 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRA-NeRF: Robust Neural Radiance Field Reconstruction with Accurate Camera Pose Estimation under Complex Trajectories
Jun 18, 2025



Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have emerged as powerful tools for 3D reconstruction and SLAM tasks. However, their performance depends heavily on accurate camera pose priors. Existing approaches attempt to address this issue by introducing external constraints but fall short of achieving satisfactory accuracy, particularly when camera trajectories are complex. In this paper, we propose a novel method, RA-NeRF, capable of predicting highly accurate camera poses even with complex camera trajectories. Following the incremental pipeline, RA-NeRF reconstructs the scene using NeRF with photometric consistency and incorporates flow-driven pose regulation to enhance robustness during initialization and localization. Additionally, RA-NeRF employs an implicit pose filter to capture the camera movement pattern and eliminate the noise for pose estimation. To validate our method, we conduct extensive experiments on the Tanks\&Temple dataset for standard evaluation, as well as the NeRFBuster dataset, which presents challenging camera pose trajectories. On both datasets, RA-NeRF achieves state-of-the-art results in both camera pose estimation and visual quality, demonstrating its effectiveness and robustness in scene reconstruction under complex pose trajectories.
SphereFusion: Efficient Panorama Depth Estimation via Gated Fusion
Feb 09, 2025Due to the rapid development of panorama cameras, the task of estimating panorama depth has attracted significant attention from the computer vision community, especially in applications such as robot sensing and autonomous driving. However, existing methods relying on different projection formats often encounter challenges, either struggling with distortion and discontinuity in the case of equirectangular, cubemap, and tangent projections, or experiencing a loss of texture details with the spherical projection. To tackle these concerns, we present SphereFusion, an end-to-end framework that combines the strengths of various projection methods. Specifically, SphereFusion initially employs 2D image convolution and mesh operations to extract two distinct types of features from the panorama image in both equirectangular and spherical projection domains. These features are then projected onto the spherical domain, where a gate fusion module selects the most reliable features for fusion. Finally, SphereFusion estimates panorama depth within the spherical domain. Meanwhile, SphereFusion employs a cache strategy to improve the efficiency of mesh operation. Extensive experiments on three public panorama datasets demonstrate that SphereFusion achieves competitive results with other state-of-the-art methods, while presenting the fastest inference speed at only 17 ms on a 512$\times$1024 panorama image.
FusionLLM: A Decentralized LLM Training System on Geo-distributed GPUs with Adaptive Compression
Oct 16, 2024



To alleviate hardware scarcity in training large deep neural networks (DNNs), particularly large language models (LLMs), we present FusionLLM, a decentralized training system designed and implemented for training DNNs using geo-distributed GPUs across different computing clusters or individual devices. Decentralized training faces significant challenges regarding system design and efficiency, including: 1) the need for remote automatic differentiation (RAD), 2) support for flexible model definitions and heterogeneous software, 3) heterogeneous hardware leading to low resource utilization or the straggler problem, and 4) slow network communication. To address these challenges, in the system design, we represent the model as a directed acyclic graph of operators (OP-DAG). Each node in the DAG represents the operator in the DNNs, while the edge represents the data dependency between operators. Based on this design, 1) users are allowed to customize any DNN without caring low-level operator implementation; 2) we enable the task scheduling with the more fine-grained sub-tasks, offering more optimization space; 3) a DAG runtime executor can implement RAD withour requiring the consistent low-level ML framework versions. To enhance system efficiency, we implement a workload estimator and design an OP-Fence scheduler to cluster devices with similar bandwidths together and partition the DAG to increase throughput. Additionally, we propose an AdaTopK compressor to adaptively compress intermediate activations and gradients at the slowest communication links. To evaluate the convergence and efficiency of our system and algorithms, we train ResNet-101 and GPT-2 on three real-world testbeds using 48 GPUs connected with 8 Mbps~10 Gbps networks. Experimental results demonstrate that our system and method can achieve 1.45 - 9.39x speedup compared to baseline methods while ensuring convergence.
