time series containing a significant number of missing values and irregular time intervals. To address these issues, we introduce HgbNet, a machine learning-based prediction model that emulates clinicians' decision-making processes for hemoglobin level/anemia degree prediction. The model incorporates a NanDense layer with a missing indicator to handle missing values and employs attention mechanisms to account for both local irregularity and global irregularity. We evaluate the proposed method using two real-world datasets across two use cases. In our first use case, we predict hemoglobin level/anemia degree at moment T+1 by utilizing records from moments prior to T+1. In our second use case, we integrate all historical records with additional selected test results at moment T+1 to predict hemoglobin level/anemia degree at the same moment, T+1. HgbNet outperforms the best baseline results across all datasets and use cases. These findings demonstrate the feasibility of estimating hemoglobin levels and anemia degree from EHR data, positioning HgbNet as an effective non-invasive anemia diagnosis solution that could potentially enhance the quality of life for millions of affected individuals worldwide. To our knowledge, HgbNet is the first machine learning model leveraging EHR data for hemoglobin level/anemia degree prediction.
Volctrans Parallel Corpus Filtering System for WMT 2020
Oct 27, 2020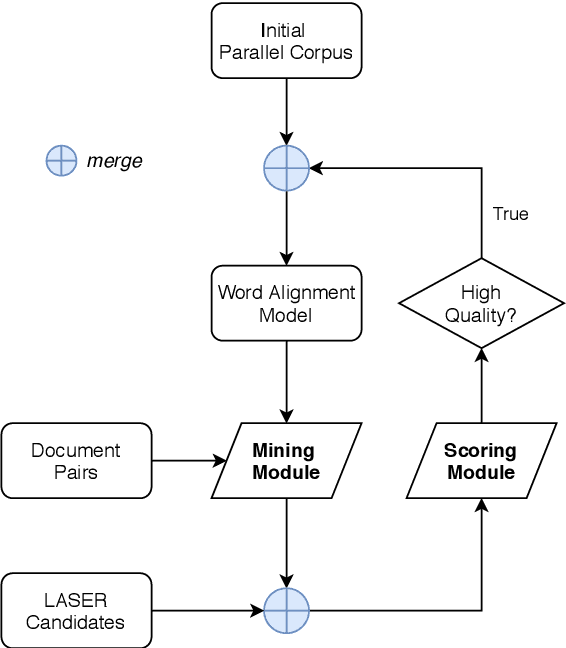

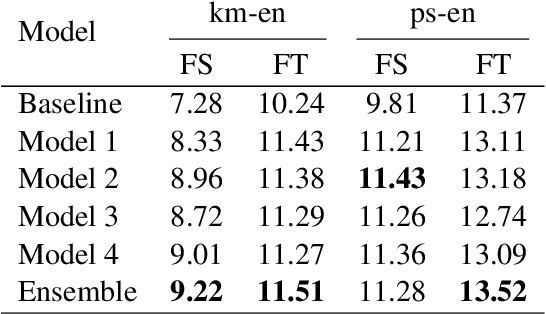
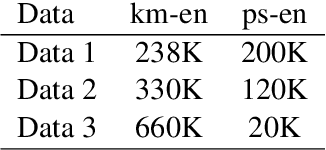
In this paper, we describe our submissions to the WMT20 shared task on parallel corpus filtering and alignment for low-resource conditions. The task requires the participants to align potential parallel sentence pairs out of the given document pairs, and score them so that low-quality pairs can be filtered. Our system, Volctrans, is made of two modules, i.e., a mining module and a scoring module. Based on the word alignment model, the mining module adopts an iterative mining strategy to extract latent parallel sentences. In the scoring module, an XLM-based scorer provides scores, followed by reranking mechanisms and ensemble. Our submissions outperform the baseline by 3.x/2.x and 2.x/2.x for km-en and ps-en on From Scratch/Fine-Tune conditions, which is the highest among all submissions.
Extended Answer and Uncertainty Aware Neural Question Generation
Nov 19, 2019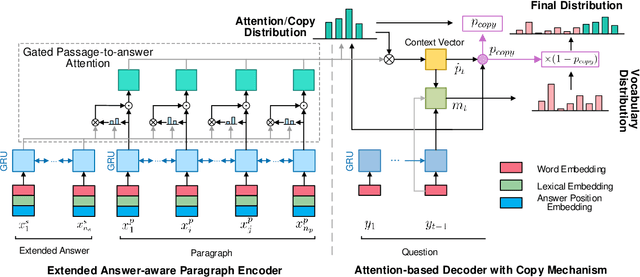
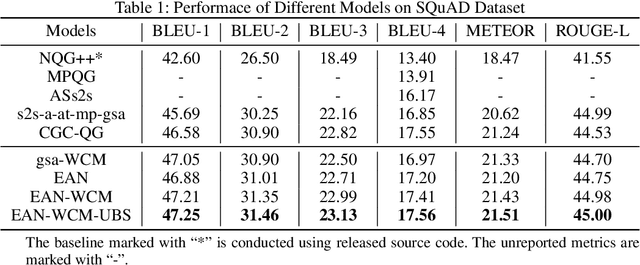
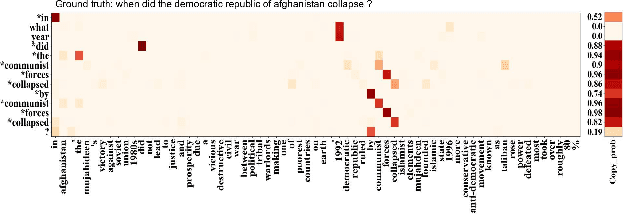

