 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning with Autoregressive-Diffusion Collaborative Thoughts
Feb 02, 2026Autoregressive and diffusion models represent two complementary generative paradigms. Autoregressive models excel at sequential planning and constraint composition, yet struggle with tasks that require explicit spatial or physical grounding. Diffusion models, in contrast, capture rich spatial structure through high-dimensional generation, but lack the stepwise logical control needed to satisfy complex, multi-stage constraints or to reliably identify and correct errors. We introduce Collaborative Thoughts, a unified collaborative framework that enables autoregressive and diffusion models to reason and generate jointly through a closed-loop interaction. In Collaborative Thoughts, autoregressive models perform structured planning and constraint management, diffusion models instantiate these constraints as intermediate visual thoughts, and a vision-based critic module evaluates whether the visual thoughts satisfy the intended structural and physical requirements. This feedback is then used to iteratively refine subsequent planning and generation steps, mitigating error propagation across modalities. Importantly, Collaborative Thoughts uses the same collaborative loop regardless of whether the task is autoregressive question answering or diffusion-based visual generation. Through representative examples, we illustrate how Collaborative Thoughts can improve the reliability of spatial reasoning and the controllability of generation.
Venus: An Efficient Edge Memory-and-Retrieval System for VLM-based Online Video Understanding
Dec 08, 2025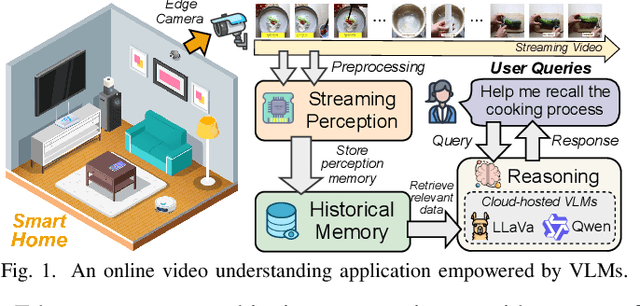
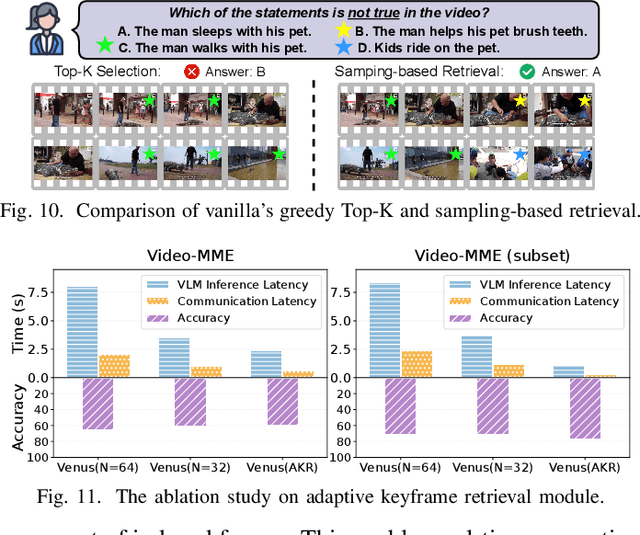
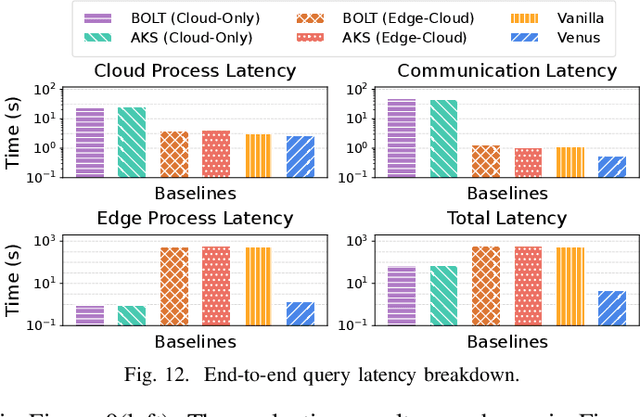
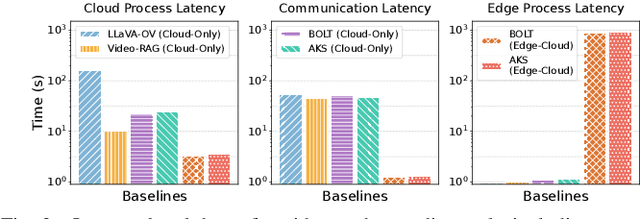
Vision-language models (VLMs) have demonstrated impressive multimodal comprehension capabilities and are being deployed in an increasing number of online video understanding applications. While recent efforts extensively explore advancing VLMs' reasoning power in these cases, deployment constraints are overlooked, leading to overwhelming system overhead in real-world deployments. To address that, we propose Venus, an on-device memory-and-retrieval system for efficient online video understanding. Venus proposes an edge-cloud disaggregated architecture that sinks memory construction and keyframe retrieval from cloud to edge, operating in two stages. In the ingestion stage, Venus continuously processes streaming edge videos via scene segmentation and clustering, where the selected keyframes are embedded with a multimodal embedding model to build a hierarchical memory for efficient storage and retrieval. In the querying stage, Venus indexes incoming queries from memory, and employs a threshold-based progressive sampling algorithm for keyframe selection that enhances diversity and adaptively balances system cost and reasoning accuracy. Our extensive evaluation shows that Venus achieves a 15x-131x speedup in total response latency compared to state-of-the-art methods, enabling real-time responses within seconds while maintaining comparable or even superior reasoning accuracy.
ContextAgent: Context-Aware Proactive LLM Agents with Open-World Sensory Perceptions
