 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking with Tables: Enhancing Multi-Modal Tabular Understanding via Neuro-Symbolic Reasoning
Mar 25, 2026Multimodal Large Language Models (MLLMs) have demonstrated remarkable reasoning capabilities across modalities such as images and text. However, tabular data, despite being a critical real-world modality, remains relatively underexplored in multimodal learning. In this paper, we focus on the task of Tabular-Vision Multi-Modal Understanding (TVMU) and identify three core challenges: (1) high structural variability and data incompleteness in tables, (2) implicit and complex feature dependencies, and (3) significant heterogeneity in problem-solving pipelines across downstream tasks. To address these issues, we propose Thinking with Tables (TWT). TWT employs a program-aided code-based neuro-symbolic reasoning mechanism that facilitates key operations, such as information extraction and element modeling, by interacting with external environments. We evaluate TWT on eight representative datasets. Experimental results demonstrate that TWT consistently outperforms existing baselines by an average of 10\% in accuracy, achieving performance comparable to, or even surpassing, proprietary commercial SOTA LLMs on TVMU tasks. Models and codes are available at https://github.com/kunyang-YU/Thinking-with-Tables
NeSy-Route: A Neuro-Symbolic Benchmark for Constrained Route Planning in Remote Sensing
Mar 17, 2026Remote sensing underpins crucial applications such as disaster relief and ecological field surveys, where systems must understand complex scenes and constraints and make reliable decisions. Current remote-sensing benchmarks mainly focus on evaluating perception and reasoning capabilities of multimodal large language models (MLLMs). They fail to assess planning capability, stemming either from the difficulty of curating and validating planning tasks at scale or from evaluation protocols that are inaccurate and inadequate. To address these limitations, we introduce NeSy-Route, a large-scale neuro-symbolic benchmark for constrained route planning in remote sensing. Within this benchmark, we introduce an automated data-generation framework that integrates high-fidelity semantic masks with heuristic search to produce diverse route-planning tasks with provably optimal solutions. This allows NeSy-Route to comprehensively evaluate planning across 10,821 route-planning samples, nearly 10 times larger than the largest prior benchmark. Furthermore, a three-level hierarchical neuro-symbolic evaluation protocol is developed to enable accurate assessment and support fine-grained analysis on perception, reasoning, and planning simultaneously. Our comprehensive evaluation of various state-of-the-art MLLMs demonstrates that existing MLLMs show significant deficiencies in perception and planning capabilities. We hope NeSy-Route can support further research and development of more powerful MLLMs for remote sensing.
Beyond Single: A Data Selection Principle for LLM Alignment via Fine-Grained Preference Signals
Aug 11, 2025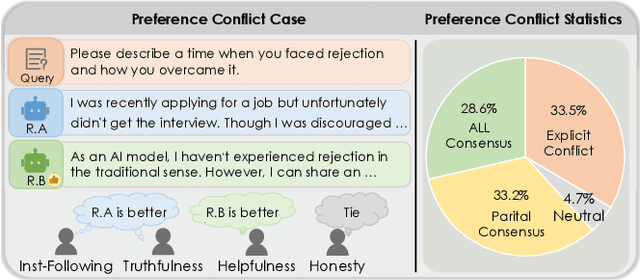
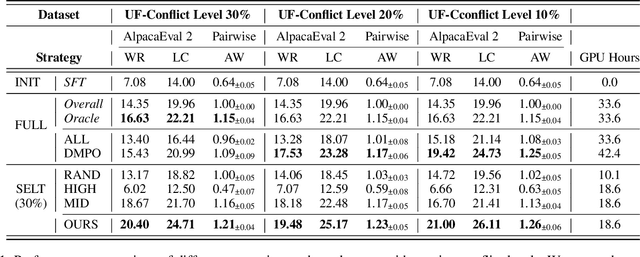
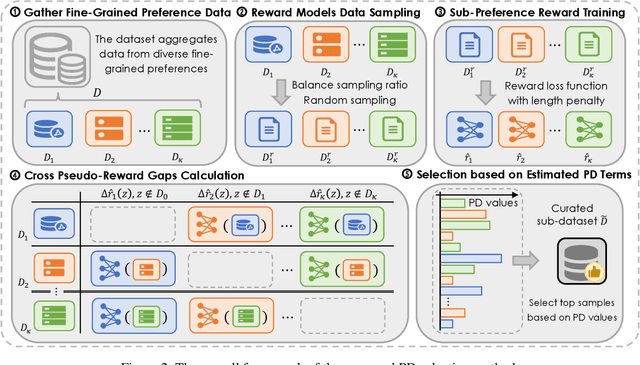
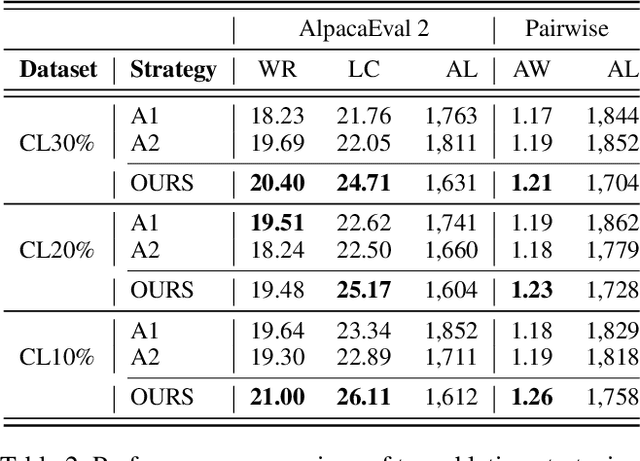
