 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNIGEOCLIP: Unified Geospatial Contrastive Learning
Apr 13, 2026The growing availability of co-located geospatial data spanning aerial imagery, street-level views, elevation models, text, and geographic coordinates offers a unique opportunity for multimodal representation learning. We introduce UNIGEOCLIP, a massively multimodal contrastive framework to jointly align five complementary geospatial modalities in a single unified embedding space. Unlike prior approaches that fuse modalities or rely on a central pivot representation, our method performs all-to-all contrastive alignment, enabling seamless comparison, retrieval, and reasoning across arbitrary combinations of modalities. We further propose a scaled latitude-longitude encoder that improves spatial representation by capturing multi-scale geographic structure. Extensive experiments across downstream geospatial tasks demonstrate that UNIGEOCLIP consistently outperforms single-modality contrastive models and coordinate-only baselines, highlighting the benefits of holistic multimodal geospatial alignment. A reference implementation is available at https://gastruc.github.io/unigeoclip.
RaCo: Ranking and Covariance for Practical Learned Keypoints
Feb 17, 2026This paper introduces RaCo, a lightweight neural network designed to learn robust and versatile keypoints suitable for a variety of 3D computer vision tasks. The model integrates three key components: the repeatable keypoint detector, a differentiable ranker to maximize matches with a limited number of keypoints, and a covariance estimator to quantify spatial uncertainty in metric scale. Trained on perspective image crops only, RaCo operates without the need for covisible image pairs. It achieves strong rotational robustness through extensive data augmentation, even without the use of computationally expensive equivariant network architectures. The method is evaluated on several challenging datasets, where it demonstrates state-of-the-art performance in keypoint repeatability and two-view matching, particularly under large in-plane rotations. Ultimately, RaCo provides an effective and simple strategy to independently estimate keypoint ranking and metric covariance without additional labels, detecting interpretable and repeatable interest points. The code is available at https://github.com/cvg/RaCo.
Scaling Image Geo-Localization to Continent Level
Oct 30, 2025Determining the precise geographic location of an image at a global scale remains an unsolved challenge. Standard image retrieval techniques are inefficient due to the sheer volume of images (>100M) and fail when coverage is insufficient. Scalable solutions, however, involve a trade-off: global classification typically yields coarse results (10+ kilometers), while cross-view retrieval between ground and aerial imagery suffers from a domain gap and has been primarily studied on smaller regions. This paper introduces a hybrid approach that achieves fine-grained geo-localization across a large geographic expanse the size of a continent. We leverage a proxy classification task during training to learn rich feature representations that implicitly encode precise location information. We combine these learned prototypes with embeddings of aerial imagery to increase robustness to the sparsity of ground-level data. This enables direct, fine-grained retrieval over areas spanning multiple countries. Our extensive evaluation demonstrates that our approach can localize within 200m more than 68\% of queries of a dataset covering a large part of Europe. The code is publicly available at https://scaling-geoloc.github.io.
Benchmarking Egocentric Visual-Inertial SLAM at City Scale
Sep 30, 2025Precise 6-DoF simultaneous localization and mapping (SLAM) from onboard sensors is critical for wearable devices capturing egocentric data, which exhibits specific challenges, such as a wider diversity of motions and viewpoints, prevalent dynamic visual content, or long sessions affected by time-varying sensor calibration. While recent progress on SLAM has been swift, academic research is still driven by benchmarks that do not reflect these challenges or do not offer sufficiently accurate ground truth poses. In this paper, we introduce a new dataset and benchmark for visual-inertial SLAM with egocentric, multi-modal data. We record hours and kilometers of trajectories through a city center with glasses-like devices equipped with various sensors. We leverage surveying tools to obtain control points as indirect pose annotations that are metric, centimeter-accurate, and available at city scale. This makes it possible to evaluate extreme trajectories that involve walking at night or traveling in a vehicle. We show that state-of-the-art systems developed by academia are not robust to these challenges and we identify components that are responsible for this. In addition, we design tracks with different levels of difficulty to ease in-depth analysis and evaluation of less mature approaches. The dataset and benchmark are available at https://www.lamaria.ethz.ch.
MP-SfM: Monocular Surface Priors for Robust Structure-from-Motion
Apr 28, 2025While Structure-from-Motion (SfM) has seen much progress over the years, state-of-the-art systems are prone to failure when facing extreme viewpoint changes in low-overlap, low-parallax or high-symmetry scenarios. Because capturing images that avoid these pitfalls is challenging, this severely limits the wider use of SfM, especially by non-expert users. We overcome these limitations by augmenting the classical SfM paradigm with monocular depth and normal priors inferred by deep neural networks. Thanks to a tight integration of monocular and multi-view constraints, our approach significantly outperforms existing ones under extreme viewpoint changes, while maintaining strong performance in standard conditions. We also show that monocular priors can help reject faulty associations due to symmetries, which is a long-standing problem for SfM. This makes our approach the first capable of reliably reconstructing challenging indoor environments from few images. Through principled uncertainty propagation, it is robust to errors in the priors, can handle priors inferred by different models with little tuning, and will thus easily benefit from future progress in monocular depth and normal estimation. Our code is publicly available at https://github.com/cvg/mpsfm.