May 20, 2025Recent advances in Large Language Models (LLMs) have propelled intelligent agents from reactive responses to proactive support. While promising, existing proactive agents either rely exclusively on observations from enclosed environments (e.g., desktop UIs) with direct LLM inference or employ rule-based proactive notifications, leading to suboptimal user intent understanding and limited functionality for proactive service. In this paper, we introduce ContextAgent, the first context-aware proactive agent that incorporates extensive sensory contexts to enhance the proactive capabilities of LLM agents. ContextAgent first extracts multi-dimensional contexts from massive sensory perceptions on wearables (e.g., video and audio) to understand user intentions. ContextAgent then leverages the sensory contexts and the persona contexts from historical data to predict the necessity for proactive services. When proactive assistance is needed, ContextAgent further automatically calls the necessary tools to assist users unobtrusively. To evaluate this new task, we curate ContextAgentBench, the first benchmark for evaluating context-aware proactive LLM agents, covering 1,000 samples across nine daily scenarios and twenty tools. Experiments on ContextAgentBench show that ContextAgent outperforms baselines by achieving up to 8.5% and 6.0% higher accuracy in proactive predictions and tool calling, respectively. We hope our research can inspire the development of more advanced, human-centric, proactive AI assistants.
An LLM-Empowered Low-Resolution Vision System for On-Device Human Behavior Understanding
May 03, 2025The rapid advancements in Large Vision Language Models (LVLMs) offer the potential to surpass conventional labeling by generating richer, more detailed descriptions of on-device human behavior understanding (HBU) in low-resolution vision systems, such as depth, thermal, and infrared. However, existing large vision language model (LVLM) approaches are unable to understand low-resolution data well as they are primarily designed for high-resolution data, such as RGB images. A quick fixing approach is to caption a large amount of low-resolution data, but it requires a significant amount of labor-intensive annotation efforts. In this paper, we propose a novel, labor-saving system, Llambda, designed to support low-resolution HBU. The core idea is to leverage limited labeled data and a large amount of unlabeled data to guide LLMs in generating informative captions, which can be combined with raw data to effectively fine-tune LVLM models for understanding low-resolution videos in HBU. First, we propose a Contrastive-Oriented Data Labeler, which can capture behavior-relevant information from long, low-resolution videos and generate high-quality pseudo labels for unlabeled data via contrastive learning. Second, we propose a Physical-Knowledge Guided Captioner, which utilizes spatial and temporal consistency checks to mitigate errors in pseudo labels. Therefore, it can improve LLMs' understanding of sequential data and then generate high-quality video captions. Finally, to ensure on-device deployability, we employ LoRA-based efficient fine-tuning to adapt LVLMs for low-resolution data. We evaluate Llambda using a region-scale real-world testbed and three distinct low-resolution datasets, and the experiments show that Llambda outperforms several state-of-the-art LVLM systems up to $40.03\%$ on average Bert-Score.