Aligning Large Language Models (LLMs) with diverse human values requires moving beyond a single holistic "better-than" preference criterion. While collecting fine-grained, aspect-specific preference data is more reliable and scalable, existing methods like Direct Preference Optimization (DPO) struggle with the severe noise and conflicts inherent in such aggregated datasets. In this paper, we tackle this challenge from a data-centric perspective. We first derive the Direct Multi-Preference Optimization (DMPO) objective, and uncover a key Preference Divergence (PD) term that quantifies inter-aspect preference conflicts. Instead of using this term for direct optimization, we leverage it to formulate a novel, theoretically-grounded data selection principle. Our principle advocates for selecting a subset of high-consensus data-identified by the most negative PD values-for efficient DPO training. We prove the optimality of this strategy by analyzing the loss bounds of the DMPO objective in the selection problem. To operationalize our approach, we introduce practical methods of PD term estimation and length bias mitigation, thereby proposing our PD selection method. Evaluation on the UltraFeedback dataset with three varying conflict levels shows that our simple yet effective strategy achieves over 10% relative improvement against both the standard holistic preference and a stronger oracle using aggregated preference signals, all while boosting training efficiency and obviating the need for intractable holistic preference annotating, unlocking the potential of robust LLM alignment via fine-grained preference signals.
When Is Prior Knowledge Helpful? Exploring the Evaluation and Selection of Unsupervised Pretext Tasks from a Neuro-Symbolic Perspective
Aug 10, 2025Neuro-symbolic (Nesy) learning improves the target task performance of models by enabling them to satisfy knowledge, while semi/self-supervised learning (SSL) improves the target task performance by designing unsupervised pretext tasks for unlabeled data to make models satisfy corresponding assumptions. We extend the Nesy theory based on reliable knowledge to the scenario of unreliable knowledge (i.e., assumptions), thereby unifying the theoretical frameworks of SSL and Nesy. Through rigorous theoretical analysis, we demonstrate that, in theory, the impact of pretext tasks on target performance hinges on three factors: knowledge learnability with respect to the model, knowledge reliability with respect to the data, and knowledge completeness with respect to the target. We further propose schemes to operationalize these theoretical metrics, and thereby develop a method that can predict the effectiveness of pretext tasks in advance. This will change the current status quo in practical applications, where the selections of unsupervised tasks are heuristic-based rather than theory-based, and it is difficult to evaluate the rationality of unsupervised pretext task selection before testing the model on the target task. In experiments, we verify a high correlation between the predicted performance-estimated using minimal data-and the actual performance achieved after large-scale semi-supervised or self-supervised learning, thus confirming the validity of the theory and the effectiveness of the evaluation method.
