 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity Algorithm for Stackelberg Prediction Games with Global Optimality
Apr 03, 2026Stackelberg prediction games (SPGs) model strategic data manipulation in adversarial learning via a leader--follower interaction between a learner and a self-interested data provider, leading to challenging bilevel optimization problems. Focusing on the least-squares setting (SPG-LS), recent work shows that the bilevel program admits an equivalent spherically constrained least-squares (SCLS) reformulation, which avoids costly conic programming and enables scalable algorithms. In this paper, we develop a simple and efficient alternating direction method of multiplier (ADMM) based solver for the SCLS problem. By introducing a consensus splitting that separates the quadratic objective from the spherical constraint, we obtain an augmented Lagrangian formulation with closed-form updates: the primal quadratic step reduces to solving a fixed shifted linear system, the constraint step is a projection onto the unit sphere, and the dual step is a lightweight scaled ascent. The resulting method has low per-iteration complexity and allows pre-factorization of the constant system matrix for substantial speedups. Experiments demonstrate that the proposed ADMM approach achieves competitive solution quality with significantly improved computational efficiency compared with existing global solvers for SCLS, particularly in sparse and high-dimensional regimes.
Global-Aware Edge Prioritization for Pose Graph Initialization
Feb 25, 2026The pose graph is a core component of Structure-from-Motion (SfM), where images act as nodes and edges encode relative poses. Since geometric verification is expensive, SfM pipelines restrict the pose graph to a sparse set of candidate edges, making initialization critical. Existing methods rely on image retrieval to connect each image to its $k$ nearest neighbors, treating pairs independently and ignoring global consistency. We address this limitation through the concept of edge prioritization, ranking candidate edges by their utility for SfM. Our approach has three components: (1) a GNN trained with SfM-derived supervision to predict globally consistent edge reliability; (2) multi-minimal-spanning-tree-based pose graph construction guided by these ranks; and (3) connectivity-aware score modulation that reinforces weak regions and reduces graph diameter. This globally informed initialization yields more reliable and compact pose graphs, improving reconstruction accuracy in sparse and high-speed settings and outperforming SOTA retrieval methods on ambiguous scenes. The ode and trained models are available at https://github.com/weitong8591/global_edge_prior.
Spectral Imbalance Causes Forgetting in Low-Rank Continual Adaptation
Jan 31, 2026Parameter-efficient continual learning aims to adapt pre-trained models to sequential tasks without forgetting previously acquired knowledge. Most existing approaches treat continual learning as avoiding interference with past updates, rather than considering what properties make the current task-specific update naturally preserve previously acquired knowledge. From a knowledge-decomposition perspective, we observe that low-rank adaptations exhibit highly imbalanced singular value spectra: a few dominant components absorb most of the adaptation energy, thereby (i) more likely to disrupt previously acquired knowledge and (ii) making the update more vulnerable to interference from subsequent tasks. To enable explicit balance among components, we decouple the magnitude of the task update from its directional structure and formulate it as a constrained optimization problem on a restricted Stiefel manifold. We address this problem using a projected first-order method compatible with standard deep-learning optimizers used in vision-language models. Our method mitigates both backward and forward forgetting, consistently outperforming continual learning baselines. The implementation code is available at https://github.com/haodotgu/EBLoRA.
KeepLoRA: Continual Learning with Residual Gradient Adaptation
Jan 27, 2026Continual learning for pre-trained vision-language models requires balancing three competing objectives: retaining pre-trained knowledge, preserving knowledge from a sequence of learned tasks, and maintaining the plasticity to acquire new knowledge. This paper presents a simple but effective approach called KeepLoRA to effectively balance these objectives. We first analyze the knowledge retention mechanism within the model parameter space and find that general knowledge is mainly encoded in the principal subspace, while task-specific knowledge is encoded in the residual subspace. Motivated by this finding, KeepLoRA learns new tasks by restricting LoRA parameter updates in the residual subspace to prevent interfering with previously learned capabilities. Specifically, we infuse knowledge for a new task by projecting its gradient onto a subspace orthogonal to both the principal subspace of pre-trained model and the dominant directions of previous task features. Our theoretical and empirical analyses confirm that KeepLoRA balances the three objectives and achieves state-of-the-art performance. The implementation code is available at https://github.com/MaolinLuo/KeepLoRA.
Fundamental Limits for Near-Field Sensing -- Part II: Wide-Band Systems
Dec 31, 2025Near-field sensing with extremely large-scale antenna arrays (ELAAs) in practical 6G systems is expected to operate over broad bandwidths, where delay, Doppler, and spatial effects become tightly coupled across frequency. The purpose of this and the companion paper (Part I) is to develop the unified Cram'er--Rao bounds (CRBs) for sensing systems spanning from far-field to near-field, and narrow-band to wide-band. This paper (Part II) derives fundamental estimation limits for a wide-band near-field sensing systems employing orthogonal frequency-division multiplexing signaling over a coherent processing interval. We establish an exact near-field wide-band signal model that captures frequency-dependent propagation, spherical-wave geometry, and the intrinsic coupling between target location and motion parameters across subcarriers and slow time. Similar as Part I using the Slepian--Bangs formulation, we derive the wide-band Fisher information matrix and the CRBs for joint estimation of target position, velocity, and radar cross-section, and we show how wide-band information aggregates across orthogonal subcarriers. We further develop tractable far-field and near-field approximations which provide design-level insights into the roles of bandwidth, coherent integration length, and array aperture, and clarify when wide-band effects. Simulation results validate the derived CRBs and its approximations, demonstrating close agreement with the analytical scaling laws across representative ranges, bandwidths, and array configurations.
