 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mamba-based Network for Semi-supervised Singing Melody Extraction Using Confidence Binary Regularization
May 13, 2025Singing melody extraction (SME) is a key task in the field of music information retrieval. However, existing methods are facing several limitations: firstly, prior models use transformers to capture the contextual dependencies, which requires quadratic computation resulting in low efficiency in the inference stage. Secondly, prior works typically rely on frequencysupervised methods to estimate the fundamental frequency (f0), which ignores that the musical performance is actually based on notes. Thirdly, transformers typically require large amounts of labeled data to achieve optimal performances, but the SME task lacks of sufficient annotated data. To address these issues, in this paper, we propose a mamba-based network, called SpectMamba, for semi-supervised singing melody extraction using confidence binary regularization. In particular, we begin by introducing vision mamba to achieve computational linear complexity. Then, we propose a novel note-f0 decoder that allows the model to better mimic the musical performance. Further, to alleviate the scarcity of the labeled data, we introduce a confidence binary regularization (CBR) module to leverage the unlabeled data by maximizing the probability of the correct classes. The proposed method is evaluated on several public datasets and the conducted experiments demonstrate the effectiveness of our proposed method.
GUI Agents with Foundation Models: A Comprehensive Survey
Nov 07, 2024

Recent advances in foundation models, particularly Large Language Models (LLMs) and Multimodal Large Language Models (MLLMs), facilitate intelligent agents being capable of performing complex tasks. By leveraging the ability of (M)LLMs to process and interpret Graphical User Interfaces (GUIs), these agents can autonomously execute user instructions by simulating human-like interactions such as clicking and typing. This survey consolidates recent research on (M)LLM-based GUI agents, highlighting key innovations in data, frameworks, and applications. We begin by discussing representative datasets and benchmarks. Next, we summarize a unified framework that captures the essential components used in prior research, accompanied by a taxonomy. Additionally, we explore commercial applications of (M)LLM-based GUI agents. Drawing from existing work, we identify several key challenges and propose future research directions. We hope this paper will inspire further developments in the field of (M)LLM-based GUI agents.
Underwater Image Enhancement via Dehazing and Color Restoration
Sep 15, 2024


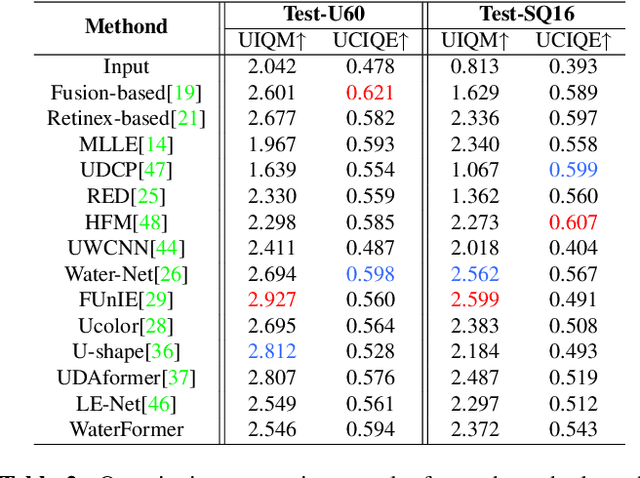
With the rapid development of marine engineering projects such as marine resource extraction and oceanic surveys, underwater visual imaging and analysis has become a critical technology. Unfortunately, due to the inevitable non-linear attenuation of light in underwater environments, underwater images and videos often suffer from low contrast, blurriness, and color degradation, which significantly complicate the subsequent research. Existing underwater image enhancement methods often treat the haze and color cast as a unified degradation process and disregard their independence and interdependence, which limits the performance improvement. Here, we propose a Vision Transformer (ViT)-based network (referred to as WaterFormer) to improve the underwater image quality. WaterFormer contains three major components: a dehazing block (DehazeFormer Block) to capture the self-correlated haze features and extract deep-level features, a Color Restoration Block (CRB) to capture self-correlated color cast features, and a Channel Fusion Block (CFB) to capture fusion features within the network. To ensure authenticity, a soft reconstruction layer based on the underwater imaging physics model is included. To improve the quality of the enhanced images, we introduce the Chromatic Consistency Loss and Sobel Color Loss to train the network. Comprehensive experimental results demonstrate that WaterFormer outperforms other state-of-the-art methods in enhancing underwater images.
