 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPET: a universal network for high-quality PET image denoising across varied dose reduction factors
Jun 09, 2026Most existing deep learning-based PET image denoising methods assume a fixed and known dose reduction factor (DRF) for low-dose PET images. However, these methods encounter significant performance degradation when the DRF varies beyond the assumed one in practical applications. To address the challenge posed by varied DRFs, several preliminary studies focus on the task of universal PET image denoising, aiming to train a universal model over low-dose data across DRFs. Nonetheless, these vanilla universal models often struggle with misaligned styles present in different DRF data, leading to the \textit{style elimination issue} with a significant over-smoothing effect. To deal with this issue, we innovatively introduce domain generalization to PET image denoising and propose a universal PET image denoising network (UniPET) to achieve high-quality PET image denoising across diverse DRFs. UniPET comprises two primary innovations: a style alignment network (SAN) and a region-aware learning strategy (RALS). Specifically, SAN utilizes style alignment techniques derived from domain generalization to align and recover styles across different DRFs, ensuring the model's generalizability across various DRFs while effectively preserving styles. Furthermore, to enhance style recovery, RALS distinguishes between flat and stylized regions, exclusively conducting adversarial learning on the latter, thereby more effectively guiding the model's focus towards learning stylized regions. It is demonstrated that our proposed UniPET can adaptively recover different DRF styles and achieve high-quality PET image denoising across DRFs. Comprehensive experiments show that UniPET exhibits comparable performance to individual DRF-specific models at specific DRFs and realizes state-of-the-art performance in universal PET image denoising quantitatively, perceptually, and clinically.
Region Attention Transformer for Medical Image Restoration
Jul 12, 2024



Transformer-based methods have demonstrated impressive results in medical image restoration, attributed to the multi-head self-attention (MSA) mechanism in the spatial dimension. However, the majority of existing Transformers conduct attention within fixed and coarsely partitioned regions (\text{e.g.} the entire image or fixed patches), resulting in interference from irrelevant regions and fragmentation of continuous image content. To overcome these challenges, we introduce a novel Region Attention Transformer (RAT) that utilizes a region-based multi-head self-attention mechanism (R-MSA). The R-MSA dynamically partitions the input image into non-overlapping semantic regions using the robust Segment Anything Model (SAM) and then performs self-attention within these regions. This region partitioning is more flexible and interpretable, ensuring that only pixels from similar semantic regions complement each other, thereby eliminating interference from irrelevant regions. Moreover, we introduce a focal region loss to guide our model to adaptively focus on recovering high-difficulty regions. Extensive experiments demonstrate the effectiveness of RAT in various medical image restoration tasks, including PET image synthesis, CT image denoising, and pathological image super-resolution. Code is available at \href{https://github.com/Yaziwel/Region-Attention-Transformer-for-Medical-Image-Restoration.git}{https://github.com/RAT}.
All-In-One Medical Image Restoration via Task-Adaptive Routing
May 30, 2024



Although single-task medical image restoration (MedIR) has witnessed remarkable success, the limited generalizability of these methods poses a substantial obstacle to wider application. In this paper, we focus on the task of all-in-one medical image restoration, aiming to address multiple distinct MedIR tasks with a single universal model. Nonetheless, due to significant differences between different MedIR tasks, training a universal model often encounters task interference issues, where different tasks with shared parameters may conflict with each other in the gradient update direction. This task interference leads to deviation of the model update direction from the optimal path, thereby affecting the model's performance. To tackle this issue, we propose a task-adaptive routing strategy, allowing conflicting tasks to select different network paths in spatial and channel dimensions, thereby mitigating task interference. Experimental results demonstrate that our proposed \textbf{A}ll-in-one \textbf{M}edical \textbf{I}mage \textbf{R}estoration (\textbf{AMIR}) network achieves state-of-the-art performance in three MedIR tasks: MRI super-resolution, CT denoising, and PET synthesis, both in single-task and all-in-one settings. The code and data will be available at \href{https://github.com/Yaziwel/All-In-One-Medical-Image-Restoration-via-Task-Adaptive-Routing.git}{https://github.com/Yaziwel/AMIR}.
