 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Outlier Dynamics in LLM NVFP4 Pretraining
Feb 02, 2026Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with "post-QK" operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.
On the Spectral Flattening of Quantized Embeddings
Feb 01, 2026Training Large Language Models (LLMs) at ultra-low precision is critically impeded by instability rooted in the conflict between discrete quantization constraints and the intrinsic heavy-tailed spectral nature of linguistic data. By formalizing the connection between Zipfian statistics and random matrix theory, we prove that the power-law decay in the singular value spectra of embeddings is a fundamental requisite for semantic encoding. We derive theoretical bounds showing that uniform quantization introduces a noise floor that disproportionately truncates this spectral tail, which induces spectral flattening and a strictly provable increase in the stable rank of representations. Empirical validation across diverse architectures including GPT-2 and TinyLlama corroborates that this geometric degradation precipitates representational collapse. This work not only quantifies the spectral sensitivity of LLMs but also establishes spectral fidelity as a necessary condition for stable low-bit optimization.
SONIC: Segmented Optimized Nexus for Information Compression in Key-Value Caching
Jan 29, 2026The linear growth of Key-Value (KV) cache remains a bottleneck for multi-turn LLM deployment. Existing KV cache compression methods often fail to account for the structural properties of multi-turn dialogues, relying on heuristic eviction that risks losing critical context. We propose \textbf{SONIC}, a learning-based framework that compresses historical segments into compact and semantically rich \textbf{Nexus} tokens. By integrating dynamic budget training, SONIC allows flexible adaptation to varying memory constraints without retraining. Experiments show that at compression ratios of 80\% and 50\%, SONIC consistently outperforms baselines such as H2O and StreamingLLM on four diverse multi-turn benchmarks. Specifically, on the widely used MTBench101 benchmark, SONIC achieves an average score improvement of 35.55\% over state-of-the-art baselines, validating its effectiveness in sustaining coherent multi-turn dialogues. Furthermore, SONIC enhances deployment efficiency, accelerating the overall inference process by 50.1\% compared to full-context generation.
Efficient MoE Inference with Fine-Grained Scheduling of Disaggregated Expert Parallelism
Dec 25, 2025



The mixture-of-experts (MoE) architecture scales model size with sublinear computational increase but suffers from memory-intensive inference due to KV caches and sparse expert activation. Recent disaggregated expert parallelism (DEP) distributes attention and experts to dedicated GPU groups but lacks support for shared experts and efficient task scheduling, limiting performance. We propose FinDEP, a fine-grained task scheduling algorithm for DEP that maximizes task overlap to improve MoE inference throughput. FinDEP introduces three innovations: 1) partitioning computation/communication into smaller tasks for fine-grained pipelining, 2) formulating a scheduling optimization supporting variable granularity and ordering, and 3) developing an efficient solver for this large search space. Experiments on four GPU systems with DeepSeek-V2 and Qwen3-MoE show FinDEP improves throughput by up to 1.61x over prior methods, achieving up to 1.24x speedup on a 32-GPU system.
Venus: An Efficient Edge Memory-and-Retrieval System for VLM-based Online Video Understanding
Dec 08, 2025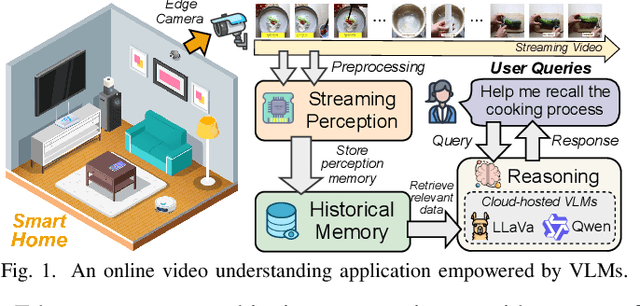
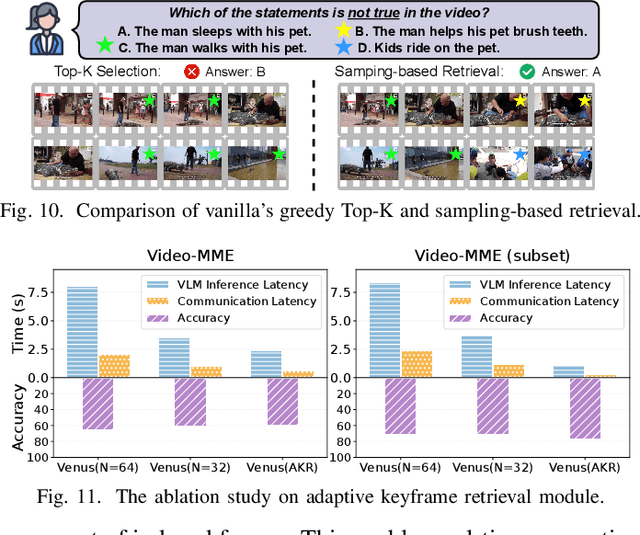
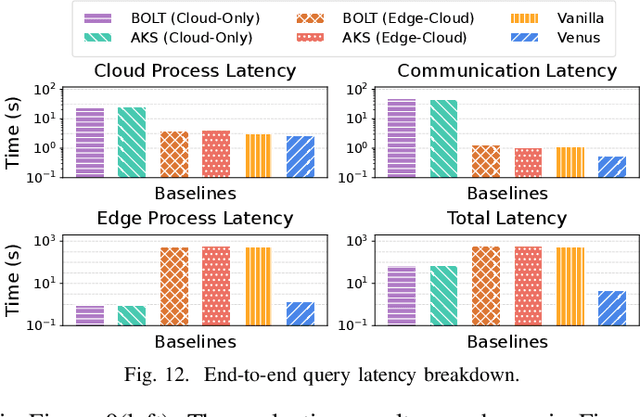
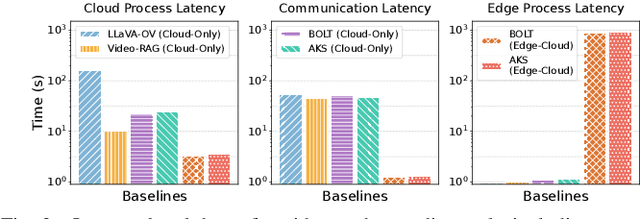