CF-NeRF: Camera Parameter Free Neural Radiance Fields with Incremental Learning
Dec 14, 2023Neural Radiance Fields (NeRF) have demonstrated impressive performance in novel view synthesis. However, NeRF and most of its variants still rely on traditional complex pipelines to provide extrinsic and intrinsic camera parameters, such as COLMAP. Recent works, like NeRFmm, BARF, and L2G-NeRF, directly treat camera parameters as learnable and estimate them through differential volume rendering. However, these methods work for forward-looking scenes with slight motions and fail to tackle the rotation scenario in practice. To overcome this limitation, we propose a novel \underline{c}amera parameter \underline{f}ree neural radiance field (CF-NeRF), which incrementally reconstructs 3D representations and recovers the camera parameters inspired by incremental structure from motion (SfM). Given a sequence of images, CF-NeRF estimates the camera parameters of images one by one and reconstructs the scene through initialization, implicit localization, and implicit optimization. To evaluate our method, we use a challenging real-world dataset NeRFBuster which provides 12 scenes under complex trajectories. Results demonstrate that CF-NeRF is robust to camera rotation and achieves state-of-the-art results without providing prior information and constraints.
FusionAI: Decentralized Training and Deploying LLMs with Massive Consumer-Level GPUs
Sep 03, 2023



The rapid growth of memory and computation requirements of large language models (LLMs) has outpaced the development of hardware, hindering people who lack large-scale high-end GPUs from training or deploying LLMs. However, consumer-level GPUs, which constitute a larger market share, are typically overlooked in LLM due to their weaker computing performance, smaller storage capacity, and lower communication bandwidth. Additionally, users may have privacy concerns when interacting with remote LLMs. In this paper, we envision a decentralized system unlocking the potential vast untapped consumer-level GPUs in pre-training, inference and fine-tuning of LLMs with privacy protection. However, this system faces critical challenges, including limited CPU and GPU memory, low network bandwidth, the variability of peer and device heterogeneity. To address these challenges, our system design incorporates: 1) a broker with backup pool to implement dynamic join and quit of computing providers; 2) task scheduling with hardware performance to improve system efficiency; 3) abstracting ML procedures into directed acyclic graphs (DAGs) to achieve model and task universality; 4) abstracting intermediate represention and execution planes to ensure compatibility of various devices and deep learning (DL) frameworks. Our performance analysis demonstrates that 50 RTX 3080 GPUs can achieve throughputs comparable to those of 4 H100 GPUs, which are significantly more expensive.
Rethinking Disparity: A Depth Range Free Multi-View Stereo Based on Disparity
Dec 04, 2022



Existing learning-based multi-view stereo (MVS) methods rely on the depth range to build the 3D cost volume and may fail when the range is too large or unreliable. To address this problem, we propose a disparity-based MVS method based on the epipolar disparity flow (E-flow), called DispMVS, which infers the depth information from the pixel movement between two views. The core of DispMVS is to construct a 2D cost volume on the image plane along the epipolar line between each pair (between the reference image and several source images) for pixel matching and fuse uncountable depths triangulated from each pair by multi-view geometry to ensure multi-view consistency. To be robust, DispMVS starts from a randomly initialized depth map and iteratively refines the depth map with the help of the coarse-to-fine strategy. Experiments on DTUMVS and Tanks\&Temple datasets show that DispMVS is not sensitive to the depth range and achieves state-of-the-art results with lower GPU memory.