Graph Neural Network based Double Machine Learning Estimator of Network Causal Effects
Mar 17, 2024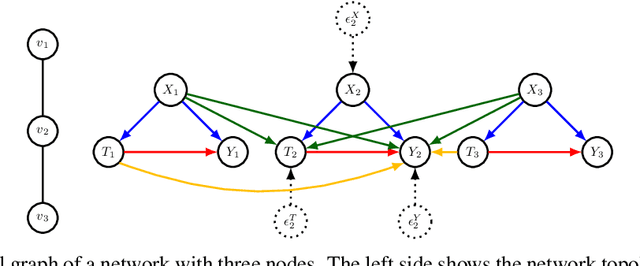



Our paper addresses the challenge of inferring causal effects in social network data, characterized by complex interdependencies among individuals resulting in challenges such as non-independence of units, interference (where a unit's outcome is affected by neighbors' treatments), and introduction of additional confounding factors from neighboring units. We propose a novel methodology combining graph neural networks and double machine learning, enabling accurate and efficient estimation of direct and peer effects using a single observational social network. Our approach utilizes graph isomorphism networks in conjunction with double machine learning to effectively adjust for network confounders and consistently estimate the desired causal effects. We demonstrate that our estimator is both asymptotically normal and semiparametrically efficient. A comprehensive evaluation against four state-of-the-art baseline methods using three semi-synthetic social network datasets reveals our method's on-par or superior efficacy in precise causal effect estimation. Further, we illustrate the practical application of our method through a case study that investigates the impact of Self-Help Group participation on financial risk tolerance. The results indicate a significant positive direct effect, underscoring the potential of our approach in social network analysis. Additionally, we explore the effects of network sparsity on estimation performance.
A3D: Adaptive, Accurate, and Autonomous Navigation for Edge-Assisted Drones
Jul 19, 2023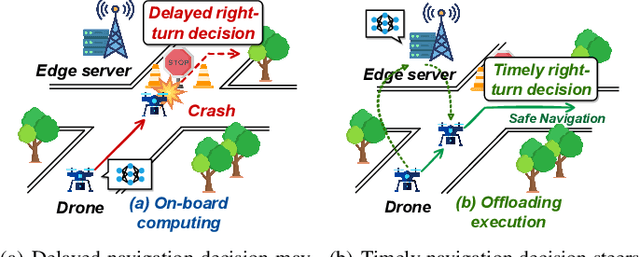
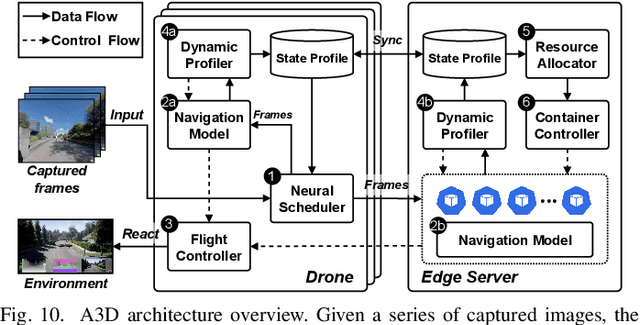
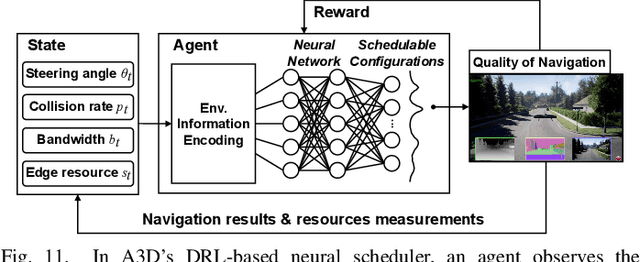
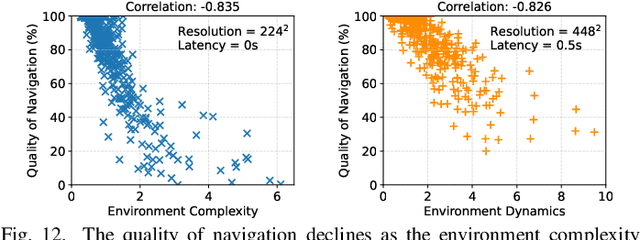
Accurate navigation is of paramount importance to ensure flight safety and efficiency for autonomous drones. Recent research starts to use Deep Neural Networks to enhance drone navigation given their remarkable predictive capability for visual perception. However, existing solutions either run DNN inference tasks on drones in situ, impeded by the limited onboard resource, or offload the computation to external servers which may incur large network latency. Few works consider jointly optimizing the offloading decisions along with image transmission configurations and adapting them on the fly. In this paper, we propose A3D, an edge server assisted drone navigation framework that can dynamically adjust task execution location, input resolution, and image compression ratio in order to achieve low inference latency, high prediction accuracy, and long flight distances. Specifically, we first augment state-of-the-art convolutional neural networks for drone navigation and define a novel metric called Quality of Navigation as our optimization objective which can effectively capture the above goals. We then design a deep reinforcement learning based neural scheduler at the drone side for which an information encoder is devised to reshape the state features and thus improve its learning ability. To further support simultaneous multi-drone serving, we extend the edge server design by developing a network-aware resource allocation algorithm, which allows provisioning containerized resources aligned with drones' demand. We finally implement a proof-of-concept prototype with realistic devices and validate its performance in a real-world campus scene, as well as a simulation environment for thorough evaluation upon AirSim. Extensive experimental results show that A3D can reduce end-to-end latency by 28.06% and extend the flight distance by up to 27.28% compared with non-adaptive solutions.
