 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaCo: Ranking and Covariance for Practical Learned Keypoints
Feb 17, 2026This paper introduces RaCo, a lightweight neural network designed to learn robust and versatile keypoints suitable for a variety of 3D computer vision tasks. The model integrates three key components: the repeatable keypoint detector, a differentiable ranker to maximize matches with a limited number of keypoints, and a covariance estimator to quantify spatial uncertainty in metric scale. Trained on perspective image crops only, RaCo operates without the need for covisible image pairs. It achieves strong rotational robustness through extensive data augmentation, even without the use of computationally expensive equivariant network architectures. The method is evaluated on several challenging datasets, where it demonstrates state-of-the-art performance in keypoint repeatability and two-view matching, particularly under large in-plane rotations. Ultimately, RaCo provides an effective and simple strategy to independently estimate keypoint ranking and metric covariance without additional labels, detecting interpretable and repeatable interest points. The code is available at https://github.com/cvg/RaCo.
Scaling Image Geo-Localization to Continent Level
Oct 30, 2025Determining the precise geographic location of an image at a global scale remains an unsolved challenge. Standard image retrieval techniques are inefficient due to the sheer volume of images (>100M) and fail when coverage is insufficient. Scalable solutions, however, involve a trade-off: global classification typically yields coarse results (10+ kilometers), while cross-view retrieval between ground and aerial imagery suffers from a domain gap and has been primarily studied on smaller regions. This paper introduces a hybrid approach that achieves fine-grained geo-localization across a large geographic expanse the size of a continent. We leverage a proxy classification task during training to learn rich feature representations that implicitly encode precise location information. We combine these learned prototypes with embeddings of aerial imagery to increase robustness to the sparsity of ground-level data. This enables direct, fine-grained retrieval over areas spanning multiple countries. Our extensive evaluation demonstrates that our approach can localize within 200m more than 68\% of queries of a dataset covering a large part of Europe. The code is publicly available at https://scaling-geoloc.github.io.
GeoCalib: Learning Single-image Calibration with Geometric Optimization
Sep 10, 2024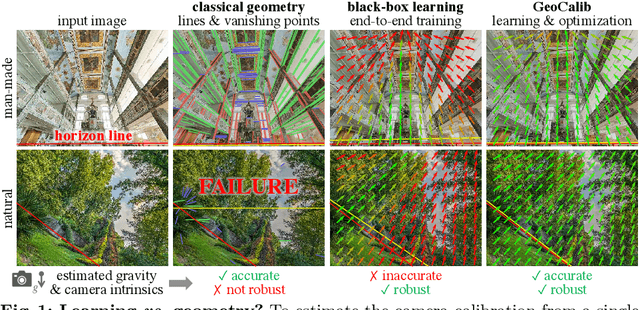
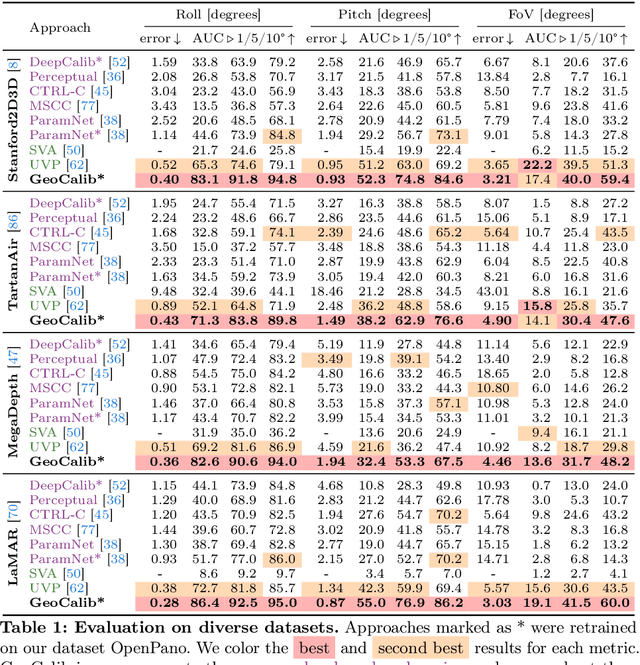

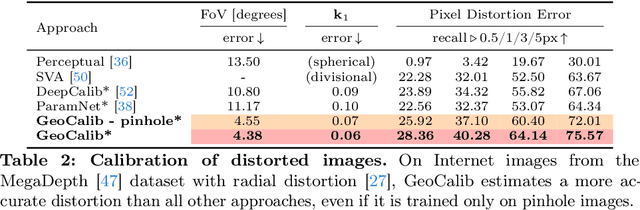