SphereDepth: Panorama Depth Estimation from Spherical Domain
Aug 30, 2022
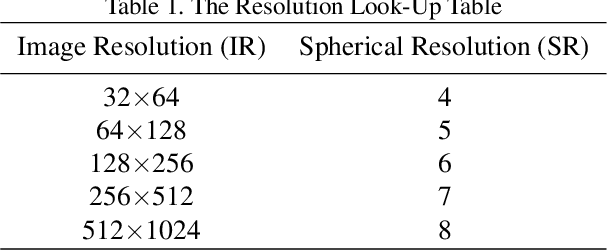
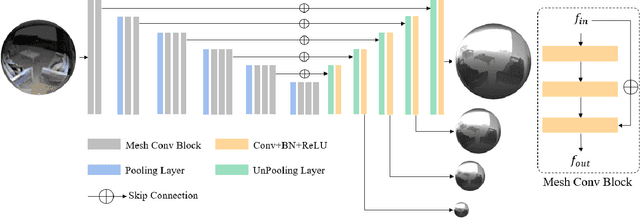
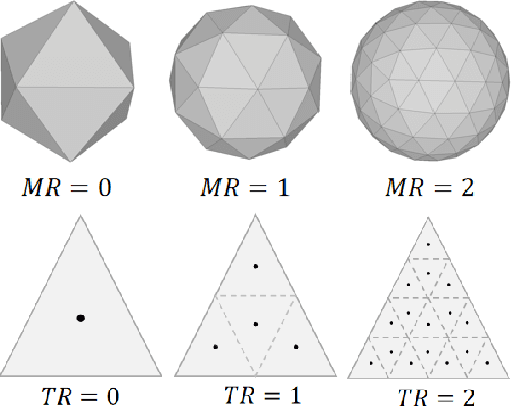
The panorama image can simultaneously demonstrate complete information of the surrounding environment and has many advantages in virtual tourism, games, robotics, etc. However, the progress of panorama depth estimation cannot completely solve the problems of distortion and discontinuity caused by the commonly used projection methods. This paper proposes SphereDepth, a novel panorama depth estimation method that predicts the depth directly on the spherical mesh without projection preprocessing. The core idea is to establish the relationship between the panorama image and the spherical mesh and then use a deep neural network to extract features on the spherical domain to predict depth. To address the efficiency challenges brought by the high-resolution panorama data, we introduce two hyper-parameters for the proposed spherical mesh processing framework to balance the inference speed and accuracy. Validated on three public panorama datasets, SphereDepth achieves comparable results with the state-of-the-art methods of panorama depth estimation. Benefiting from the spherical domain setting, SphereDepth can generate a high-quality point cloud and significantly alleviate the issues of distortion and discontinuity.
EASNet: Searching Elastic and Accurate Network Architecture for Stereo Matching
Jul 20, 2022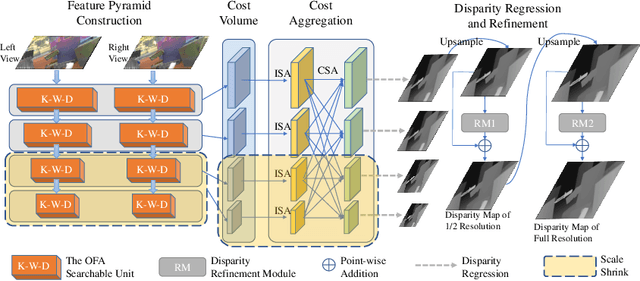
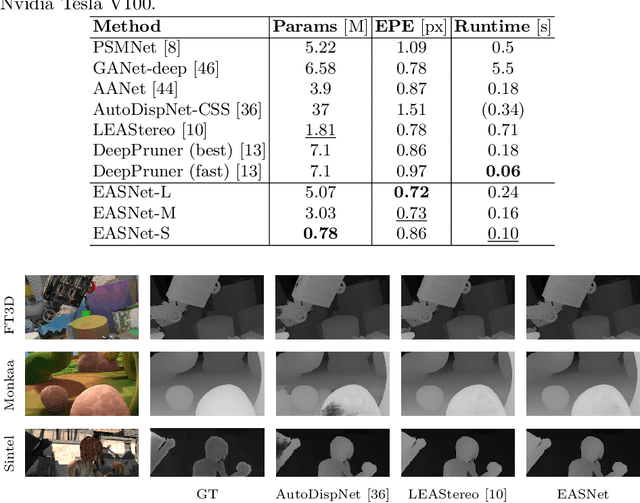
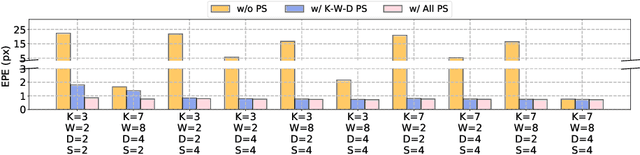
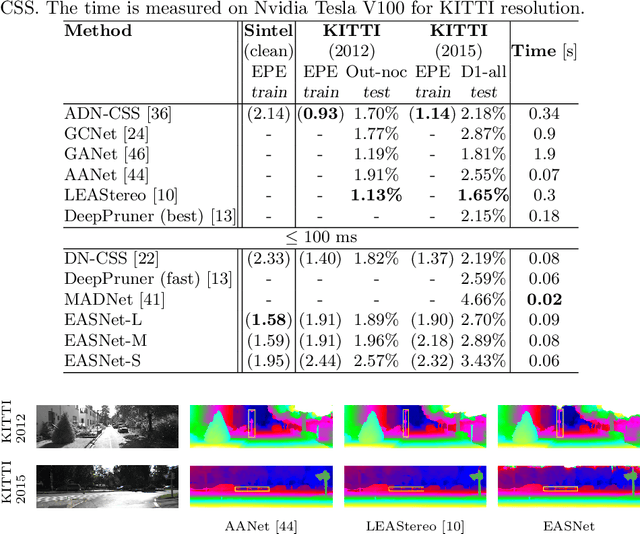
Recent advanced studies have spent considerable human efforts on optimizing network architectures for stereo matching but hardly achieved both high accuracy and fast inference speed. To ease the workload in network design, neural architecture search (NAS) has been applied with great success to various sparse prediction tasks, such as image classification and object detection. However, existing NAS studies on the dense