Vision-language models (VLMs) have demonstrated impressive multimodal comprehension capabilities and are being deployed in an increasing number of online video understanding applications. While recent efforts extensively explore advancing VLMs' reasoning power in these cases, deployment constraints are overlooked, leading to overwhelming system overhead in real-world deployments. To address that, we propose Venus, an on-device memory-and-retrieval system for efficient online video understanding. Venus proposes an edge-cloud disaggregated architecture that sinks memory construction and keyframe retrieval from cloud to edge, operating in two stages. In the ingestion stage, Venus continuously processes streaming edge videos via scene segmentation and clustering, where the selected keyframes are embedded with a multimodal embedding model to build a hierarchical memory for efficient storage and retrieval. In the querying stage, Venus indexes incoming queries from memory, and employs a threshold-based progressive sampling algorithm for keyframe selection that enhances diversity and adaptively balances system cost and reasoning accuracy. Our extensive evaluation shows that Venus achieves a 15x-131x speedup in total response latency compared to state-of-the-art methods, enabling real-time responses within seconds while maintaining comparable or even superior reasoning accuracy.
Towards Universal Video Retrieval: Generalizing Video Embedding via Synthesized Multimodal Pyramid Curriculum
Oct 31, 2025The prevailing video retrieval paradigm is structurally misaligned, as narrow benchmarks incentivize correspondingly limited data and single-task training. Therefore, universal capability is suppressed due to the absence of a diagnostic evaluation that defines and demands multi-dimensional generalization. To break this cycle, we introduce a framework built on the co-design of evaluation, data, and modeling. First, we establish the Universal Video Retrieval Benchmark (UVRB), a suite of 16 datasets designed not only to measure performance but also to diagnose critical capability gaps across tasks and domains. Second, guided by UVRB's diagnostics, we introduce a scalable synthesis workflow that generates 1.55 million high-quality pairs to populate the semantic space required for universality. Finally, we devise the Modality Pyramid, a curriculum that trains our General Video Embedder (GVE) by explicitly leveraging the latent interconnections within our diverse data. Extensive experiments show GVE achieves state-of-the-art zero-shot generalization on UVRB. In particular, our analysis reveals that popular benchmarks are poor predictors of general ability and that partially relevant retrieval is a dominant but overlooked scenario. Overall, our co-designed framework provides a practical path to escape the limited scope and advance toward truly universal video retrieval.
SGMAGNet: A Baseline Model for 3D Cloud Phase Structure Reconstruction on a New Passive Active Satellite Benchmark
Sep 19, 2025Cloud phase profiles are critical for numerical weather prediction (NWP), as they directly affect radiative transfer and precipitation processes. In this study, we present a benchmark dataset and a baseline framework for transforming multimodal satellite observations into detailed 3D cloud phase structures, aiming toward operational cloud phase profile retrieval and future integration with NWP systems to improve cloud microphysics parameterization. The multimodal observations consist of (1) high--spatiotemporal--resolution, multi-band visible (VIS) and thermal infrared (TIR) imagery from geostationary satellites, and (2) accurate vertical cloud phase profiles from spaceborne lidar (CALIOP\slash CALIPSO) and radar (CPR\slash CloudSat). The dataset consists of synchronized image--profile pairs across diverse cloud regimes, defining a supervised learning task: given VIS/TIR patches, predict the corresponding 3D cloud phase structure. We adopt SGMAGNet as the main model and compare it with several baseline architectures, including UNet variants and SegNet, all designed to capture multi-scale spatial patterns. Model performance is evaluated using standard classification metrics, including Precision, Recall, F1-score, and IoU. The results demonstrate that SGMAGNet achieves superior performance in cloud phase reconstruction, particularly in complex multi-layer and boundary transition regions. Quantitatively, SGMAGNet attains a Precision of 0.922, Recall of 0.858, F1-score of 0.763, and an IoU of 0.617, significantly outperforming all baselines across these key metrics.