ToolACE: Winning the Points of LLM Function Calling
Sep 02, 2024



Function calling significantly extends the application boundary of large language models, where high-quality and diverse training data is critical for unlocking this capability. However, real function-calling data is quite challenging to collect and annotate, while synthetic data generated by existing pipelines tends to lack coverage and accuracy. In this paper, we present ToolACE, an automatic agentic pipeline designed to generate accurate, complex, and diverse tool-learning data. ToolACE leverages a novel self-evolution synthesis process to curate a comprehensive API pool of 26,507 diverse APIs. Dialogs are further generated through the interplay among multiple agents, guided by a formalized thinking process. To ensure data accuracy, we implement a dual-layer verification system combining rule-based and model-based checks. We demonstrate that models trained on our synthesized data, even with only 8B parameters, achieve state-of-the-art performance on the Berkeley Function-Calling Leaderboard, rivaling the latest GPT-4 models. Our model and a subset of the data are publicly available at https://huggingface.co/Team-ACE.
Is Translation Helpful? An Empirical Analysis of Cross-Lingual Transfer in Low-Resource Dialog Generation
May 21, 2023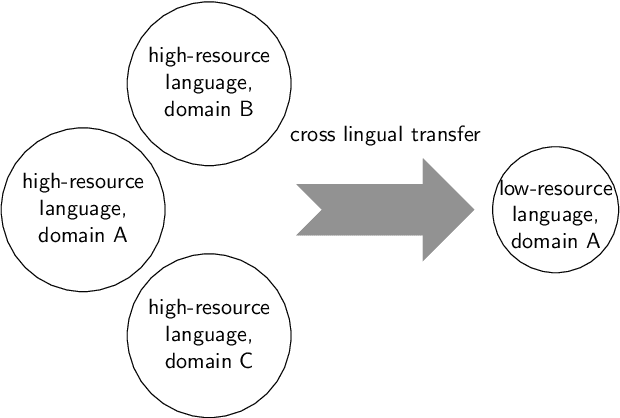
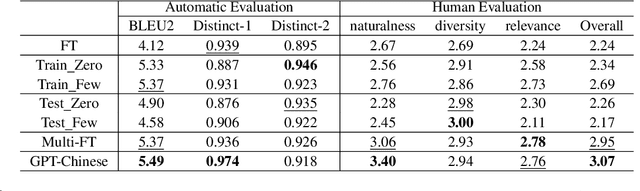
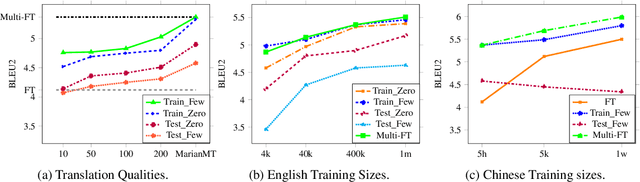

Cross-lingual transfer is important for developing high-quality chatbots in multiple languages due to the strongly imbalanced distribution of language resources. A typical approach is to leverage off-the-shelf machine translation (MT) systems to utilize either the training corpus or developed models from high-resource languages. In this work, we investigate whether it is helpful to utilize MT at all in this task. To do so, we simulate a low-resource scenario assuming access to limited Chinese dialog data in the movie domain and large amounts of English dialog data from multiple domains. Experiments show that leveraging English dialog corpora can indeed improve the naturalness, relevance and cross-domain transferability in Chinese. However, directly using English dialog corpora in its original form, surprisingly, is better than using its translated version. As the topics and wording habits in daily conversations are strongly culture-dependent, MT can reinforce the bias from high-resource languages, yielding unnatural generations in the target language. Considering the cost of translating large amounts of text and the strong effects of the translation quality, we suggest future research should rather focus on utilizing the original English data for cross-lingual transfer in dialog generation. We perform extensive human evaluations and ablation studies. The analysis results, together with the collected dataset, are presented to draw attention towards this area and benefit future research.