Knowledge Distillation for Mobile Edge Computation Offloading
Apr 09, 2020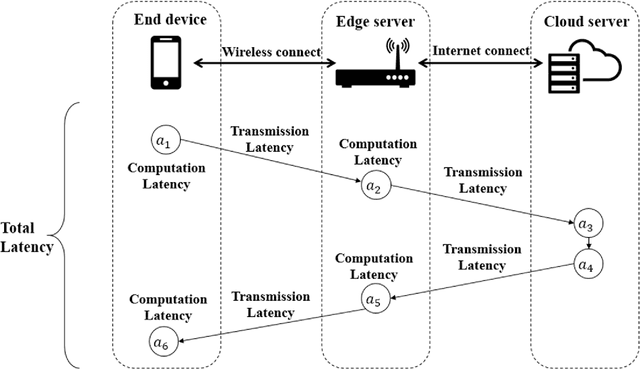

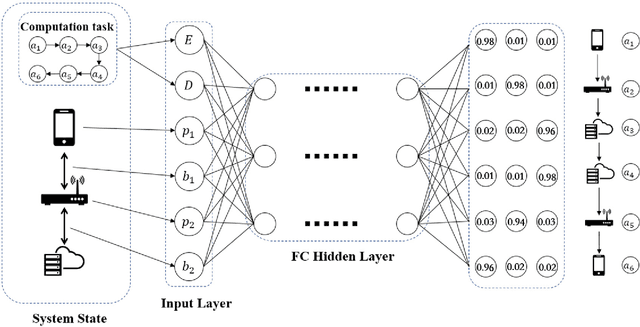
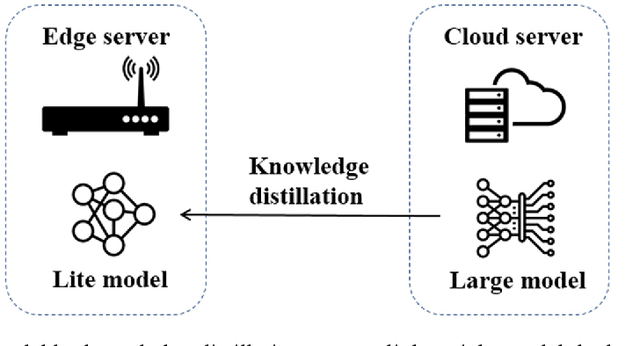
Edge computation offloading allows mobile end devices to put execution of compute-intensive task on the edge servers. End devices can decide whether offload the tasks to edge servers, cloud servers or execute locally according to current network condition and devices' profile in an online manner. In this article, we propose an edge computation offloading framework based on Deep Imitation Learning (DIL) and Knowledge Distillation (KD), which assists end devices to quickly make fine-grained decisions to optimize the delay of computation tasks online. We formalize computation offloading problem into a multi-label classification problem. Training samples for our DIL model are generated in an offline manner. After model is trained, we leverage knowledge distillation to obtain a lightweight DIL model, by which we further reduce the model's inference delay. Numerical experiment shows that the offloading decisions made by our model outperforms those made by other related policies in latency metric. Also, our model has the shortest inference delay among all policies.