Jupiter: Fast and Resource-Efficient Collaborative Inference of Generative LLMs on Edge Devices
Apr 11, 2025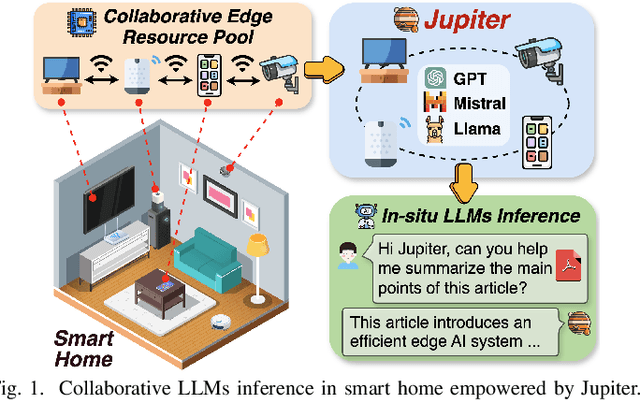
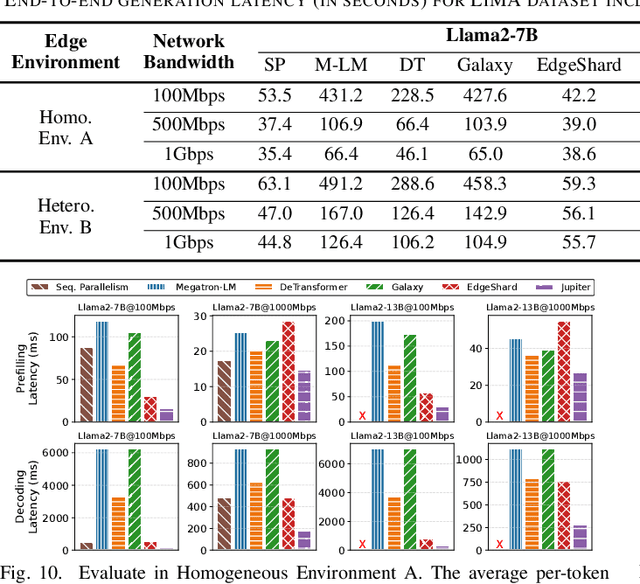
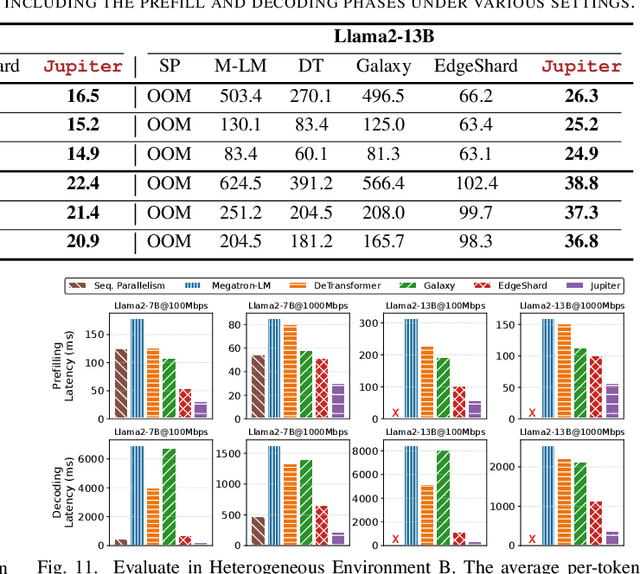
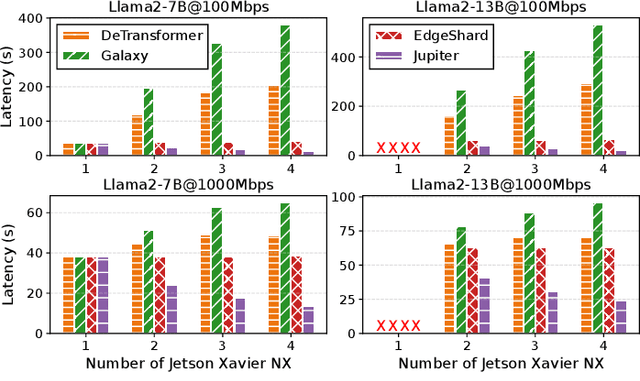
Generative large language models (LLMs) have garnered significant attention due to their exceptional capabilities in various AI tasks. Traditionally deployed in cloud datacenters, LLMs are now increasingly moving towards more accessible edge platforms to protect sensitive user data and ensure privacy preservation. The limited computational resources of individual edge devices, however, can result in excessively prolonged inference latency and overwhelmed memory usage. While existing research has explored collaborative edge computing to break the resource wall of individual devices, these solutions yet suffer from massive communication overhead and under-utilization of edge resources. Furthermore, they focus exclusively on optimizing the prefill phase, neglecting the crucial autoregressive decoding phase for generative LLMs. To address that, we propose Jupiter, a fast, scalable, and resource-efficient collaborative edge AI system for generative LLM inference. Jupiter introduces a flexible pipelined architecture as a principle and differentiates its system design according to the differentiated characteristics of the prefill and decoding phases. For prefill phase, Jupiter submits a novel intra-sequence pipeline parallelism and develops a meticulous parallelism planning strategy to maximize resource efficiency; For decoding, Jupiter devises an effective outline-based pipeline parallel decoding mechanism combined with speculative decoding, which further magnifies inference acceleration. Extensive evaluation based on realistic implementation demonstrates that Jupiter remarkably outperforms state-of-the-art approaches under various edge environment setups, achieving up to 26.1x end-to-end latency reduction while rendering on-par generation quality.