GTR-Turbo: Merged Checkpoint is Secretly a Free Teacher for Agentic VLM Training
Dec 15, 2025Multi-turn reinforcement learning (RL) for multi-modal agents built upon vision-language models (VLMs) is hampered by sparse rewards and long-horizon credit assignment. Recent methods densify the reward by querying a teacher that provides step-level feedback, e.g., Guided Thought Reinforcement (GTR) and On-Policy Distillation, but rely on costly, often privileged models as the teacher, limiting practicality and reproducibility. We introduce GTR-Turbo, a highly efficient upgrade to GTR, which matches the performance without training or querying an expensive teacher model. Specifically, GTR-Turbo merges the weights of checkpoints produced during the ongoing RL training, and then uses this merged model as a "free" teacher to guide the subsequent RL via supervised fine-tuning or soft logit distillation. This design removes dependence on privileged VLMs (e.g., GPT or Gemini), mitigates the "entropy collapse" observed in prior work, and keeps training stable. Across diverse visual agentic tasks, GTR-Turbo improves the accuracy of the baseline model by 10-30% while reducing wall-clock training time by 50% and compute cost by 60% relative to GTR.
TSPE-GS: Probabilistic Depth Extraction for Semi-Transparent Surface Reconstruction via 3D Gaussian Splatting
Nov 13, 20253D Gaussian Splatting offers a strong speed-quality trade-off but struggles to reconstruct semi-transparent surfaces because most methods assume a single depth per pixel, which fails when multiple surfaces are visible. We propose TSPE-GS (Transparent Surface Probabilistic Extraction for Gaussian Splatting), which uniformly samples transmittance to model a pixel-wise multi-modal distribution of opacity and depth, replacing the prior single-peak assumption and resolving cross-surface depth ambiguity. By progressively fusing truncated signed distance functions, TSPE-GS reconstructs external and internal surfaces separately within a unified framework. The method generalizes to other Gaussian-based reconstruction pipelines without extra training overhead. Extensive experiments on public and self-collected semi-transparent and opaque datasets show TSPE-GS significantly improves semi-transparent geometry reconstruction while maintaining performance on opaque scenes.
Tuning the Right Foundation Models is What you Need for Partial Label Learning
Jun 05, 2025Partial label learning (PLL) seeks to train generalizable classifiers from datasets with inexact supervision, a common challenge in real-world applications. Existing studies have developed numerous approaches to progressively refine and recover ground-truth labels by training convolutional neural networks. However, limited attention has been given to foundation models that offer transferrable representations. In this work, we empirically conduct comprehensive evaluations of 11 foundation models across 13 PLL approaches on 8 benchmark datasets under 3 PLL scenarios. We further propose PartialCLIP, an efficient fine-tuning framework for foundation models in PLL. Our findings reveal that current PLL approaches tend to 1) achieve significant performance gains when using foundation models, 2) exhibit remarkably similar performance to each other, 3) maintain stable performance across varying ambiguity levels, while 4) are susceptible to foundation model selection and adaptation strategies. Additionally, we demonstrate the efficacy of text-embedding classifier initialization and effective candidate label filtering using zero-shot CLIP. Our experimental results and analysis underscore the limitations of current PLL approaches and provide valuable insights for developing more generalizable PLL models. The source code can be found at https://github.com/SEU-hk/PartialCLIP.
LADA: Scalable Label-Specific CLIP Adapter for Continual Learning
May 29, 2025



Continual learning with vision-language models like CLIP offers a pathway toward scalable machine learning systems by leveraging its transferable representations. Existing CLIP-based methods adapt the pre-trained image encoder by adding multiple sets of learnable parameters, with each task using a partial set of parameters. This requires selecting the expected parameters for input images during inference, which is prone to error that degrades performance. To address this problem, we introduce LADA (Label-specific ADApter). Instead of partitioning parameters across tasks, LADA appends lightweight, label-specific memory units to the frozen CLIP image encoder, enabling discriminative feature generation by aggregating task-agnostic knowledge. To prevent catastrophic forgetting, LADA employs feature distillation for seen classes, preventing their features from being interfered with by new classes. Positioned after the image encoder, LADA prevents gradient flow to the frozen CLIP parameters, ensuring efficient training. Extensive results show that LADA achieves state-of-the-art performance in continual learning settings. The implementation code is available at https://github.com/MaolinLuo/LADA.