Automated Text-to-Table for Reasoning-Intensive Table QA: Pipeline Design and Benchmarking Insights
May 26, 2025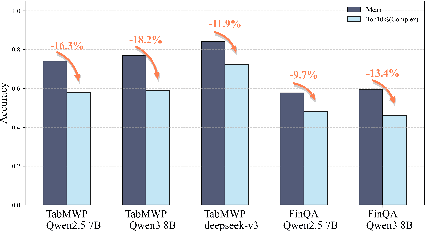
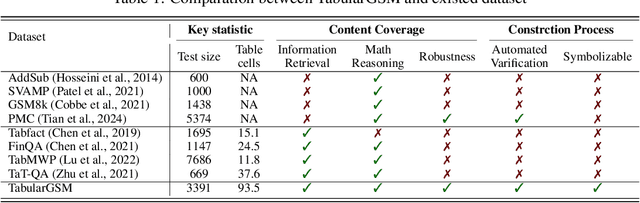
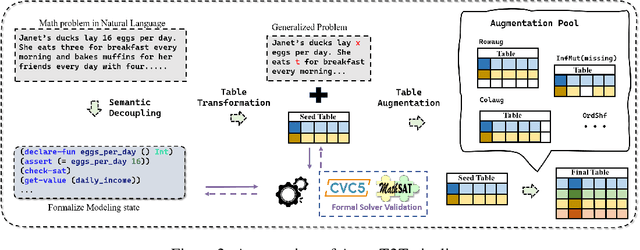

Reasoning with tabular data holds increasing importance in modern applications, yet comprehensive evaluation methodologies for reasoning-intensive Table Question Answering (QA) tasks remain nascent. Existing research is constrained by two primary bottlenecks: 1) Reliance on costly manually annotated real-world data, which is difficult to cover complex reasoning scenarios; 2) The heterogeneity of table structures hinders systematic analysis of the intrinsic mechanisms behind the underperformance of LLMs, especially in reasoning-intensive tasks. To address these issues, we propose an automated generation pipeline AutoT2T that transforms mathematical word problems into table-based reasoning tasks, eliminating the need for manual annotation. The pipeline can generate multiple variants of a table for the same reasoning problem, including noisy versions to support robustness evaluation. Based on this, we construct a new benchmark TabularGSM, which systematically spans a range of table complexities and trap problems. Experimental analyses through AutoT2T and TabularGSM reveal that the tight coupling between reasoning and retrieval or identification processes is a key factor underlying the failure of LLMs in complex Table QA tasks. This highlights the necessity for models to develop synergistic reasoning capabilities in order to perform effectively in complex Table QA tasks.
Realistic Evaluation of TabPFN v2 in Open Environments
May 22, 2025Tabular data, owing to its ubiquitous presence in real-world domains, has garnered significant attention in machine learning research. While tree-based models have long dominated tabular machine learning tasks, the recently proposed deep learning model TabPFN v2 has emerged, demonstrating unparalleled performance and scalability potential. Although extensive research has been conducted on TabPFN v2 to further improve performance, the majority of this research remains confined to closed environments, neglecting the challenges that frequently arise in open environments. This raises the question: Can TabPFN v2 maintain good performance in open environments? To this end, we conduct the first comprehensive evaluation of TabPFN v2's adaptability in open environments. We construct a unified evaluation framework covering various real-world challenges and assess the robustness of TabPFN v2 under open environments scenarios using this framework. Empirical results demonstrate that TabPFN v2 shows significant limitations in open environments but is suitable for small-scale, covariate-shifted, and class-balanced tasks. Tree-based models remain the optimal choice for general tabular tasks in open environments. To facilitate future research on open environments challenges, we advocate for open environments tabular benchmarks, multi-metric evaluation, and universal modules to strengthen model robustness. We publicly release our evaluation framework at https://anonymous.4open.science/r/tabpfn-ood-4E65.