Pluto and Charon: A Time and Memory Efficient Collaborative Edge AI Framework for Personal LLMs Fine-Tuning
Aug 20, 2024Large language models (LLMs) have unlocked a plethora of powerful applications at the network edge, such as intelligent personal assistants. Data privacy and security concerns have prompted a shift towards edge-based fine-tuning of personal LLMs, away from cloud reliance. However, this raises issues of computational intensity and resource scarcity, hindering training efficiency and feasibility. While current studies investigate parameter-efficient fine-tuning (PEFT) techniques to mitigate resource constraints, our analysis indicates that these techniques are not sufficiently resource-efficient for edge devices. To tackle these challenges, we propose Pluto and Charon (PAC), a time and memory efficient collaborative edge AI framework for personal LLMs fine-tuning. PAC breaks the resource wall of personal LLMs fine-tuning with a sophisticated algorithm-system co-design. (1) Algorithmically, PAC implements a personal LLMs fine-tuning technique that is efficient in terms of parameters, time, and memory. It utilizes Parallel Adapters to circumvent the need for a full backward pass through the LLM backbone. Additionally, an activation cache mechanism further streamlining the process by negating the necessity for repeated forward passes across multiple epochs. (2) Systematically, PAC leverages edge devices in close proximity, pooling them as a collective resource for in-situ personal LLMs fine-tuning, utilizing a hybrid data and pipeline parallelism to orchestrate distributed training. The use of the activation cache eliminates the need for forward pass through the LLM backbone,enabling exclusive fine-tuning of the Parallel Adapters using data parallelism. Extensive evaluation based on prototype implementation demonstrates that PAC remarkably outperforms state-of-the-art approaches, achieving up to 8.64x end-to-end speedup and up to 88.16% reduction in memory footprint.
