 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobiDiary: Autoregressive Action Captioning with Wearable Devices and Wireless Signals
Jan 13, 2026Human Activity Recognition (HAR) in smart homes is critical for health monitoring and assistive living. While vision-based systems are common, they face privacy concerns and environmental limitations (e.g., occlusion). In this work, we present MobiDiary, a framework that generates natural language descriptions of daily activities directly from heterogeneous physical signals (specifically IMU and Wi-Fi). Unlike conventional approaches that restrict outputs to pre-defined labels, MobiDiary produces expressive, human-readable summaries. To bridge the semantic gap between continuous, noisy physical signals and discrete linguistic descriptions, we propose a unified sensor encoder. Instead of relying on modality-specific engineering, we exploit the shared inductive biases of motion-induced signals--where both inertial and wireless data reflect underlying kinematic dynamics. Specifically, our encoder utilizes a patch-based mechanism to capture local temporal correlations and integrates heterogeneous placement embedding to unify spatial contexts across different sensors. These unified signal tokens are then fed into a Transformer-based decoder, which employs an autoregressive mechanism to generate coherent action descriptions word-by-word. We comprehensively evaluate our approach on multiple public benchmarks (XRF V2, UWash, and WiFiTAD). Experimental results demonstrate that MobiDiary effectively generalizes across modalities, achieving state-of-the-art performance on captioning metrics (e.g., BLEU@4, CIDEr, RMC) and outperforming specialized baselines in continuous action understanding.
RA-NeRF: Robust Neural Radiance Field Reconstruction with Accurate Camera Pose Estimation under Complex Trajectories
Jun 18, 2025



Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have emerged as powerful tools for 3D reconstruction and SLAM tasks. However, their performance depends heavily on accurate camera pose priors. Existing approaches attempt to address this issue by introducing external constraints but fall short of achieving satisfactory accuracy, particularly when camera trajectories are complex. In this paper, we propose a novel method, RA-NeRF, capable of predicting highly accurate camera poses even with complex camera trajectories. Following the incremental pipeline, RA-NeRF reconstructs the scene using NeRF with photometric consistency and incorporates flow-driven pose regulation to enhance robustness during initialization and localization. Additionally, RA-NeRF employs an implicit pose filter to capture the camera movement pattern and eliminate the noise for pose estimation. To validate our method, we conduct extensive experiments on the Tanks\&Temple dataset for standard evaluation, as well as the NeRFBuster dataset, which presents challenging camera pose trajectories. On both datasets, RA-NeRF achieves state-of-the-art results in both camera pose estimation and visual quality, demonstrating its effectiveness and robustness in scene reconstruction under complex pose trajectories.
A Deep Single Image Rectification Approach for Pan-Tilt-Zoom Cameras
Apr 09, 2025Pan-Tilt-Zoom (PTZ) cameras with wide-angle lenses are widely used in surveillance but often require image rectification due to their inherent nonlinear distortions. Current deep learning approaches typically struggle to maintain fine-grained geometric details, resulting in inaccurate rectification. This paper presents a Forward Distortion and Backward Warping Network (FDBW-Net), a novel framework for wide-angle image rectification. It begins by using a forward distortion model to synthesize barrel-distorted images, reducing pixel redundancy and preventing blur. The network employs a pyramid context encoder with attention mechanisms to generate backward warping flows containing geometric details. Then, a multi-scale decoder is used to restore distorted features and output rectified images. FDBW-Net's performance is validated on diverse datasets: public benchmarks, AirSim-rendered PTZ camera imagery, and real-scene PTZ camera datasets. It demonstrates that FDBW-Net achieves SOTA performance in distortion rectification, boosting the adaptability of PTZ cameras for practical visual applications.