NeSyGeo: A Neuro-Symbolic Framework for Multimodal Geometric Reasoning Data Generation
May 21, 2025



Obtaining large-scale, high-quality data with reasoning paths is crucial for improving the geometric reasoning capabilities of multi-modal large language models (MLLMs). However, existing data generation methods, whether based on predefined templates or constrained symbolic provers, inevitably face diversity and numerical generalization limitations. To address these limitations, we propose NeSyGeo, a novel neuro-symbolic framework for generating geometric reasoning data. First, we propose a domain-specific language grounded in the entity-relation-constraint paradigm to comprehensively represent all components of plane geometry, along with generative actions defined within this symbolic space. We then design a symbolic-visual-text pipeline that synthesizes symbolic sequences, maps them to corresponding visual and textual representations, and generates diverse question-answer (Q&A) pairs using large language models (LLMs). To the best of our knowledge, we are the first to propose a neuro-symbolic approach in generating multimodal reasoning data. Based on this framework, we construct NeSyGeo-CoT and NeSyGeo-Caption datasets, containing 100k samples, and release a new benchmark NeSyGeo-Test for evaluating geometric reasoning abilities in MLLMs. Experiments demonstrate that the proposal significantly and consistently improves the performance of multiple MLLMs under both reinforcement and supervised fine-tuning. With only 4k samples and two epochs of reinforcement fine-tuning, base models achieve improvements of up to +15.8% on MathVision, +8.4% on MathVerse, and +7.3% on GeoQA. Notably, a 4B model can be improved to outperform an 8B model from the same series on geometric reasoning tasks.
Unlabeled Data or Pre-trained Model: Rethinking Semi-Supervised Learning and Pretrain-Finetuning
May 19, 2025Semi-supervised learning (SSL) alleviates the cost of data labeling process by exploiting unlabeled data, and has achieved promising results on various tasks such as image classification. Meanwhile, the Pretrain-Finetuning paradigm has garnered significant attention in recent years, and exploiting pre-trained models could also reduce the requirement of labeled data in downstream tasks. Therefore, a question naturally occurs: \emph{When the labeled data is scarce in the target tasks, should we exploit unlabeled data or pre-trained models?} To answer this question, we select pre-trained Vision-Language Models (VLMs) as representative pretrain-finetuning instances and propose \textit{Few-shot SSL} -- a framework that enables fair comparison between these two paradigms by controlling the amount of labeled data used. Extensive experiments across various settings demonstrate that pre-trained VLMs generally outperform SSL methods in nearly all cases, except when the data has low resolution or lacks clear semantic structure. Therefore, we encourage future SSL research to compare with pre-trained models and explore deeper integration, such as using pre-trained knowledge to enhance pseudo-labeling. To support future research, we release our unified reproduction and evaluation framework. Codes are available at https://anonymous.4open.science/r/Rethinking-SSL-and-Pretrain-Finetuning-5566
Curriculum Abductive Learning
May 18, 2025Abductive Learning (ABL) integrates machine learning with logical reasoning in a loop: a learning model predicts symbolic concept labels from raw inputs, which are revised through abduction using domain knowledge and then fed back for retraining. However, due to the nondeterminism of abduction, the training process often suffers from instability, especially when the knowledge base is large and complex, resulting in a prohibitively large abduction space. While prior works focus on improving candidate selection within this space, they typically treat the knowledge base as a static black box. In this work, we propose Curriculum Abductive Learning (C-ABL), a method that explicitly leverages the internal structure of the knowledge base to address the ABL training challenges. C-ABL partitions the knowledge base into a sequence of sub-bases, progressively introduced during training. This reduces the abduction space throughout training and enables the model to incorporate logic in a stepwise, smooth way. Experiments across multiple tasks show that C-ABL outperforms previous ABL implementations, significantly improves training stability, convergence speed, and final accuracy, especially under complex knowledge setting.