Asteroid: Resource-Efficient Hybrid Pipeline Parallelism for Collaborative DNN Training on Heterogeneous Edge Devices
Aug 15, 2024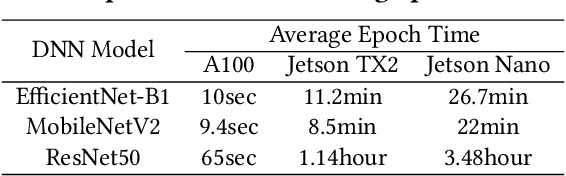
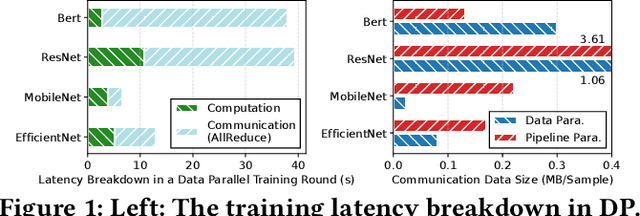
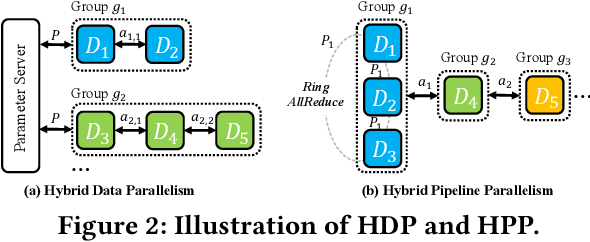

On-device Deep Neural Network (DNN) training has been recognized as crucial for privacy-preserving machine learning at the edge. However, the intensive training workload and limited onboard computing resources pose significant challenges to the availability and efficiency of model training. While existing works address these challenges through native resource management optimization, we instead leverage our observation that edge environments usually comprise a rich set of accompanying trusted edge devices with idle resources beyond a single terminal. We propose Asteroid, a distributed edge training system that breaks the resource walls across heterogeneous edge devices for efficient model training acceleration. Asteroid adopts a hybrid pipeline parallelism to orchestrate distributed training, along with a judicious parallelism planning for maximizing throughput under certain resource constraints. Furthermore, a fault-tolerant yet lightweight pipeline replay mechanism is developed to tame the device-level dynamics for training robustness and performance stability. We implement Asteroid on heterogeneous edge devices with both vision and language models, demonstrating up to 12.2x faster training than conventional parallelism methods and 2.1x faster than state-of-the-art hybrid parallelism methods through evaluations. Furthermore, Asteroid can recover training pipeline 14x faster than baseline methods while preserving comparable throughput despite unexpected device exiting and failure.
FlocOff: Data Heterogeneity Resilient Federated Learning with Communication-Efficient Edge Offloading
May 29, 2024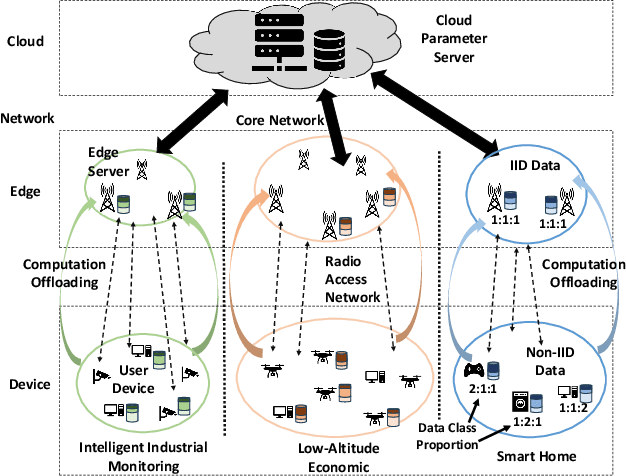
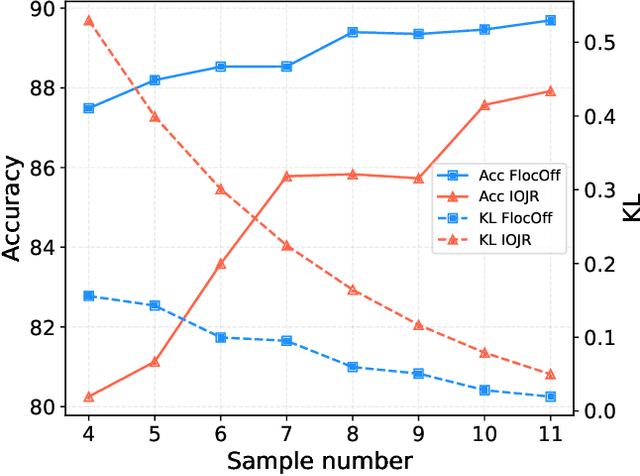
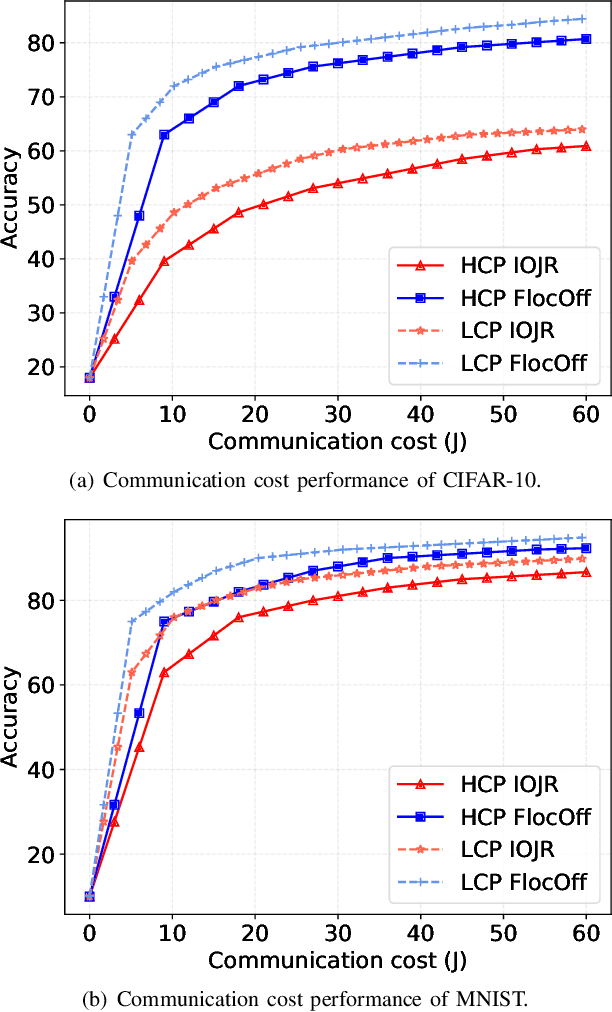
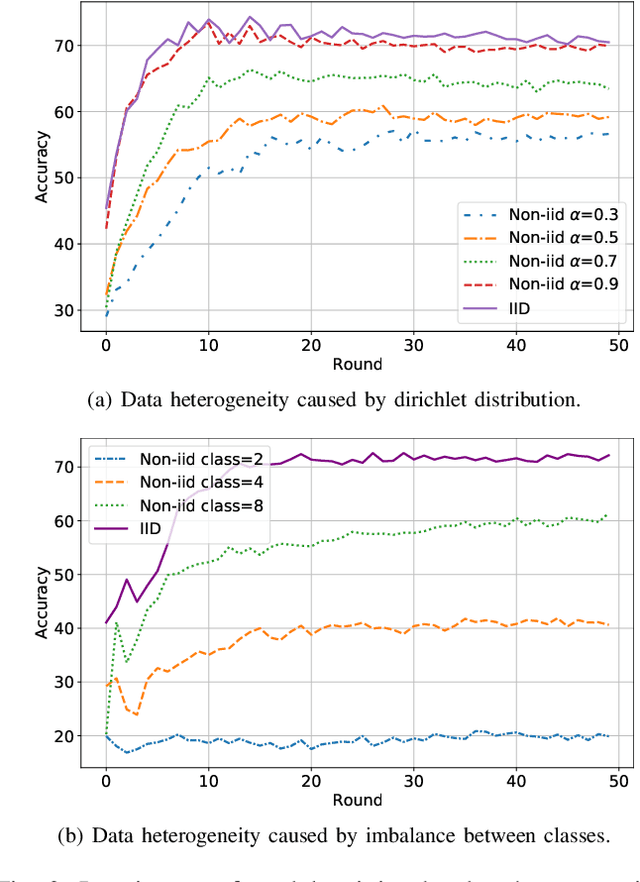