Olive Branch Learning: A Topology-Aware Federated Learning Framework for Space-Air-Ground Integrated Network
Dec 02, 2022The space-air-ground integrated network (SAGIN), one of the key technologies for next-generation mobile communication systems, can facilitate data transmission for users all over the world, especially in some remote areas where vast amounts of informative data are collected by Internet of remote things (IoRT) devices to support various data-driven artificial intelligence (AI) services. However, training AI models centrally with the assistance of SAGIN faces the challenges of highly constrained network topology, inefficient data transmission, and privacy issues. To tackle these challenges, we first propose a novel topology-aware federated learning framework for the SAGIN, namely Olive Branch Learning (OBL). Specifically, the IoRT devices in the ground layer leverage their private data to perform model training locally, while the air nodes in the air layer and the ring-structured low earth orbit (LEO) satellite constellation in the space layer are in charge of model aggregation (synchronization) at different scales.To further enhance communication efficiency and inference performance of OBL, an efficient Communication and Non-IID-aware Air node-Satellite Assignment (CNASA) algorithm is designed by taking the data class distribution of the air nodes as well as their geographic locations into account. Furthermore, we extend our OBL framework and CNASA algorithm to adapt to more complex multi-orbit satellite networks. We analyze the convergence of our OBL framework and conclude that the CNASA algorithm contributes to the fast convergence of the global model. Extensive experiments based on realistic datasets corroborate the superior performance of our algorithm over the benchmark policies.
GNN at the Edge: Cost-Efficient Graph Neural Network Processing over Distributed Edge Servers
Oct 31, 2022Edge intelligence has arisen as a promising computing paradigm for supporting miscellaneous smart applications that rely on machine learning techniques. While the community has extensively investigated multi-tier edge deployment for traditional deep learning models (e.g. CNNs, RNNs), the emerging Graph Neural Networks (GNNs) are still under exploration, presenting a stark disparity to its broad edge adoptions such as traffic flow forecasting and location-based social recommendation. To bridge this gap, this paper formally studies the cost optimization for distributed GNN