 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Is Prior Knowledge Helpful? Exploring the Evaluation and Selection of Unsupervised Pretext Tasks from a Neuro-Symbolic Perspective
Aug 10, 2025Neuro-symbolic (Nesy) learning improves the target task performance of models by enabling them to satisfy knowledge, while semi/self-supervised learning (SSL) improves the target task performance by designing unsupervised pretext tasks for unlabeled data to make models satisfy corresponding assumptions. We extend the Nesy theory based on reliable knowledge to the scenario of unreliable knowledge (i.e., assumptions), thereby unifying the theoretical frameworks of SSL and Nesy. Through rigorous theoretical analysis, we demonstrate that, in theory, the impact of pretext tasks on target performance hinges on three factors: knowledge learnability with respect to the model, knowledge reliability with respect to the data, and knowledge completeness with respect to the target. We further propose schemes to operationalize these theoretical metrics, and thereby develop a method that can predict the effectiveness of pretext tasks in advance. This will change the current status quo in practical applications, where the selections of unsupervised tasks are heuristic-based rather than theory-based, and it is difficult to evaluate the rationality of unsupervised pretext task selection before testing the model on the target task. In experiments, we verify a high correlation between the predicted performance-estimated using minimal data-and the actual performance achieved after large-scale semi-supervised or self-supervised learning, thus confirming the validity of the theory and the effectiveness of the evaluation method.
Quality-of-Service Aware LLM Routing for Edge Computing with Multiple Experts
Aug 01, 2025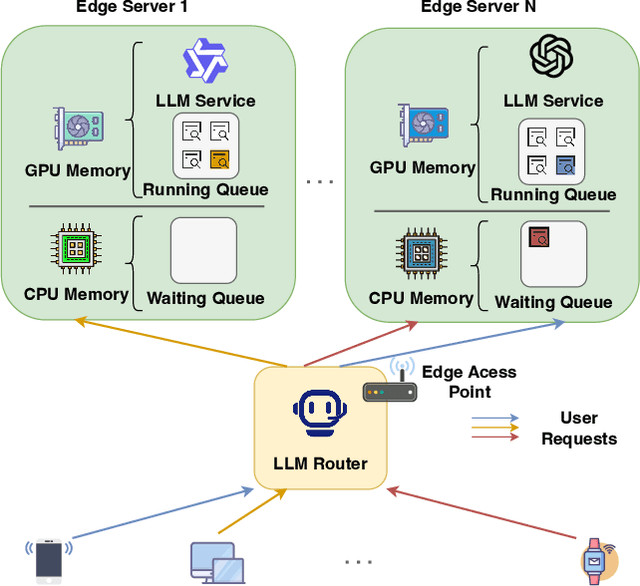
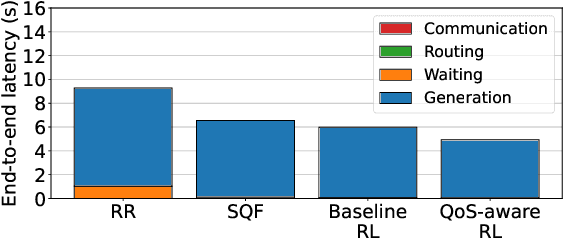
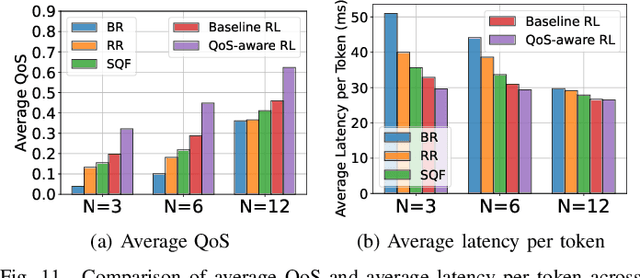
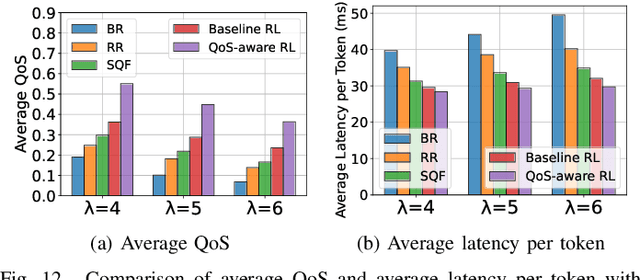
Large Language Models (LLMs) have demonstrated remarkable capabilities, leading to a significant increase in user demand for LLM services. However, cloud-based LLM services often suffer from high latency, unstable responsiveness, and privacy concerns. Therefore, multiple LLMs are usually deployed at the network edge to boost real-time responsiveness and protect data privacy, particularly for many emerging smart mobile and IoT applications. Given the varying response quality and latency of LLM services, a critical issue is how to route user requests from mobile and IoT devices to an appropriate LLM service (i.e., edge LLM