Federated Learning (FL) has emerged as a fundamental learning paradigm to harness massive data scattered at geo-distributed edge devices in a privacy-preserving way. Given the heterogeneous deployment of edge devices, however, their data are usually Non-IID, introducing significant challenges to FL including degraded training accuracy, intensive communication costs, and high computing complexity. Towards that, traditional approaches typically utilize adaptive mechanisms, which may suffer from scalability issues, increased computational overhead, and limited adaptability to diverse edge environments. To address that, this paper instead leverages the observation that the computation offloading involves inherent functionalities such as node matching and service correlation to achieve data reshaping and proposes Federated learning based on computing Offloading (FlocOff) framework, to address data heterogeneity and resource-constrained challenges. Specifically, FlocOff formulates the FL process with Non-IID data in edge scenarios and derives rigorous analysis on the impact of imbalanced data distribution. Based on this, FlocOff decouples the optimization in two steps, namely : (1) Minimizes the Kullback-Leibler (KL) divergence via Computation Offloading scheduling (MKL-CO); (2) Minimizes the Communication Cost through Resource Allocation (MCC-RA). Extensive experimental results demonstrate that the proposed FlocOff effectively improves model convergence and accuracy by 14.3\%-32.7\% while reducing data heterogeneity under various data distributions.
Galaxy: A Resource-Efficient Collaborative Edge AI System for In-situ Transformer Inference
May 27, 2024



Transformer-based models have unlocked a plethora of powerful intelligent applications at the edge, such as voice assistant in smart home. Traditional deployment approaches offload the inference workloads to the remote cloud server, which would induce substantial pressure on the backbone network as well as raise users' privacy concerns. To address that, in-situ inference has been recently recognized for edge intelligence, but it still confronts significant challenges stemming from the conflict between intensive workloads and limited on-device computing resources. In this paper, we leverage our observation that many edge environments usually comprise a rich set of accompanying trusted edge devices with idle resources and propose Galaxy, a collaborative edge AI system that breaks the resource walls across heterogeneous edge devices for efficient Transformer inference acceleration. Galaxy introduces a novel hybrid model parallelism to orchestrate collaborative inference, along with a heterogeneity-aware parallelism planning for fully exploiting the