From a single image, visual cues can help deduce intrinsic and extrinsic camera parameters like the focal length and the gravity direction. This single-image calibration can benefit various downstream applications like image editing and 3D mapping. Current approaches to this problem are based on either classical geometry with lines and vanishing points or on deep neural networks trained end-to-end. The learned approaches are more robust but struggle to generalize to new environments and are less accurate than their classical counterparts. We hypothesize that they lack the constraints that 3D geometry provides. In this work, we introduce GeoCalib, a deep neural network that leverages universal rules of 3D geometry through an optimization process. GeoCalib is trained end-to-end to estimate camera parameters and learns to find useful visual cues from the data. Experiments on various benchmarks show that GeoCalib is more robust and more accurate than existing classical and learned approaches. Its internal optimization estimates uncertainties, which help flag failure cases and benefit downstream applications like visual localization. The code and trained models are publicly available at https://github.com/cvg/GeoCalib.
Breaking the Frame: Image Retrieval by Visual Overlap Prediction
Jun 23, 2024



We propose a novel visual place recognition approach, VOP, that efficiently addresses occlusions and complex scenes by shifting from traditional reliance on global image similarities and local features to image overlap prediction. The proposed method enables the identification of visible image sections without requiring expensive feature detection and matching. By focusing on obtaining patch-level embeddings by a Vision Transformer backbone and establishing patch-to-patch correspondences, our approach uses a voting mechanism to assess overlap scores for potential database images, thereby providing a nuanced image retrieval metric in challenging scenarios. VOP leads to more accurate relative pose estimation and localization results on the retrieved image pairs than state-of-the-art baselines on a number of large-scale, real-world datasets. The code is available at https://github.com/weitong8591/vop.
LightGlue: Local Feature Matching at Light Speed
Jun 23, 2023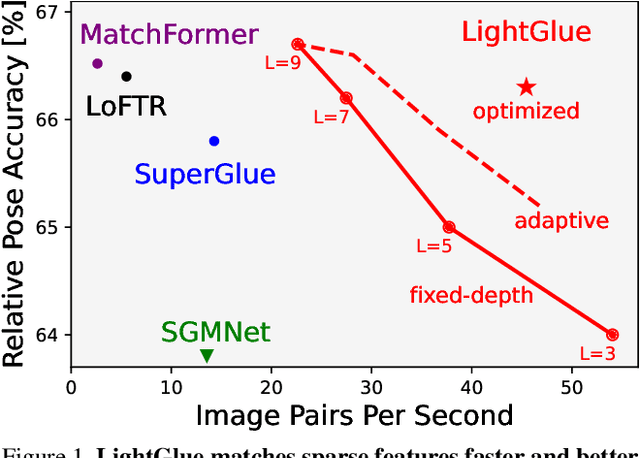
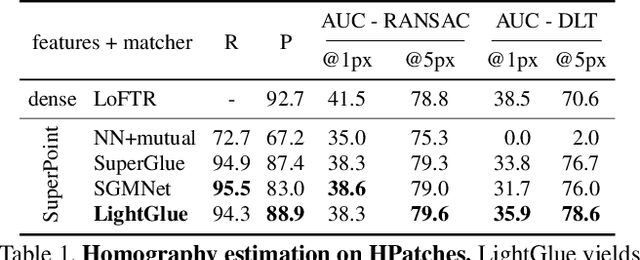


We introduce LightGlue, a deep neural network that learns to match local features across images. We revisit multiple design decisions of SuperGlue, the state of the art in sparse matching, and derive simple but effective improvements. Cumulatively, they make LightGlue more efficient - in terms of both memory and computation, more accurate, and much easier to train. One key property is that LightGlue is adaptive to the difficulty of the problem: the inference is much faster on image pairs that are intuitively easy to match, for example because of a larger visual overlap or limited appearance change. This opens up exciting prospects for deploying deep matchers in latency-sensitive applications like 3D reconstruction. The code and trained models are publicly available at https://github.com/cvg/LightGlue.