expert) to ensure acceptable quality-of-service (QoS). Existing routing algorithms fail to simultaneously address the heterogeneity of LLM services, the interference among requests, and the dynamic workloads necessary for maintaining long-term stable QoS. To meet these challenges, in this paper we propose a novel deep reinforcement learning (DRL)-based QoS-aware LLM routing framework for sustained high-quality LLM services. Due to the dynamic nature of the global state, we propose a dynamic state abstraction technique to compactly represent global state features with a heterogeneous graph attention network (HAN). Additionally, we introduce an action impact estimator and a tailored reward function to guide the DRL agent in maximizing QoS and preventing latency violations. Extensive experiments on both Poisson and real-world workloads demonstrate that our proposed algorithm significantly improves average QoS and computing resource efficiency compared to existing baselines.
Automated Text-to-Table for Reasoning-Intensive Table QA: Pipeline Design and Benchmarking Insights
May 26, 2025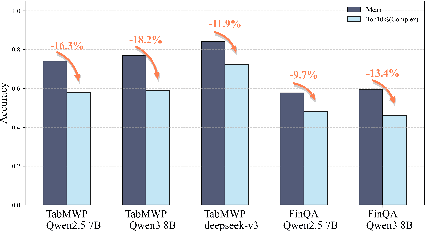
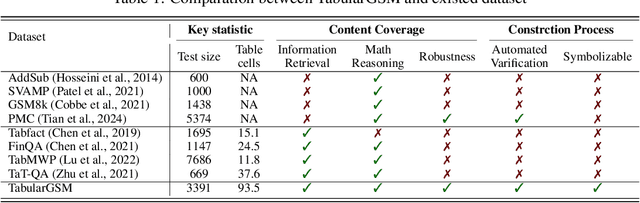
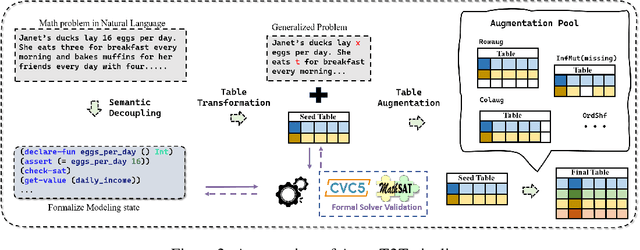

Reasoning with tabular data holds increasing importance in modern applications, yet comprehensive evaluation methodologies for reasoning-intensive Table Question Answering (QA) tasks remain nascent. Existing research is constrained by two primary bottlenecks: 1) Reliance on costly manually annotated real-world data, which is difficult to cover complex reasoning scenarios; 2) The heterogeneity of table structures hinders systematic analysis of the intrinsic mechanisms behind the underperformance of LLMs, especially in reasoning-intensive tasks. To address these issues, we propose an automated generation pipeline AutoT2T that transforms mathematical word problems into table-based reasoning tasks, eliminating the need for manual annotation. The pipeline can generate multiple variants of a table for the same reasoning problem, including noisy versions to support robustness evaluation. Based on this, we construct a new benchmark TabularGSM, which systematically spans a range of table complexities and trap problems. Experimental analyses through AutoT2T and TabularGSM reveal that the tight coupling between reasoning and retrieval or identification processes is a key factor underlying the failure of LLMs in complex Table QA tasks. This highlights the necessity for models to develop synergistic reasoning capabilities in order to perform effectively in complex Table QA tasks.