DREMnet: An Interpretable Denoising Framework for Semi-Airborne Transient Electromagnetic Signal
Mar 28, 2025
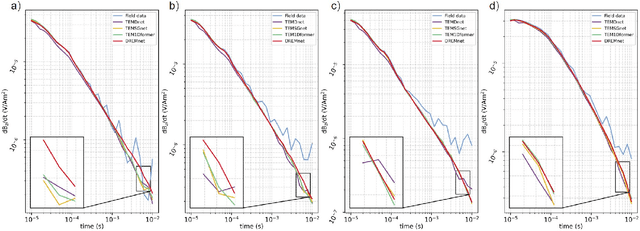


The semi-airborne transient electromagnetic method (SATEM) is capable of conducting rapid surveys over large-scale and hard-to-reach areas. However, the acquired signals are often contaminated by complex noise, which can compromise the accuracy of subsequent inversion interpretations. Traditional denoising techniques primarily rely on parameter selection strategies, which are insufficient for processing field data in noisy environments. With the advent of deep learning, various neural networks have been employed for SATEM signal denoising. However, existing deep learning methods typically use single-mapping learning approaches that struggle to effectively separate signal from noise. These methods capture only partial information and lack interpretability. To overcome these limitations, we propose an interpretable decoupled representation learning framework, termed DREMnet, that disentangles data into content and context factors, enabling robust and interpretable denoising in complex conditions. To address the limitations of CNN and Transformer architectures, we utilize the RWKV architecture for data processing and introduce the Contextual-WKV mechanism, which allows unidirectional WKV to perform bidirectional signal modeling. Our proposed Covering Embedding technique retains the strong local perception of convolutional networks through stacked embedding. Experimental results on test datasets demonstrate that the DREMnet method outperforms existing techniques, with processed field data that more accurately reflects the theoretical signal, offering improved identification of subsurface electrical structures.
Interpretable Deep Learning Paradigm for Airborne Transient Electromagnetic Inversion
Mar 28, 2025



The extraction of geoelectric structural information from airborne transient electromagnetic(ATEM)data primarily involves data processing and inversion. Conventional methods rely on empirical parameter selection, making it difficult to process complex field data with high noise levels. Additionally, inversion computations are time consuming and often suffer from multiple local minima. Existing deep learning-based approaches separate the data processing steps, where independently trained denoising networks struggle to ensure the reliability of subsequent inversions. Moreover, end to end networks lack interpretability. To address these issues, we propose a unified and interpretable deep learning inversion paradigm based on disentangled representation learning. The network explicitly decomposes noisy data into noise and signal factors, completing the entire data processing workflow based on the signal factors while incorporating physical information for guidance. This approach enhances the network's reliability and interpretability. The inversion results on field data demonstrate that our method can directly use noisy data to accurately reconstruct the subsurface electrical structure. Furthermore, it effectively processes data severely affected by environmental noise, which traditional methods struggle with, yielding improved lateral structural resolution.
SphereFusion: Efficient Panorama Depth Estimation via Gated Fusion
Feb 09, 2025Due to the rapid development of panorama cameras, the task of estimating panorama depth has attracted significant attention from the computer vision community, especially in applications such as robot sensing and autonomous driving. However, existing methods relying on different projection formats often encounter challenges, either struggling with distortion and discontinuity in the case of equirectangular, cubemap, and tangent projections, or experiencing a loss of texture details with the spherical projection. To tackle these concerns, we present SphereFusion, an end-to-end framework that combines the strengths of various projection methods. Specifically, SphereFusion initially employs 2D image convolution and mesh operations to extract two distinct types of features from the panorama image in both equirectangular and spherical projection domains. These features are then projected onto the spherical domain, where a gate fusion module selects the most reliable features for fusion. Finally, SphereFusion estimates panorama depth within the spherical domain. Meanwhile, SphereFusion employs a cache strategy to improve the efficiency of mesh operation. Extensive experiments on three public panorama datasets demonstrate that SphereFusion achieves competitive results with other state-of-the-art methods, while presenting the fastest inference speed at only 17 ms on a 512$\times$1024 panorama image.