Pixel-Perfect Structure-from-Motion with Featuremetric Refinement
Aug 18, 2021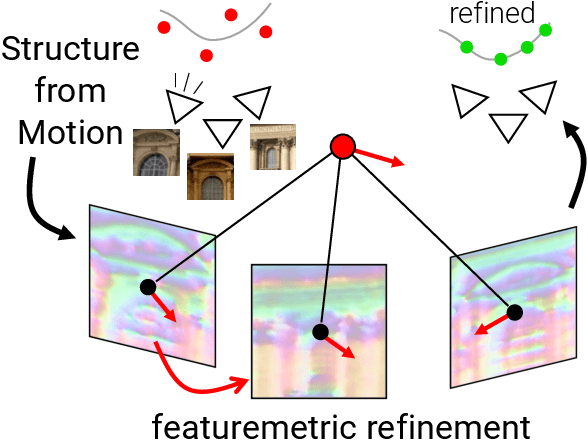
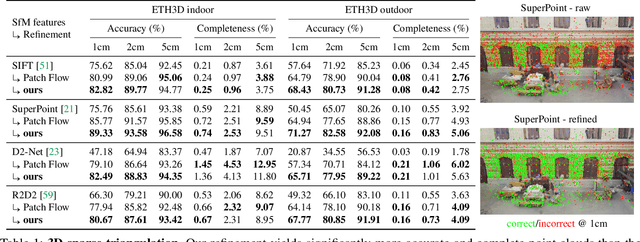

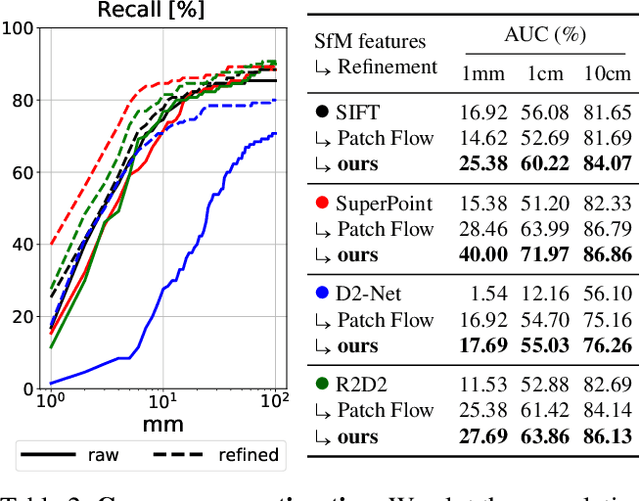
Finding local features that are repeatable across multiple views is a cornerstone of sparse 3D reconstruction. The classical image matching paradigm detects keypoints per-image once and for all, which can yield poorly-localized features and propagate large errors to the final geometry. In this paper, we refine two key steps of structure-from-motion by a direct alignment of low-level image information from multiple views: we first adjust the initial keypoint locations prior to any geometric estimation, and subsequently refine points and camera poses as a post-processing. This refinement is robust to large detection noise and appearance changes, as it optimizes a featuremetric error based on dense features predicted by a neural network. This significantly improves the accuracy of camera poses and scene geometry for a wide range of keypoint detectors, challenging viewing conditions, and off-the-shelf deep features. Our system easily scales to large image collections, enabling pixel-perfect crowd-sourced localization at scale. Our code is publicly available at https://github.com/cvg/pixel-perfect-sfm as an add-on to the popular SfM software COLMAP.