LIFT+: Lightweight Fine-Tuning for Long-Tail Learning
Apr 17, 2025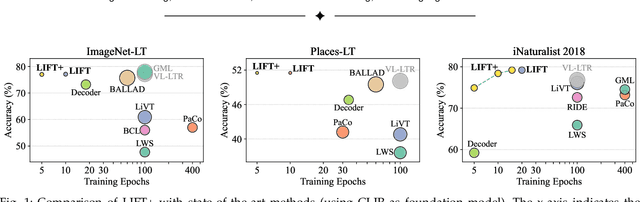
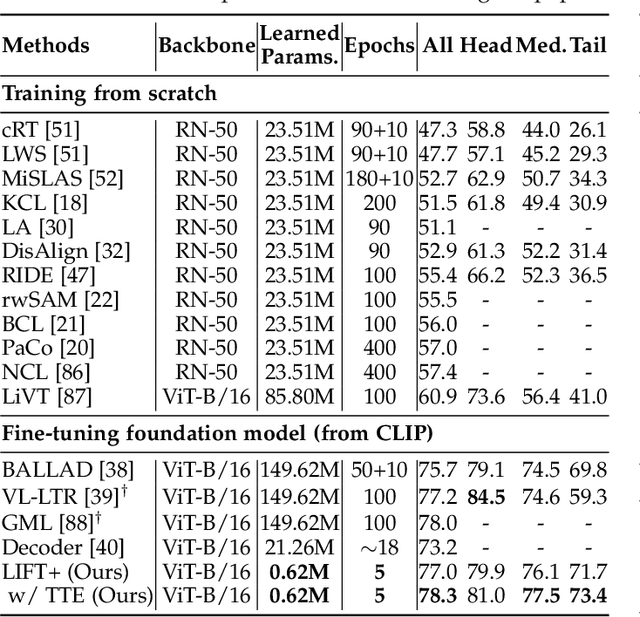
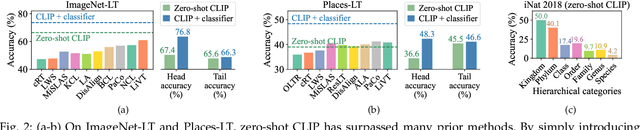
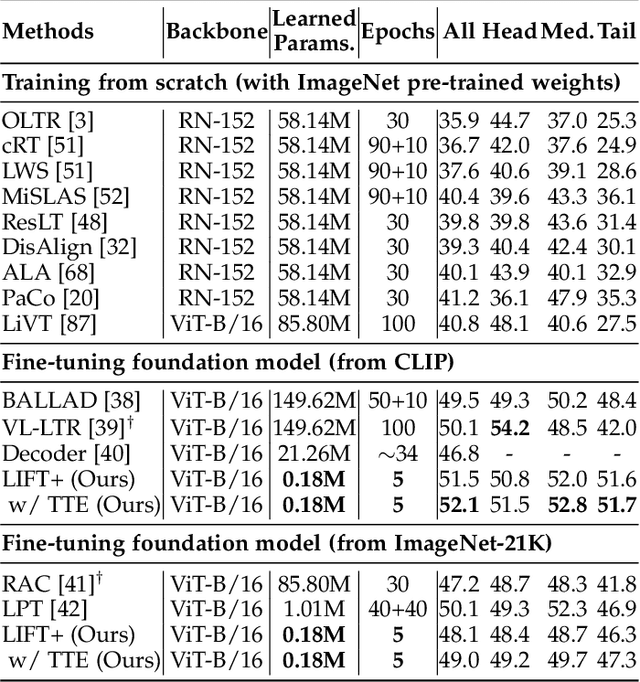
The fine-tuning paradigm has emerged as a prominent approach for addressing long-tail learning tasks in the era of foundation models. However, the impact of fine-tuning strategies on long-tail learning performance remains unexplored. In this work, we disclose that existing paradigms exhibit a profound misuse of fine-tuning methods, leaving significant room for improvement in both efficiency and accuracy. Specifically, we reveal that heavy fine-tuning (fine-tuning a large proportion of model parameters) can lead to non-negligible performance deterioration on tail classes, whereas lightweight fine-tuning demonstrates superior effectiveness. Through comprehensive theoretical and empirical validation, we identify this phenomenon as stemming from inconsistent class conditional distributions induced by heavy fine-tuning. Building on this insight, we propose LIFT+, an innovative lightweight fine-tuning framework to optimize consistent class conditions. Furthermore, LIFT+ incorporates semantic-aware initialization, minimalist data augmentation, and test-time ensembling to enhance adaptation and generalization of foundation models. Our framework provides an efficient and accurate pipeline that facilitates fast convergence and model compactness. Extensive experiments demonstrate that LIFT+ significantly reduces both training epochs (from $\sim$100 to $\leq$15) and learned parameters (less than 1%), while surpassing state-of-the-art approaches by a considerable margin. The source code is available at https://github.com/shijxcs/LIFT-plus.