processing over a multi-tier heterogeneous edge network. We build a comprehensive modeling framework that can capture a variety of different cost factors, based on which we formulate a cost-efficient graph layout optimization problem that is proved to be NP-hard. Instead of trivially applying traditional data placement wisdom, we theoretically reveal the structural property of quadratic submodularity implicated in GNN's unique computing pattern, which motivates our design of an efficient iterative solution exploiting graph cuts. Rigorous analysis shows that it provides parameterized constant approximation ratio, guaranteed convergence, and exact feasibility. To tackle potential graph topological evolution in GNN processing, we further devise an incremental update strategy and an adaptive scheduling algorithm for lightweight dynamic layout optimization. Evaluations with real-world datasets and various GNN benchmarks demonstrate that our approach achieves superior performance over de facto baselines with more than 95.8% cost eduction in a fast convergence speed.
TONet: Tone-Octave Network for Singing Melody Extraction from Polyphonic Music
Feb 02, 2022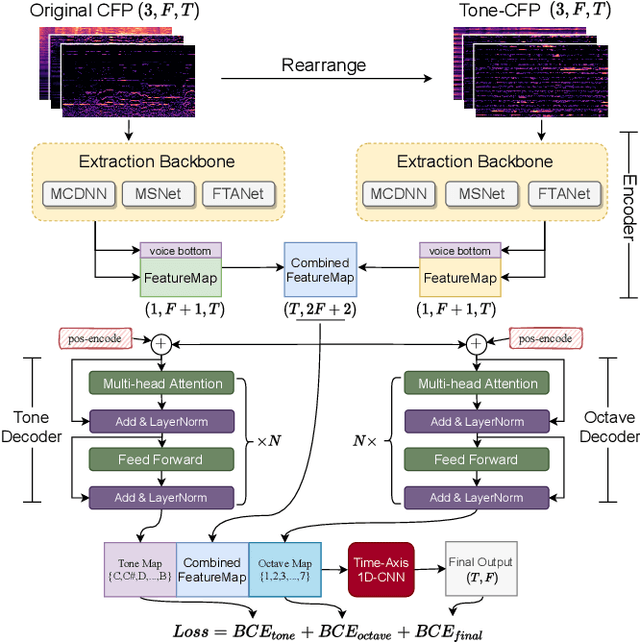
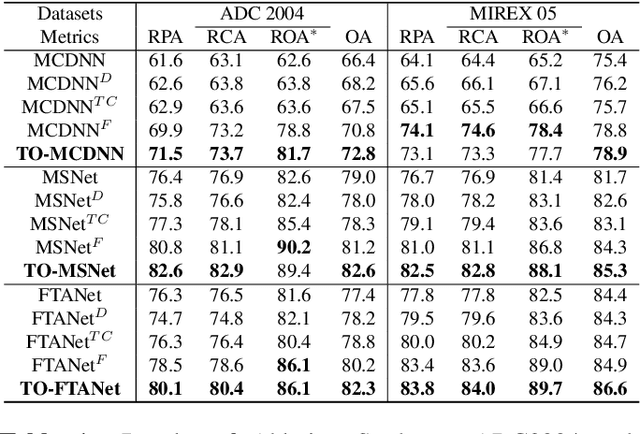
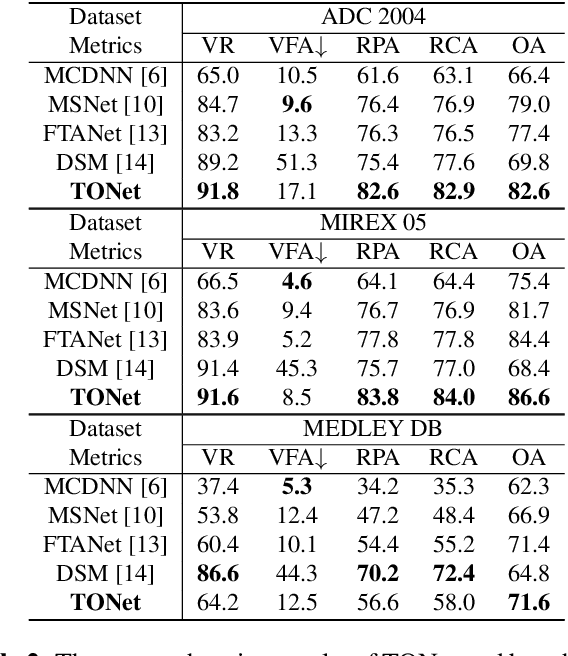
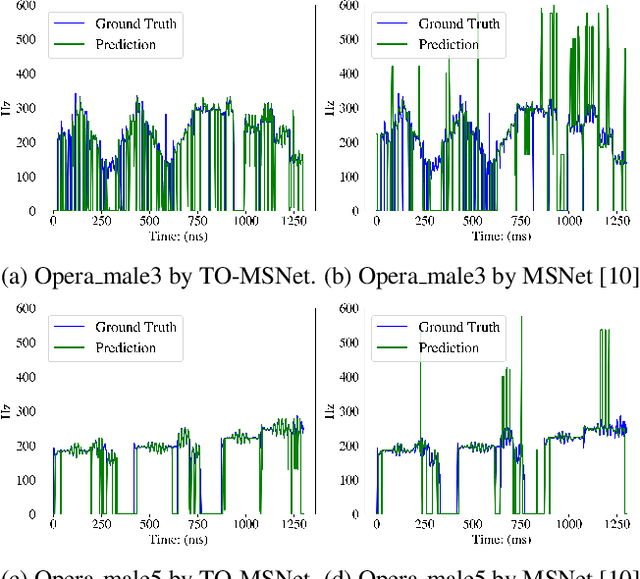
Singing melody extraction is an important problem in the field of music information retrieval. Existing methods typically rely on frequency-domain representations to estimate the sung frequencies. However, this design does not lead to human-level performance in the perception of melody information for both tone (pitch-class) and octave. In this paper, we propose TONet, a plug-and-play model that improves both tone and octave perceptions by leveraging a novel input representation and a novel network architecture. First, we present an improved input representation, the Tone-CFP, that explicitly groups harmonics via a rearrangement of frequency-bins. Second, we introduce an encoder-decoder architecture that is designed to obtain a salience feature map, a tone feature map, and an octave feature map. Third, we propose a tone-octave fusion mechanism to improve the final salience feature map. Experiments are done to verify the capability of TONet with various baseline backbone models. Our results show that tone-octave fusion with Tone-CFP can significantly improve the singing voice extraction performance across various datasets -- with substantial gains in octave and tone accuracy.