GraphMineSuite: Enabling High-Performance and Programmable Graph Mining Algorithms with Set Algebra
Mar 05, 2021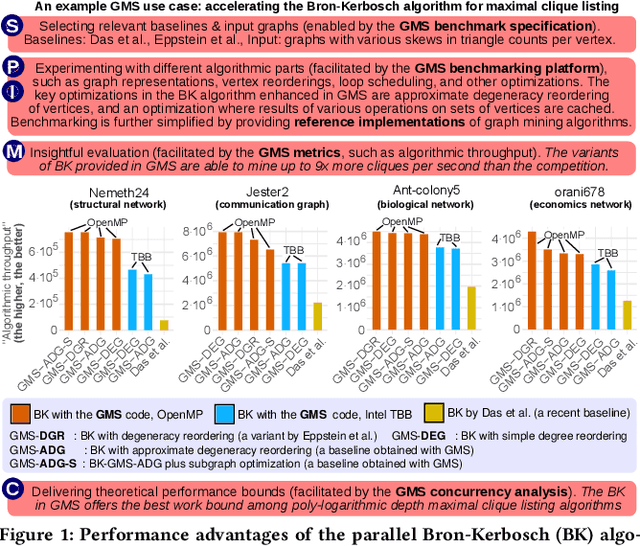

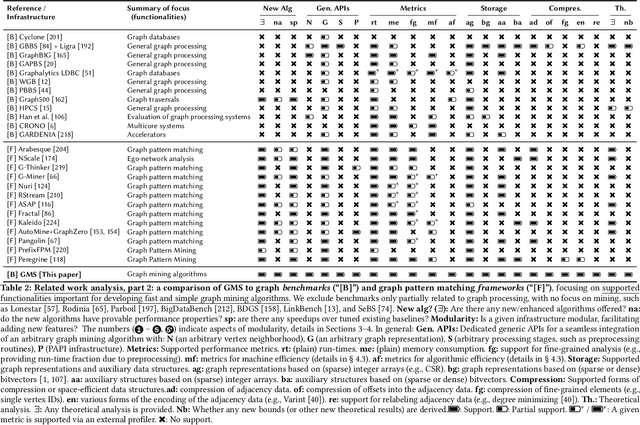
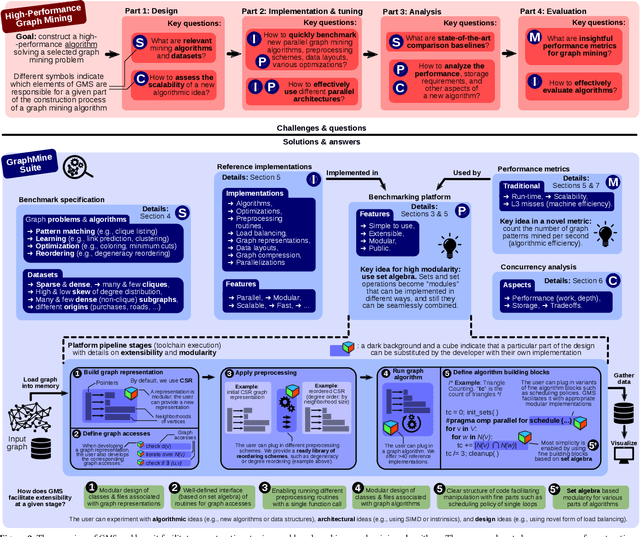
We propose GraphMineSuite (GMS): the first benchmarking suite for graph mining that facilitates evaluating and constructing high-performance graph mining algorithms. First, GMS comes with a benchmark specification based on extensive literature review, prescribing representative problems, algorithms, and datasets. Second, GMS offers a carefully designed software platform for seamless testing of different fine-grained elements of graph mining algorithms, such as graph representations or algorithm subroutines. The platform includes parallel implementations of more than 40 considered baselines, and it facilitates developing complex and fast mining algorithms. High modularity is possible by harnessing set algebra operations such as set intersection and difference, which enables breaking complex graph mining algorithms into simple building blocks that can be separately experimented with. GMS is supported with a broad concurrency analysis for portability in performance insights, and a novel performance metric to assess the throughput of graph mining algorithms, enabling more insightful evaluation. As use cases, we harness GMS to rapidly redesign and accelerate state-of-the-art baselines of core graph mining problems: degeneracy reordering (by up to >2x), maximal clique listing (by up to >9x), k-clique listing (by 1.1x), and subgraph isomorphism (by up to 2.5x), also obtaining better theoretical performance bounds.