LIFT+: Lightweight Fine-Tuning for Long-Tail Learning
Apr 17, 2025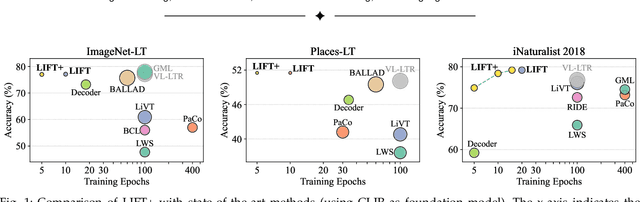
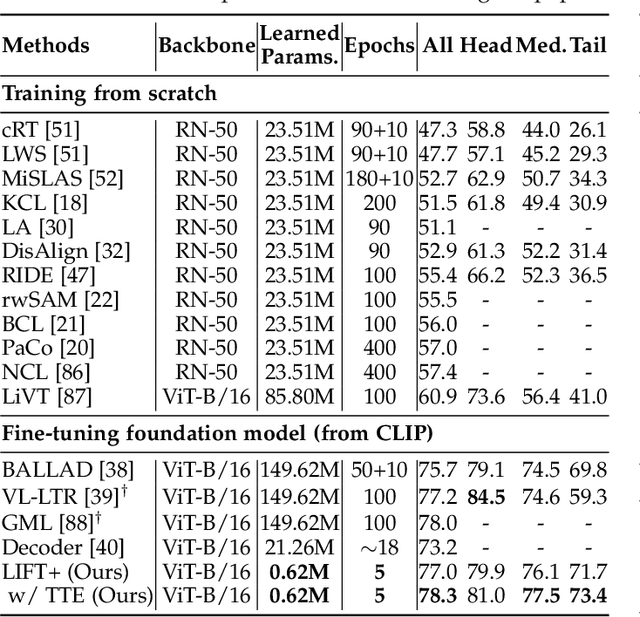
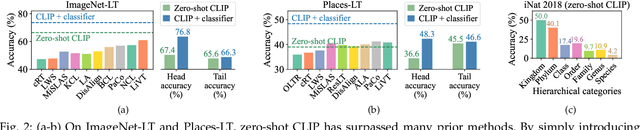
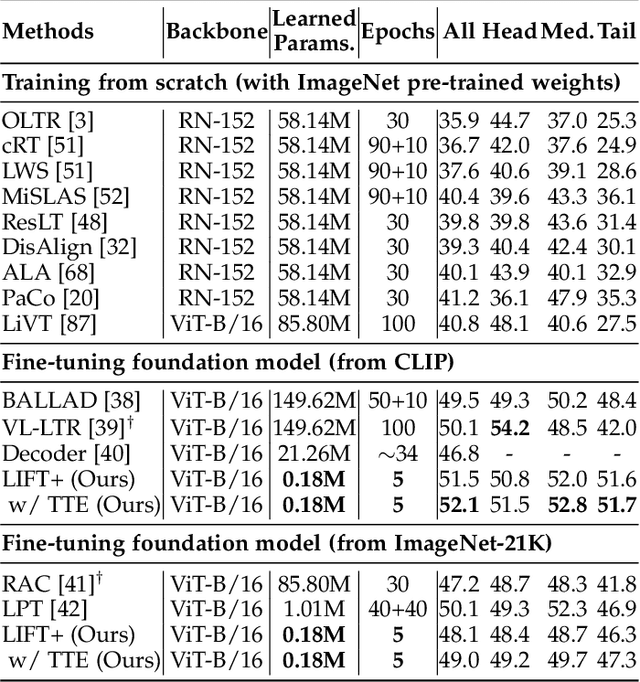
The fine-tuning paradigm has emerged as a prominent approach for addressing long-tail learning tasks in the era of foundation models. However, the impact of fine-tuning strategies on long-tail learning performance remains unexplored. In this work, we disclose that existing paradigms exhibit a profound misuse of fine-tuning methods, leaving significant room for improvement in both efficiency and accuracy. Specifically, we reveal that heavy fine-tuning (fine-tuning a large proportion of model parameters) can lead to non-negligible performance deterioration on tail classes, whereas lightweight fine-tuning demonstrates superior effectiveness. Through comprehensive theoretical and empirical validation, we identify this phenomenon as stemming from inconsistent class conditional distributions induced by heavy fine-tuning. Building on this insight, we propose LIFT+, an innovative lightweight fine-tuning framework to optimize consistent class conditions. Furthermore, LIFT+ incorporates semantic-aware initialization, minimalist data augmentation, and test-time ensembling to enhance adaptation and generalization of foundation models. Our framework provides an efficient and accurate pipeline that facilitates fast convergence and model compactness. Extensive experiments demonstrate that LIFT+ significantly reduces both training epochs (from $\sim$100 to $\leq$15) and learned parameters (less than 1%), while surpassing state-of-the-art approaches by a considerable margin. The source code is available at https://github.com/shijxcs/LIFT-plus.