 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Text-to-Table for Reasoning-Intensive Table QA: Pipeline Design and Benchmarking Insights
May 26, 2025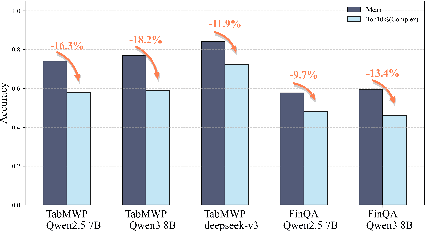
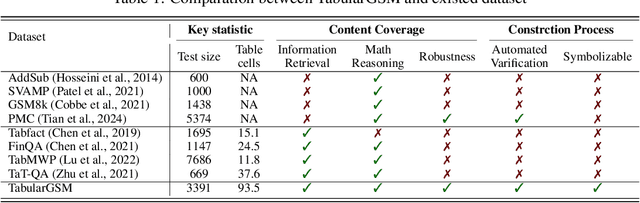
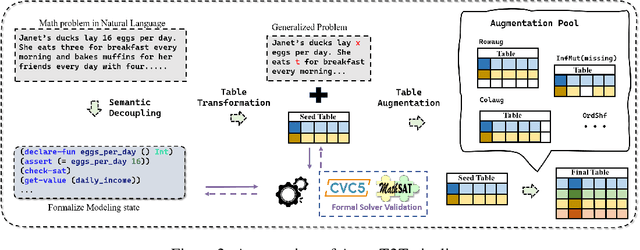

Reasoning with tabular data holds increasing importance in modern applications, yet comprehensive evaluation methodologies for reasoning-intensive Table Question Answering (QA) tasks remain nascent. Existing research is constrained by two primary bottlenecks: 1) Reliance on costly manually annotated real-world data, which is difficult to cover complex reasoning scenarios; 2) The heterogeneity of table structures hinders systematic analysis of the intrinsic mechanisms behind the underperformance of LLMs, especially in reasoning-intensive tasks. To address these issues, we propose an automated generation pipeline AutoT2T that transforms mathematical word problems into table-based reasoning tasks, eliminating the need for manual annotation. The pipeline can generate multiple variants of a table for the same reasoning problem, including noisy versions to support robustness evaluation. Based on this, we construct a new benchmark TabularGSM, which systematically spans a range of table complexities and trap problems. Experimental analyses through AutoT2T and TabularGSM reveal that the tight coupling between reasoning and retrieval or identification processes is a key factor underlying the failure of LLMs in complex Table QA tasks. This highlights the necessity for models to develop synergistic reasoning capabilities in order to perform effectively in complex Table QA tasks.
Realistic Evaluation of TabPFN v2 in Open Environments
May 22, 2025Tabular data, owing to its ubiquitous presence in real-world domains, has garnered significant attention in machine learning research. While tree-based models have long dominated tabular machine learning tasks, the recently proposed deep learning model TabPFN v2 has emerged, demonstrating unparalleled performance and scalability potential. Although extensive research has been conducted on TabPFN v2 to further improve performance, the majority of this research remains confined to closed environments, neglecting the challenges that frequently arise in open environments. This raises the question: Can TabPFN v2 maintain good performance in open environments? To this end, we conduct the first comprehensive evaluation of TabPFN v2's adaptability in open environments. We construct a unified evaluation framework covering various real-world challenges and assess the robustness of TabPFN v2 under open environments scenarios using this framework. Empirical results demonstrate that TabPFN v2 shows significant limitations in open environments but is suitable for small-scale, covariate-shifted, and class-balanced tasks. Tree-based models remain the optimal choice for general tabular tasks in open environments. To facilitate future research on open environments challenges, we advocate for open environments tabular benchmarks, multi-metric evaluation, and universal modules to strengthen model robustness. We publicly release our evaluation framework at https://anonymous.4open.science/r/tabpfn-ood-4E65.
TabFSBench: Tabular Benchmark for Feature Shifts in Open Environment
Jan 31, 2025Tabular data is widely utilized in various machine learning tasks. Current tabular learning research predominantly focuses on closed environments, while in real-world applications, open environments are often encountered, where distribution and feature shifts occur, leading to significant degradation in model performance. Previous research has primarily concentrated on mitigating distribution shifts, whereas feature shifts, a distinctive and unexplored challenge of tabular data, have garnered limited attention. To this end, this paper conducts the first comprehensive study on feature shifts in tabular data and introduces the first tabular feature-shift benchmark (TabFSBench). TabFSBench evaluates impacts of four distinct feature-shift scenarios on four tabular model categories across various datasets and assesses the performance of large language models (LLMs) and tabular LLMs in the tabular benchmark for the first time. Our study demonstrates three main observations: (1) most tabular models have the limited applicability in feature-shift scenarios; (2) the shifted feature set importance has a linear relationship with model performance degradation; (3) model performance in closed environments correlates with feature-shift performance. Future research direction is also explored for each observation. TabFSBench is released for public access by using a few lines of Python codes at https://github.com/LAMDASZ-ML/TabFSBench.