GeoCalib: Learning Single-image Calibration with Geometric Optimization
Sep 10, 2024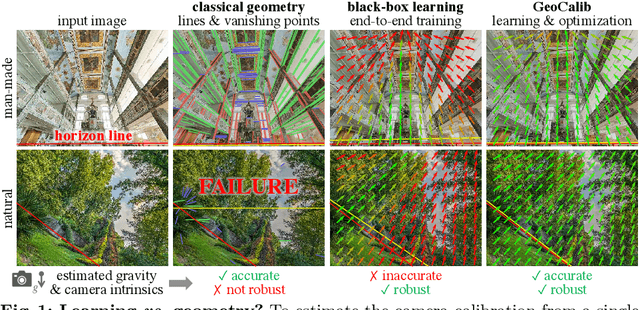
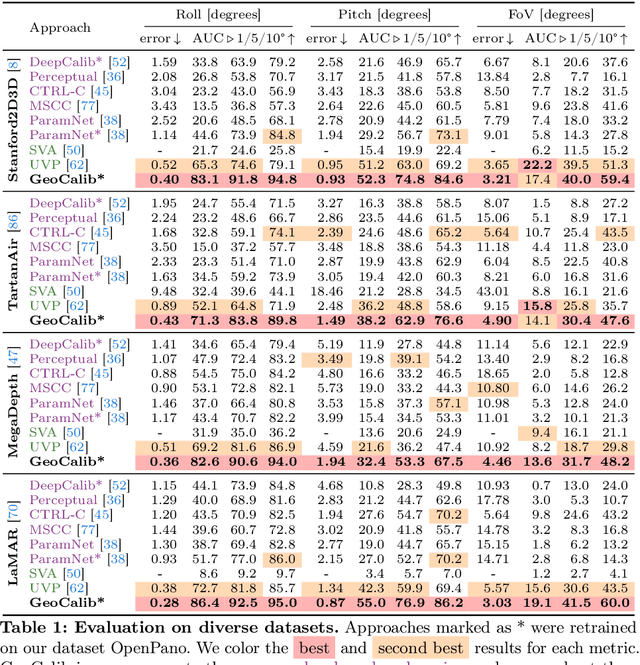

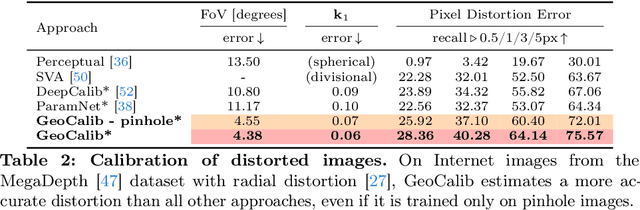
From a single image, visual cues can help deduce intrinsic and extrinsic camera parameters like the focal length and the gravity direction. This single-image calibration can benefit various downstream applications like image editing and 3D mapping. Current approaches to this problem are based on either classical geometry with lines and vanishing points or on deep neural networks trained end-to-end. The learned approaches are more robust but struggle to generalize to new environments and are less accurate than their classical counterparts. We hypothesize that they lack the constraints that 3D geometry provides. In this work, we introduce GeoCalib, a deep neural network that leverages universal rules of 3D geometry through an optimization process. GeoCalib is trained end-to-end to estimate camera parameters and learns to find useful visual cues from the data. Experiments on various benchmarks show that GeoCalib is more robust and more accurate than existing classical and learned approaches. Its internal optimization estimates uncertainties, which help flag failure cases and benefit downstream applications like visual localization. The code and trained models are publicly available at https://github.com/cvg/GeoCalib.
AffineGlue: Joint Matching and Robust Estimation
Jul 28, 2023



We propose AffineGlue, a method for joint two-view feature matching and robust estimation that reduces the combinatorial complexity of the problem by employing single-point minimal solvers. AffineGlue selects potential matches from one-to-many correspondences to estimate minimal models. Guided matching is then used to find matches consistent with the model, suffering less from the ambiguities of one-to-one matches. Moreover, we derive a new minimal solver for homography estimation, requiring only a single affine correspondence (AC) and a gravity prior. Furthermore, we train a neural network to reject ACs that are unlikely to lead to a good model. AffineGlue is superior to the SOTA on real-world datasets, even when assuming that the gravity direction points downwards. On PhotoTourism, the AUC@10{\deg} score is improved by 6.6 points compared to the SOTA. On ScanNet, AffineGlue makes SuperPoint and SuperGlue achieve similar accuracy as the detector-free LoFTR.