Realistic Evaluation of TabPFN v2 in Open Environments
May 22, 2025Tabular data, owing to its ubiquitous presence in real-world domains, has garnered significant attention in machine learning research. While tree-based models have long dominated tabular machine learning tasks, the recently proposed deep learning model TabPFN v2 has emerged, demonstrating unparalleled performance and scalability potential. Although extensive research has been conducted on TabPFN v2 to further improve performance, the majority of this research remains confined to closed environments, neglecting the challenges that frequently arise in open environments. This raises the question: Can TabPFN v2 maintain good performance in open environments? To this end, we conduct the first comprehensive evaluation of TabPFN v2's adaptability in open environments. We construct a unified evaluation framework covering various real-world challenges and assess the robustness of TabPFN v2 under open environments scenarios using this framework. Empirical results demonstrate that TabPFN v2 shows significant limitations in open environments but is suitable for small-scale, covariate-shifted, and class-balanced tasks. Tree-based models remain the optimal choice for general tabular tasks in open environments. To facilitate future research on open environments challenges, we advocate for open environments tabular benchmarks, multi-metric evaluation, and universal modules to strengthen model robustness. We publicly release our evaluation framework at https://anonymous.4open.science/r/tabpfn-ood-4E65.
NeSyGeo: A Neuro-Symbolic Framework for Multimodal Geometric Reasoning Data Generation
May 21, 2025Obtaining large-scale, high-quality data with reasoning paths is crucial for improving the geometric reasoning capabilities of multi-modal large language models (MLLMs). However, existing data generation methods, whether based on predefined templates or constrained symbolic provers, inevitably face diversity and numerical generalization limitations. To address these limitations, we propose NeSyGeo, a novel neuro-symbolic framework for generating geometric reasoning data. First, we propose a domain-specific language grounded in the entity-relation-constraint paradigm to comprehensively represent all components of plane geometry, along with generative actions defined within this symbolic space. We then design a symbolic-visual-text pipeline that synthesizes symbolic sequences, maps them to corresponding visual and textual representations, and generates diverse question-answer (Q&A) pairs using large language models (LLMs). To the best of our knowledge, we are the first to propose a neuro-symbolic approach in generating multimodal reasoning data. Based on this framework, we construct NeSyGeo-CoT and NeSyGeo-Caption datasets, containing 100k samples, and release a new benchmark NeSyGeo-Test for evaluating geometric reasoning abilities in MLLMs. Experiments demonstrate that the proposal significantly and consistently improves the performance of multiple MLLMs under both reinforcement and supervised fine-tuning. With only 4k samples and two epochs of reinforcement fine-tuning, base models achieve improvements of up to +15.8% on MathVision, +8.4% on MathVerse, and +7.3% on GeoQA. Notably, a 4B model can be improved to outperform an 8B model from the same series on geometric reasoning tasks.
Injecting Adrenaline into LLM Serving: Boosting Resource Utilization and Throughput via Attention Disaggregation
Mar 26, 2025In large language model (LLM) serving systems, executing each request consists of two phases: the compute-intensive prefill phase and the memory-intensive decoding phase. To prevent performance interference between the two phases, current LLM serving systems typically adopt prefill-decoding disaggregation, where the two phases are split across separate machines. However, we observe this approach leads to significant resource underutilization. Specifically, prefill instances that are compute-intensive suffer from low memory utilization, while decoding instances that are memory-intensive experience low compute utilization. To address this problem, this paper proposes Adrenaline, an attention disaggregation and offloading mechanism designed to enhance resource utilization and performance in LLM serving systems. Adrenaline's key innovation lies in disaggregating part of the attention computation in the decoding phase and offloading them to prefill instances. The memory-bound nature of decoding-phase attention computation inherently enables an effective offloading strategy, yielding two complementary advantages: 1) improved memory capacity and bandwidth utilization in prefill instances, and 2) increased decoding batch sizes that enhance compute utilization in decoding instances, collectively boosting overall system performance. Adrenaline achieves these gains through three key techniques: low-latency decoding synchronization, resource-efficient prefill colocation, and load-aware offloading scheduling. Experimental results show that Adrenaline achieves 2.28x higher memory capacity and 2.07x better memory bandwidth utilization in prefill instances, up to 1.67x improvements in compute utilization for decoding instances, and 1.68x higher overall inference throughput compared to state-of-the-art systems.