In this paper, we study automatic question generation, the task of creating questions from corresponding text passages where some certain spans of the text can serve as the answers. We propose an Extended Answer-aware Network (EAN) which is trained with Word-based Coverage Mechanism (WCM) and decodes with Uncertainty-aware Beam Search (UBS). The EAN represents the target answer by its surrounding sentence with an encoder, and incorporates the information of the extended answer into paragraph representation with gated paragraph-to-answer attention to tackle the problem of the inadequate representation of the target answer. To reduce undesirable repetition, the WCM penalizes repeatedly attending to the same words at different time-steps in the training stage. The UBS aims to seek a better balance between the model confidence in copying words from an input text paragraph and the confidence in generating words from a vocabulary. We conduct experiments on the SQuAD dataset, and the results show our approach achieves significant performance improvement.
Generative Hierarchical Models for Parts, Objects, and Scenes
Oct 21, 2019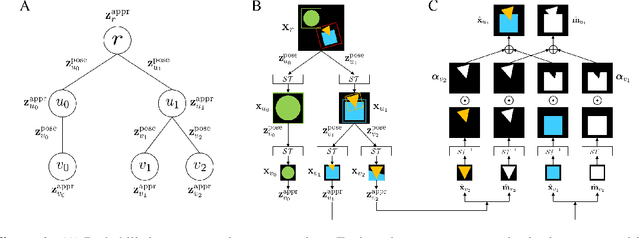
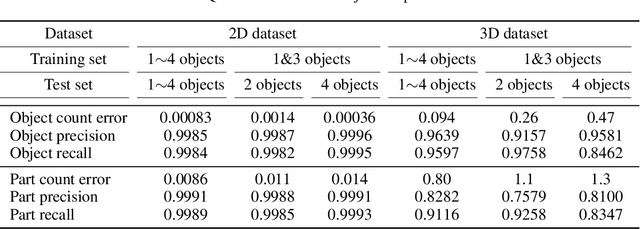

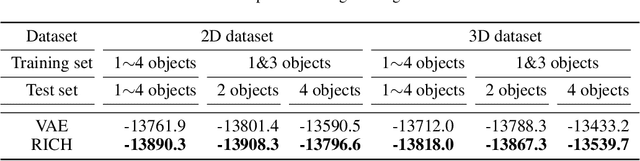
Compositional structures between parts and objects are inherent in natural scenes. Modeling such compositional hierarchies via unsupervised learning can bring various benefits such as interpretability and transferability, which are important in many downstream tasks. In this paper, we propose the first deep latent variable model, called RICH, for learning Representation of Interpretable Compositional Hierarchies. At the core of RICH is a latent scene graph representation that organizes the entities of a scene into a tree structure according to their compositional relationships. During inference, taking top-down approach, RICH is able to use higher-level representation to guide lower-level decomposition. This avoids the difficult problem of routing between parts and objects that is faced by bottom-up approaches. In experiments on images containing multiple objects with different part compositions, we demonstrate that RICH is able to learn the latent compositional hierarchy and generate imaginary scenes.