prediction task, especially stereo matching, still cannot be efficiently and effectively deployed on devices of different computing capabilities. To this end, we propose to train an elastic and accurate network for stereo matching (EASNet) that supports various 3D architectural settings on devices with different computing capabilities. Given the deployment latency constraint on the target device, we can quickly extract a sub-network from the full EASNet without additional training while the accuracy of the sub-network can still be maintained. Extensive experiments show that our EASNet outperforms both state-of-the-art human-designed and NAS-based architectures on Scene Flow and MPI Sintel datasets in terms of model accuracy and inference speed. Particularly, deployed on an inference GPU, EASNet achieves a new SOTA 0.73 EPE on the Scene Flow dataset with 100 ms, which is 4.5$\times$ faster than LEAStereo with a better quality model.
FADNet++: Real-Time and Accurate Disparity Estimation with Configurable Networks
Oct 06, 2021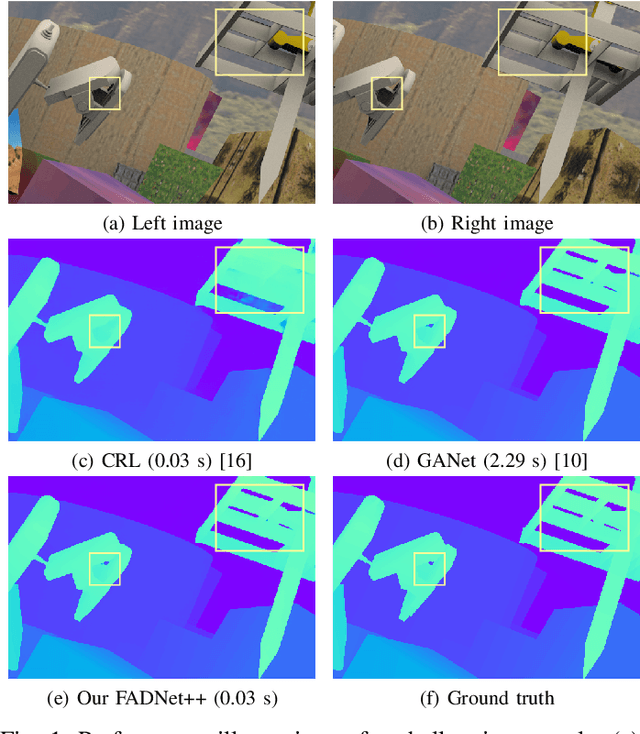
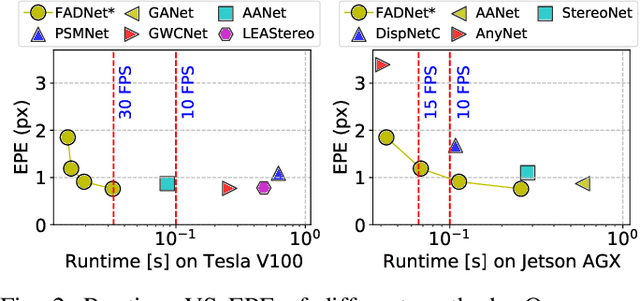
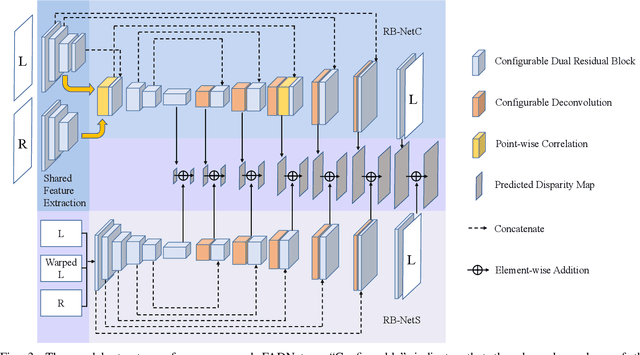
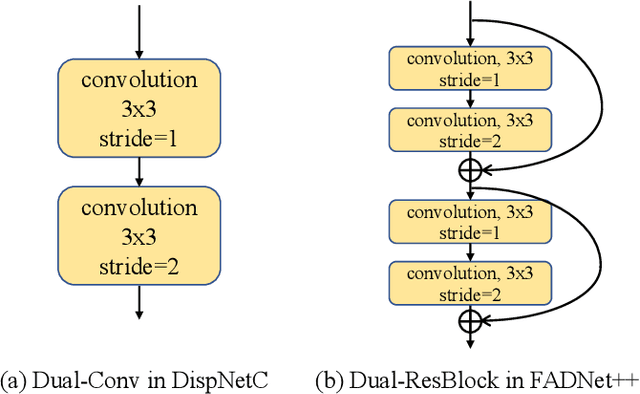
Deep neural networks (DNNs) have achieved great success in the area of computer vision. The disparity estimation problem tends to be addressed by DNNs which achieve much better prediction accuracy than traditional hand-crafted feature-based methods. However, the existing DNNs hardly serve both efficient computation and rich expression capability, which makes them difficult for deployment in real-time and high-quality applications, especially on mobile devices. To this end, we propose an efficient, accurate, and configurable deep network for disparity estimation named FADNet++. Leveraging several liberal network design and training techniques, FADNet++ can boost its accuracy with a fast model inference speed for real-time applications. Besides, it enables users to easily configure different sizes of models for balancing accuracy and inference efficiency. We conduct extensive experiments to