Edge Robotics: Edge-Computing-Accelerated Multi-Robot Simultaneous Localization and Mapping
Jan 24, 2022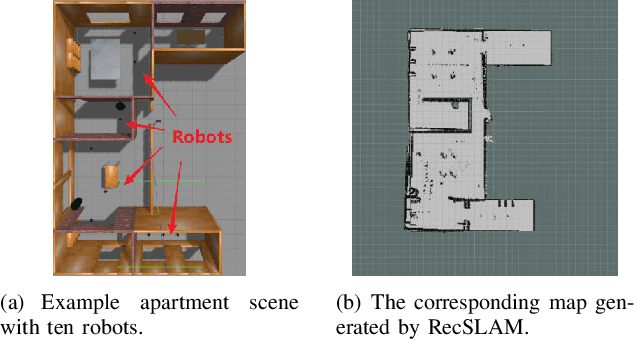


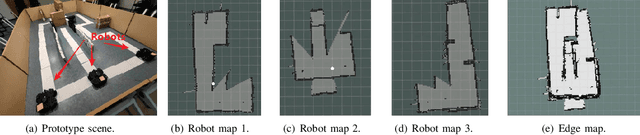
With the wide penetration of smart robots in multifarious fields, Simultaneous Localization and Mapping (SLAM) technique in robotics has attracted growing attention in the community. Yet collaborating SLAM over multiple robots still remains challenging due to performance contradiction between the intensive graphics computation of SLAM and the limited computing capability of robots. While traditional solutions resort to the powerful cloud servers acting as an external computation provider, we show by real-world measurements that the significant communication overhead in data offloading prevents its practicability to real deployment. To tackle these challenges, this paper promotes the emerging edge computing paradigm into multi-robot SLAM and proposes RecSLAM, a multi-robot laser SLAM system that focuses on accelerating map construction process under the robot-edge-cloud architecture. In contrast to conventional multi-robot SLAM that generates graphic maps on robots and completely merges them on the cloud, RecSLAM develops a hierarchical map fusion technique that directs robots' raw data to edge servers for real-time fusion and then sends to the cloud for global merging. To optimize the overall pipeline, an efficient multi-robot SLAM collaborative processing framework is introduced to adaptively optimize robot-to-edge offloading tailored to heterogeneous edge resource conditions, meanwhile ensuring the workload balancing among the edge servers. Extensive evaluations show RecSLAM can achieve up to 39% processing latency reduction over the state-of-the-art. Besides, a proof-of-concept prototype is developed and deployed in real scenes to demonstrate its effectiveness.
3D Vessel Reconstruction in OCT-Angiography via Depth Map Estimation
Feb 26, 2021
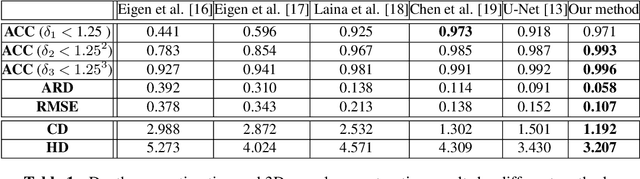
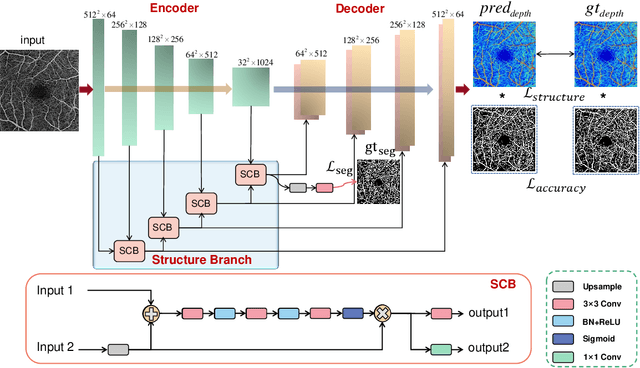
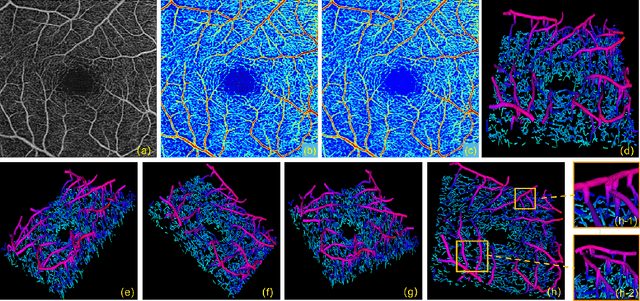
Optical Coherence Tomography Angiography (OCTA) has been increasingly used in the management of eye and systemic diseases in recent years. Manual or automatic analysis of blood vessel in 2D OCTA images (en face angiograms) is commonly used in clinical practice, however it may lose rich 3D spatial distribution information of blood vessels or capillaries that are useful for clinical decision-making. In this paper, we introduce a novel 3D vessel reconstruction framework based on the estimation of vessel depth maps from OCTA images. First, we design a network with structural constraints to predict the depth of blood vessels in OCTA images. In order to promote the accuracy of the predicted depth map at both the overall structure- and pixel- level, we combine MSE and SSIM loss as the training loss function. Finally, the 3D vessel reconstruction is achieved by utilizing the estimated depth map and 2D vessel segmentation results. Experimental results demonstrate that our method is effective in the depth prediction and 3D vessel reconstruction for OCTA images.% results may be used to guide subsequent vascular analysis