 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Mobile Edge Computation Offloading
Paper and Code
Apr 09, 2020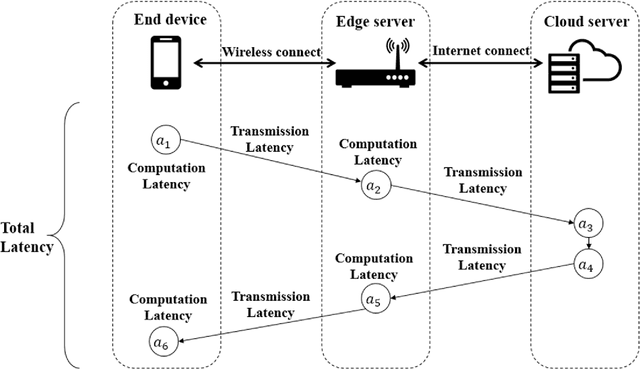

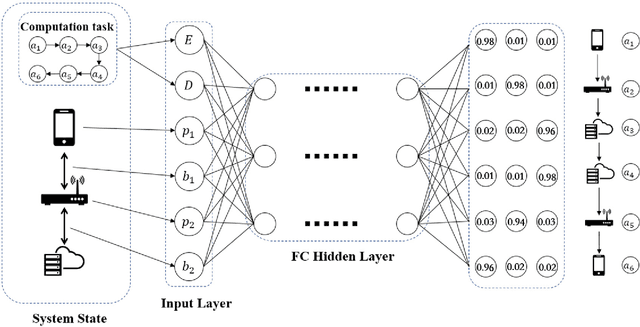
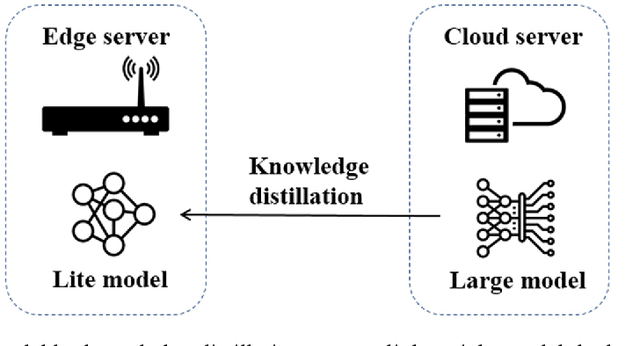
Edge computation offloading allows mobile end devices to put execution of compute-intensive task on the edge servers. End devices can decide whether offload the tasks to edge servers, cloud servers or execute locally according to current network condition and devices' profile in an online manner. In this article, we propose an edge computation offloading framework based on Deep Imitation Learning (DIL) and Knowledge Distillation (KD), which assists end devices to quickly make fine-grained decisions to optimize the delay of computation tasks online. We formalize computation offloading problem into a multi-label classification problem. Training samples for our DIL model are generated in an offline manner. After model is trained, we leverage knowledge distillation to obtain a lightweight DIL model, by which we further reduce the model's inference delay. Numerical experiment shows that the offloading decisions made by our model outperforms those made by other related policies in latency metric. Also, our model has the shortest inference delay among all policies.