demonstrate the effectiveness of FADNet++ on both synthetic and realistic datasets among six GPU devices varying from server to mobile platforms. Experimental results show that FADNet++ and its variants achieve state-of-the-art prediction accuracy, and run at a significant order of magnitude faster speed than existing 3D models. With the constraint of running at above 15 frames per second (FPS) on a mobile GPU, FADNet++ achieves a new state-of-the-art result for the SceneFlow dataset.
FADNet: A Fast and Accurate Network for Disparity Estimation
Mar 24, 2020
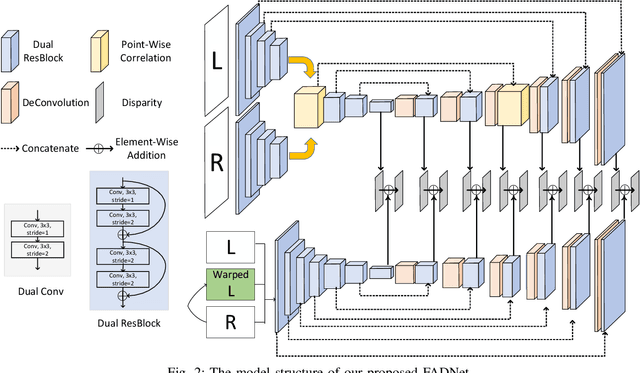


Deep neural networks (DNNs) have achieved great success in the area of computer vision. The disparity estimation problem tends to be addressed by DNNs which achieve much better prediction accuracy in stereo matching than traditional hand-crafted feature based methods. On one hand, however, the designed DNNs require significant memory and computation resources to accurately predict the disparity, especially for those 3D convolution based networks, which makes it difficult for deployment in real-time applications. On the other hand, existing computation-efficient networks lack expression capability in large-scale datasets so that they cannot make an accurate prediction in many scenarios. To this end, we propose an efficient and accurate deep network for disparity estimation named FADNet with three main features: 1) It exploits efficient 2D based correlation layers with stacked blocks to preserve fast computation; 2) It combines the residual structures to make the deeper model easier to learn; 3) It contains multi-scale predictions so as to exploit a multi-scale weight scheduling training technique to improve the accuracy. We conduct experiments to demonstrate the effectiveness of FADNet on two popular datasets, Scene Flow and KITTI 2015. Experimental results show that FADNet achieves state-of-the-art prediction accuracy, and runs at a significant order of magnitude faster speed than existing 3D models. The codes of FADNet are available at https://github.com/HKBU-HPML/FADNet.