SiamSeg: Self-Training with Contrastive Learning for Unsupervised Domain Adaptation in Remote Sensing
Oct 17, 2024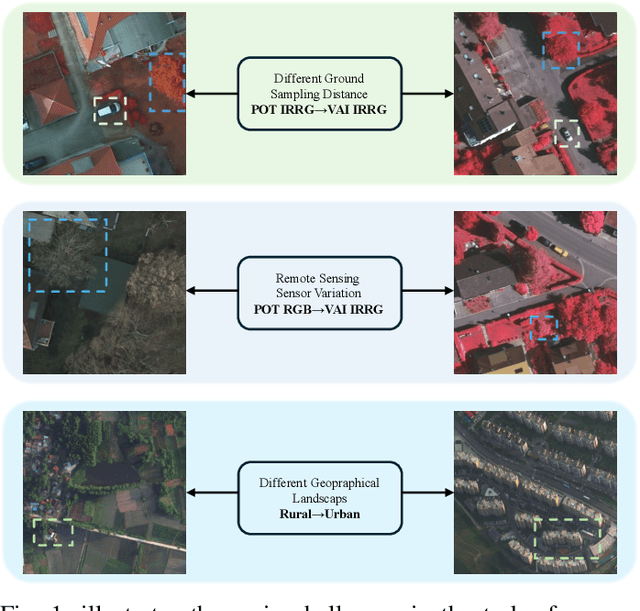
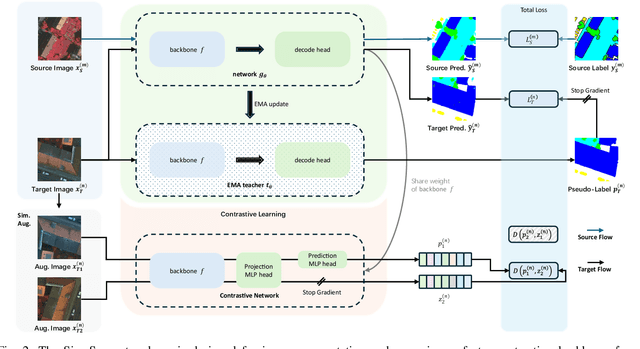
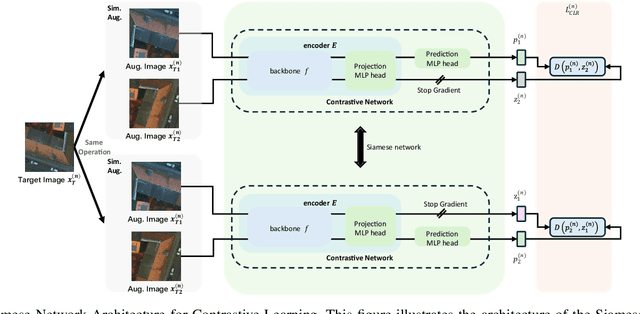
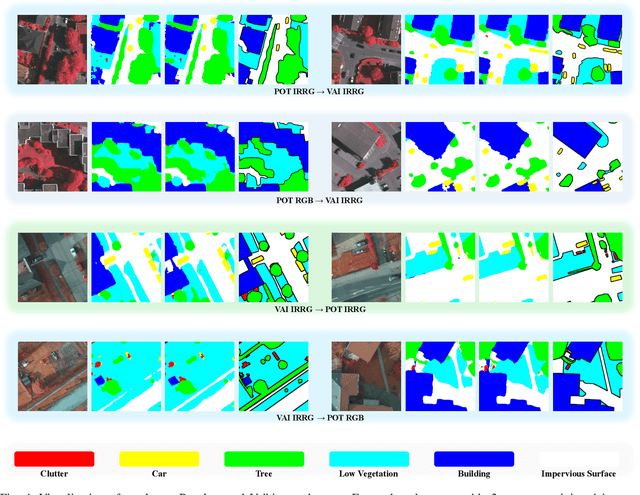
Semantic segmentation of remote sensing (RS) images is a challenging task with significant potential across various applications. Deep learning, especially supervised learning with large-scale labeled datasets, has greatly advanced this field. However, acquiring high-quality labeled data is expensive and time-consuming. Moreover, variations in ground sampling distance (GSD), imaging equipment, and geographic diversity contribute to domain shifts between datasets, which pose significant challenges to models trained solely on source domain data, leading to poor cross-domain performance. Domain shift is well-known for undermining a model's generalization ability in the target domain. To address this, unsupervised domain adaptation (UDA) has emerged as a promising solution, enabling models to learn from unlabeled target domain data while training on labeled source domain data. Recent advancements, particularly in self-supervised learning via pseudo-label generation, have shown potential in mitigating domain discrepancies. Strategies combining source and target domain images with their true and pseudo labels for self-supervised training have been effective in addressing domain bias. Despite progress in computer vision, the application of pseudo-labeling methods to RS image segmentation remains underexplored.