LightGlue: Local Feature Matching at Light Speed
Jun 23, 2023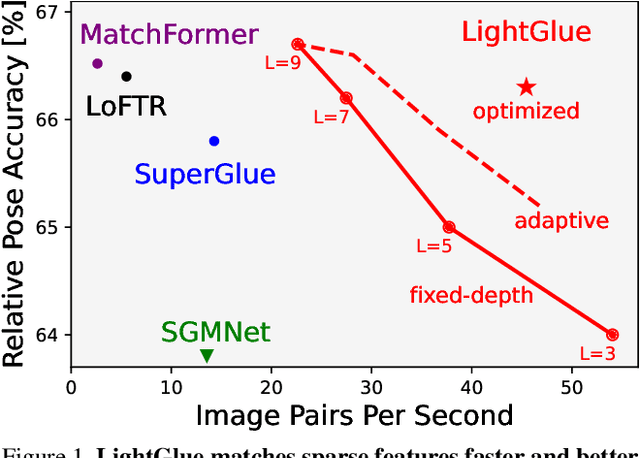
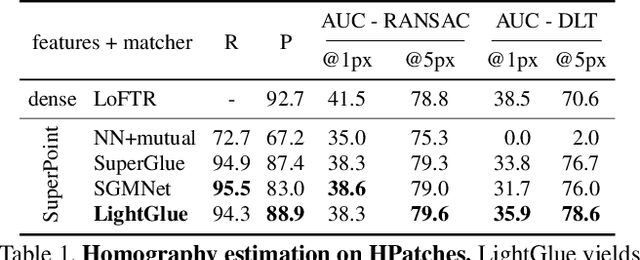


We introduce LightGlue, a deep neural network that learns to match local features across images. We revisit multiple design decisions of SuperGlue, the state of the art in sparse matching, and derive simple but effective improvements. Cumulatively, they make LightGlue more efficient - in terms of both memory and computation, more accurate, and much easier to train. One key property is that LightGlue is adaptive to the difficulty of the problem: the inference is much faster on image pairs that are intuitively easy to match, for example because of a larger visual overlap or limited appearance change. This opens up exciting prospects for deploying deep matchers in latency-sensitive applications like 3D reconstruction. The code and trained models are publicly available at https://github.com/cvg/LightGlue.
SNAP: Self-Supervised Neural Maps for Visual Positioning and Semantic Understanding
Jun 08, 2023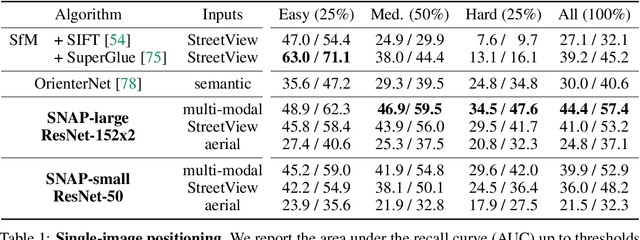
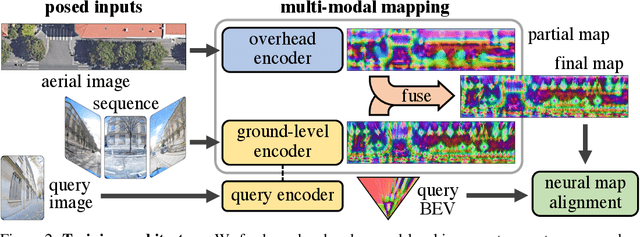


Semantic 2D maps are commonly used by humans and machines for navigation purposes, whether it's walking or driving. However, these maps have limitations: they lack detail, often contain inaccuracies, and are difficult to create and maintain, especially in an automated fashion. Can we use raw imagery to automatically create better maps that can be easily interpreted by both humans and machines? We introduce SNAP, a deep network that learns rich neural 2D maps from ground-level and overhead images. We train our model to align neural maps estimated from different inputs, supervised only with camera poses over tens of millions of StreetView images. SNAP can resolve the location of challenging image queries beyond the reach of traditional methods, outperforming the state of the art in localization by a large margin. Moreover, our neural maps encode not only geometry and appearance but also high-level semantics, discovered without explicit supervision. This enables effective pre-training for data-efficient semantic scene understanding, with the potential to unlock cost-efficient creation of more detailed maps.
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Apr 04, 2023Humans can orient themselves in their 3D environments using simple 2D maps. Differently, algorithms for visual localization mostly rely on complex 3D point clouds that are expensive to build, store, and maintain over time. We bridge this gap by introducing OrienterNet, the first deep neural network that can localize an image with sub-meter accuracy using the same 2D semantic maps that humans use. OrienterNet estimates the location and orientation of a query image by matching a neural Bird's-Eye View with open and globally available maps from OpenStreetMap, enabling anyone to localize anywhere such maps are available. OrienterNet is supervised only by camera poses but learns to perform semantic matching with a wide range of map elements in an end-to-end manner. To enable this, we introduce a large crowd-sourced dataset of images captured across 12 cities from the diverse viewpoints of cars, bikes, and pedestrians. OrienterNet generalizes to new datasets and pushes the state of the art in both robotics and AR scenarios. The code and trained model will be released publicly.