AnTKV: Anchor Token-Aware Sub-Bit Vector Quantization for KV Cache in Large Language Models
Jun 24, 2025Quantization has emerged as an effective and lightweight solution to reduce the memory footprint of the KV cache in Large Language Models (LLMs). Nevertheless, minimizing the performance degradation caused by ultra-low-bit KV cache quantization remains a significant challenge. We observe that quantizing the KV cache of different tokens has varying impacts on the quality of attention outputs. To systematically investigate this phenomenon, we perform forward error propagation analysis on attention and propose the Anchor Score (AnS) that quantifies the sensitivity of each token's KV cache to quantization-induced error. Our analysis reveals significant disparities in AnS across tokens, suggesting that preserving a small subset with full precision (FP16) of high-AnS tokens can greatly mitigate accuracy loss in aggressive quantization scenarios. Based on this insight, we introduce AnTKV, a novel framework that leverages Anchor Token-aware Vector Quantization to compress the KV cache. Furthermore, to support efficient deployment, we design and develop a triton kernel that is fully compatible with FlashAttention, enabling fast online Anchor Token selection. AnTKV enables LLaMA-3-8B to handle context lengths up to 840K tokens on a single 80GB A100 GPU, while achieving up to 3.5x higher decoding throughput compared to the FP16 baseline. Our experiment results demonstrate that AnTKV matches or outperforms prior works such as KIVI, SKVQ, KVQuant, and CQ under 4-bit settings. More importantly, AnTKV achieves significantly lower perplexity under ultra-low-bit quantization on Mistral-7B, with only 6.32 at 1-bit and 8.87 at 0.375-bit, compared to the FP16 baseline of 4.73.
RA-NeRF: Robust Neural Radiance Field Reconstruction with Accurate Camera Pose Estimation under Complex Trajectories
Jun 18, 2025



Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have emerged as powerful tools for 3D reconstruction and SLAM tasks. However, their performance depends heavily on accurate camera pose priors. Existing approaches attempt to address this issue by introducing external constraints but fall short of achieving satisfactory accuracy, particularly when camera trajectories are complex. In this paper, we propose a novel method, RA-NeRF, capable of predicting highly accurate camera poses even with complex camera trajectories. Following the incremental pipeline, RA-NeRF reconstructs the scene using NeRF with photometric consistency and incorporates flow-driven pose regulation to enhance robustness during initialization and localization. Additionally, RA-NeRF employs an implicit pose filter to capture the camera movement pattern and eliminate the noise for pose estimation. To validate our method, we conduct extensive experiments on the Tanks\&Temple dataset for standard evaluation, as well as the NeRFBuster dataset, which presents challenging camera pose trajectories. On both datasets, RA-NeRF achieves state-of-the-art results in both camera pose estimation and visual quality, demonstrating its effectiveness and robustness in scene reconstruction under complex pose trajectories.
Can Compressed LLMs Truly Act? An Empirical Evaluation of Agentic Capabilities in LLM Compression
May 26, 2025


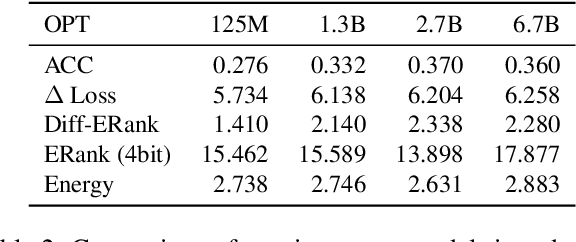
Post-training compression reduces the computational and memory costs of large language models (LLMs), enabling resource-efficient deployment. However, existing compression benchmarks only focus on language modeling (e.g., perplexity) and natural language understanding tasks (e.g., GLUE accuracy), ignoring the agentic capabilities - workflow, tool use/function call, long-context understanding and real-world application. We introduce the Agent Compression Benchmark (ACBench), the first comprehensive benchmark for evaluating how compression impacts LLMs' agentic abilities. ACBench spans (1) 12 tasks across 4 capabilities (e.g., WorfBench for workflow generation, Needle-in-Haystack for long-context retrieval), (2) quantization (GPTQ, AWQ) and pruning (Wanda, SparseGPT), and (3) 15 models, including small (Gemma-2B), standard (Qwen2.5 7B-32B), and distilled reasoning LLMs (DeepSeek-R1-Distill). Our experiments reveal compression tradeoffs: 4-bit quantization preserves workflow generation and tool use (1%-3% drop) but degrades real-world application accuracy by 10%-15%. We introduce ERank, Top-k Ranking Correlation and Energy to systematize analysis. ACBench provides actionable insights for optimizing LLM compression in agentic scenarios. The code can be found in https://github.com/pprp/ACBench.