3-D Magnetotelluric Deep Learning Inversion Guided by Pseudo-Physical Information
Oct 12, 2024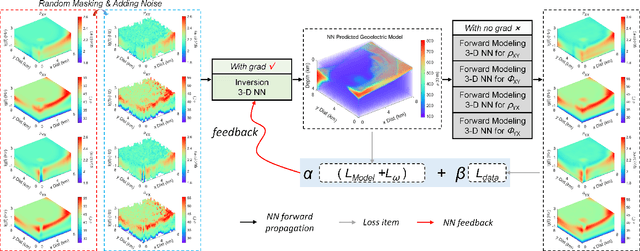
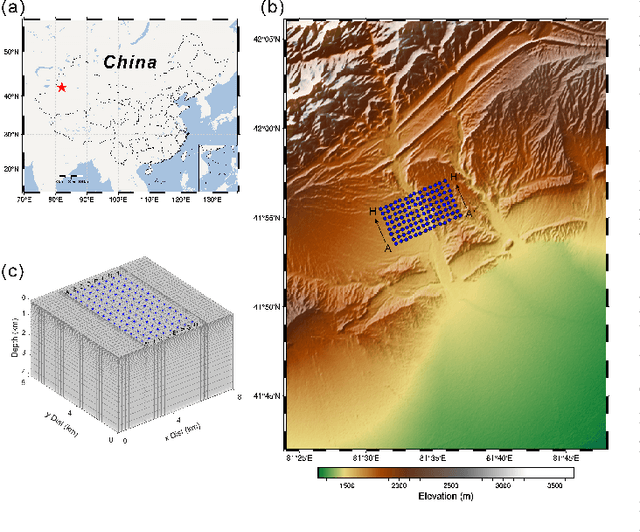
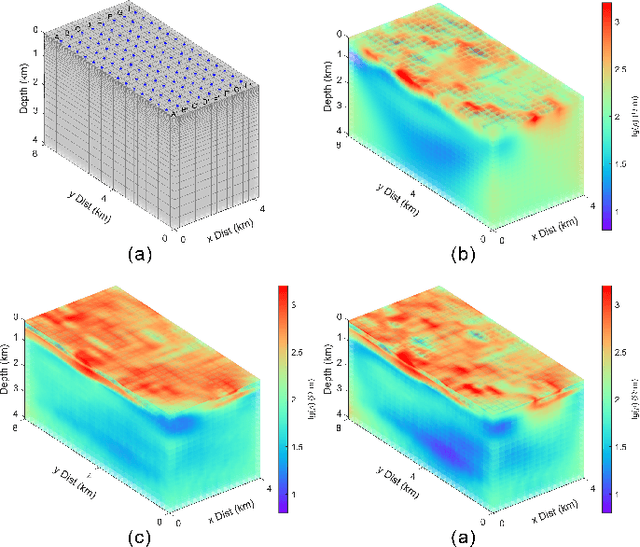
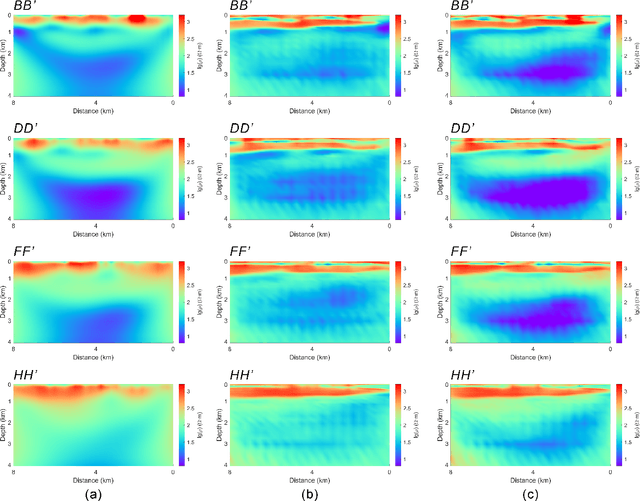
Magnetotelluric deep learning (DL) inversion methods based on joint data-driven and physics-driven have become a hot topic in recent years. When mapping observation data (or forward modeling data) to the resistivity model using neural networks (NNs), incorporating the error (loss) term of the inversion resistivity's forward modeling response--which introduces physical information about electromagnetic field propagation--can significantly enhance the inversion accuracy. To efficiently achieve data-physical dual-driven MT deep learning inversion for large-scale 3-D MT data, we propose using DL forward modeling networks to compute this portion of the loss. This approach introduces pseudo-physical information through the forward modeling of NN simulation, further guiding the inversion network fitting. Specifically, we first pre-train the forward modeling networks as fixed forward modeling operators, then transfer and integrate them into the inversion network training, and finally optimize the inversion network by minimizing the multinomial loss. Theoretical experimental results indicate that despite some simulation errors in DL forward modeling, the introduced pseudo-physical information still enhances inversion accuracy and significantly mitigates the overfitting problem during training. Additionally, we propose a new input mode that involves masking and adding noise to the data, simulating the field data environment of 3-D MT inversion, thereby making the method more flexible and effective for practical applications.