Micro Text Classification Based on Balanced Positive-Unlabeled Learning
Mar 17, 2025



In real-world text classification tasks, negative texts often contain a minimal proportion of negative content, which is especially problematic in areas like text quality control, legal risk screening, and sensitive information interception. This challenge manifests at two levels: at the macro level, distinguishing negative texts is difficult due to the high similarity between coarse-grained positive and negative samples; at the micro level, the issue stems from extreme class imbalance and a lack of fine-grained labels. To address these challenges, we propose transforming the coarse-grained positive-negative (PN) classification task into an imbalanced fine-grained positive-unlabeled (PU) classification problem, supported by theoretical analysis. We introduce a novel framework, Balanced Fine-Grained Positive-Unlabeled (BFGPU) learning, which features a unique PU learning loss function that optimizes macro-level performance amidst severe imbalance at the micro level. The framework's performance is further boosted by rebalanced pseudo-labeling and threshold adjustment. Extensive experiments on both public and real-world datasets demonstrate the effectiveness of BFGPU, which outperforms other methods, even in extreme scenarios where both macro and micro levels are highly imbalanced.
A Smooth Transition Between Induction and Deduction: Fast Abductive Learning Based on Probabilistic Symbol Perception
Feb 18, 2025Abductive learning (ABL) that integrates strengths of machine learning and logical reasoning to improve the learning generalization, has been recently shown effective. However, its efficiency is affected by the transition between numerical induction and symbolical deduction, leading to high computational costs in the worst-case scenario. Efforts on this issue remain to be limited. In this paper, we identified three reasons why previous optimization algorithms for ABL were not effective: insufficient utilization of prediction, symbol relationships, and accumulated experience in successful abductive processes, resulting in redundant calculations to the knowledge base. To address these challenges, we introduce an optimization algorithm named as Probabilistic Symbol Perception (PSP), which makes a smooth transition between induction and deduction and keeps the correctness of ABL unchanged. We leverage probability as a bridge and present an efficient data structure, achieving the transfer from a continuous probability sequence to discrete Boolean sequences with low computational complexity. Experiments demonstrate the promising results.
LawGPT: Knowledge-Guided Data Generation and Its Application to Legal LLM
Feb 10, 2025



Large language models (LLMs), both proprietary and open-source, have demonstrated remarkable capabilities across various natural language processing tasks. However, they face significant limitations in legal reasoning tasks. Proprietary models introduce data privacy risks and high inference costs, while open-source models underperform due to insufficient legal domain training data. To address these limitations, we study data generation for legal reasoning to improve the legal reasoning performance of open-source LLMs with the help of proprietary LLMs. This is challenging due to the lack of legal knowledge in proprietary LLMs and the difficulty in verifying the generated data. We propose KgDG, a knowledge-guided data generation framework for legal reasoning. Our framework enables leveraging legal knowledge to enhance generation diversity and introduces a refinement and verification process to ensure the quality of generated data. Moreover, we expand the generated dataset to further enhance the LLM reasoning capabilities. Using KgDG, we create a synthetic legal reasoning dataset containing 50K high-quality examples. Our trained model LawGPT outperforms existing legal-specific LLMs and achieves performance comparable to proprietary LLMs, demonstrating the effectiveness of KgDG and LawGPT. Our code and resources is publicly available at https://anonymous.4open.science/r/KgDG-45F5 .
Step Back to Leap Forward: Self-Backtracking for Boosting Reasoning of Language Models
Feb 06, 2025



The integration of slow-thinking mechanisms into large language models (LLMs) offers a promising way toward achieving Level 2 AGI Reasoners, as exemplified by systems like OpenAI's o1. However, several significant challenges remain, including inefficient overthinking and an overreliance on auxiliary reward models. We point out that these limitations stem from LLMs' inability to internalize the search process, a key component of effective reasoning. A critical step toward addressing this issue is enabling LLMs to autonomously determine when and where to backtrack, a fundamental operation in traditional search algorithms. To this end, we propose a self-backtracking mechanism that equips LLMs with the ability to backtrack during both training and inference. This mechanism not only enhances reasoning ability but also efficiency by transforming slow-thinking processes into fast-thinking through self-improvement. Empirical evaluations demonstrate that our proposal significantly enhances the reasoning capabilities of LLMs, achieving a performance gain of over 40 percent compared to the optimal-path supervised fine-tuning method. We believe this study introduces a novel and promising pathway for developing more advanced and robust Reasoners.