 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Translation Helpful? An Empirical Analysis of Cross-Lingual Transfer in Low-Resource Dialog Generation
Paper and Code
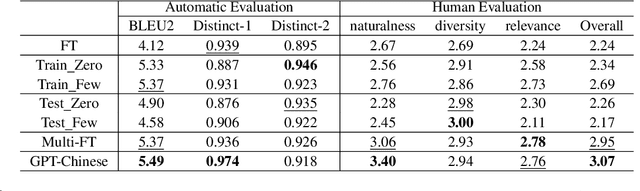
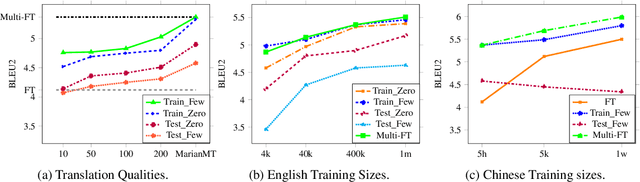

Cross-lingual transfer is important for developing high-quality chatbots in multiple languages due to the strongly imbalanced distribution of language resources. A typical approach is to leverage off-the-shelf machine translation (MT) systems to utilize either the training corpus or developed models from high-resource languages. In this work, we investigate whether it is helpful to utilize MT at all in this task. To do so, we simulate a low-resource scenario assuming access to limited Chinese dialog data in the movie domain and large amounts of English dialog data from multiple domains. Experiments show that leveraging English dialog corpora can indeed improve the naturalness, relevance and cross-domain transferability in Chinese. However, directly using English dialog corpora in its original form, surprisingly, is better than using its translated version. As the topics and wording habits in daily conversations are strongly culture-dependent, MT can reinforce the bias from high-resource languages, yielding unnatural generations in the target language. Considering the cost of translating large amounts of text and the strong effects of the translation quality, we suggest future research should rather focus on utilizing the original English data for cross-lingual transfer in dialog generation. We perform extensive human evaluations and ablation studies. The analysis results, together with the collected dataset, are presented to draw attention towards this area and benefit future research.