resource potential. Furthermore, Galaxy devises a tile-based fine-grained overlapping of communication and computation to mitigate the impact of tensor synchronizations on inference latency under bandwidth-constrained edge environments. Extensive evaluation based on prototype implementation demonstrates that Galaxy remarkably outperforms state-of-the-art approaches under various edge environment setups, achieving up to 2.5x end-to-end latency reduction.
Implementation of Big AI Models for Wireless Networks with Collaborative Edge Computing
Apr 27, 2024



Big Artificial Intelligence (AI) models have emerged as a crucial element in various intelligent applications at the edge, such as voice assistants in smart homes and autonomous robotics in smart factories. Training big AI models, e.g., for personalized fine-tuning and continual model refinement, poses significant challenges to edge devices due to the inherent conflict between limited computing resources and intensive workload associated with training. Despite the constraints of on-device training, traditional approaches usually resort to aggregating training data and sending it to a remote cloud for centralized training. Nevertheless, this approach is neither sustainable, which strains long-range backhaul transmission and energy-consuming datacenters, nor safely private, which shares users' raw data with remote infrastructures. To address these challenges, we alternatively observe that prevalent edge environments usually contain a diverse collection of trusted edge devices with untapped idle resources, which can be leveraged for edge training acceleration. Motivated by this, in this article, we propose collaborative edge training, a novel training mechanism that orchestrates a group of trusted edge devices as a resource pool for expedited, sustainable big AI model training at the edge. As an initial step, we present a comprehensive framework for building collaborative edge training systems and analyze in-depth its merits and sustainable scheduling choices following its workflow. To further investigate the impact of its parallelism design, we empirically study a case of four typical parallelisms from the perspective of energy demand with realistic testbeds. Finally, we discuss open challenges for sustainable collaborative edge training to point to future directions of edge-centric big AI model training.