Slot State Space Models
Jun 18, 2024Recent State Space Models (SSMs) such as S4, S5, and Mamba have shown remarkable computational benefits in long-range temporal dependency modeling. However, in many sequence modeling problems, the underlying process is inherently modular and it is of interest to have inductive biases that mimic this modular structure. In this paper, we introduce SlotSSMs, a novel framework for incorporating independent mechanisms into SSMs to preserve or encourage separation of information. Unlike conventional SSMs that maintain a monolithic state vector, SlotSSMs maintains the state as a collection of multiple vectors called slots. Crucially, the state transitions are performed independently per slot with sparse interactions across slots implemented via the bottleneck of self-attention. In experiments, we evaluate our model in object-centric video understanding, 3D visual reasoning, and video prediction tasks, which involve modeling multiple objects and their long-range temporal dependencies. We find that our proposed design offers substantial performance gains over existing sequence modeling methods.
PlanDQ: Hierarchical Plan Orchestration via D-Conductor and Q-Performer
Jun 10, 2024
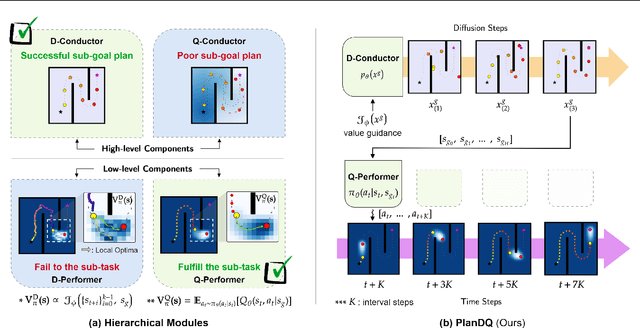
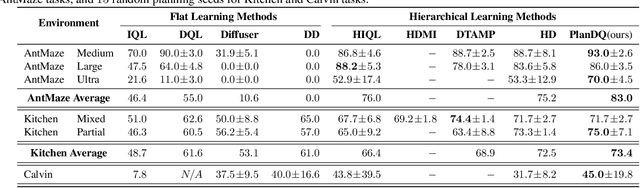
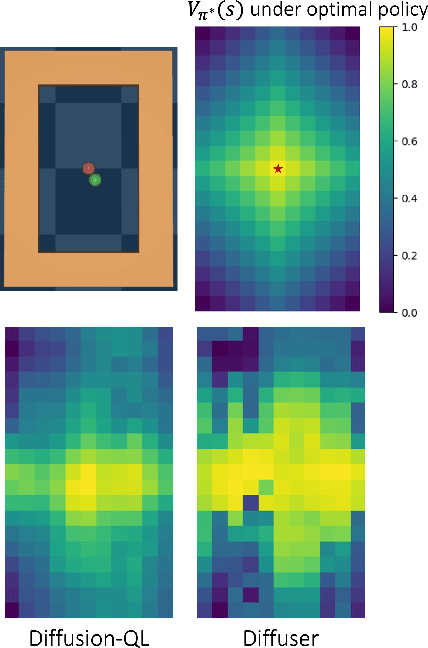
Despite the recent advancements in offline RL, no unified algorithm could achieve superior performance across a broad range of tasks. Offline \textit{value function learning}, in particular, struggles with sparse-reward, long-horizon tasks due to the difficulty of solving credit assignment and extrapolation errors that accumulates as the horizon of the task grows.~On the other hand, models that can perform well in long-horizon tasks are designed specifically for goal-conditioned tasks, which commonly perform worse than value function learning methods on short-horizon, dense-reward scenarios. To bridge this gap, we propose a hierarchical planner designed for offline RL called PlanDQ. PlanDQ incorporates a diffusion-based planner at the high level, named D-Conductor, which guides the low-level policy through sub-goals. At the low level, we used a Q-learning based approach called the Q-Performer to accomplish these sub-goals. Our experimental results suggest that PlanDQ can achieve superior or competitive performance on D4RL continuous control benchmark tasks as well as AntMaze, Kitchen, and Calvin as long-horizon tasks.