 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Apr 04, 2023Humans can orient themselves in their 3D environments using simple 2D maps. Differently, algorithms for visual localization mostly rely on complex 3D point clouds that are expensive to build, store, and maintain over time. We bridge this gap by introducing OrienterNet, the first deep neural network that can localize an image with sub-meter accuracy using the same 2D semantic maps that humans use. OrienterNet estimates the location and orientation of a query image by matching a neural Bird's-Eye View with open and globally available maps from OpenStreetMap, enabling anyone to localize anywhere such maps are available. OrienterNet is supervised only by camera poses but learns to perform semantic matching with a wide range of map elements in an end-to-end manner. To enable this, we introduce a large crowd-sourced dataset of images captured across 12 cities from the diverse viewpoints of cars, bikes, and pedestrians. OrienterNet generalizes to new datasets and pushes the state of the art in both robotics and AR scenarios. The code and trained model will be released publicly.
Shape Consistent 2D Keypoint Estimation under Domain Shift
Aug 04, 2020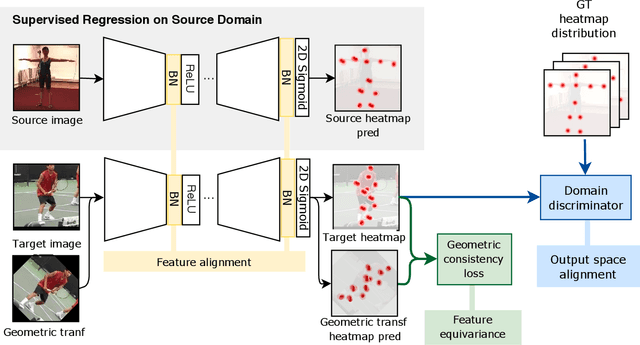

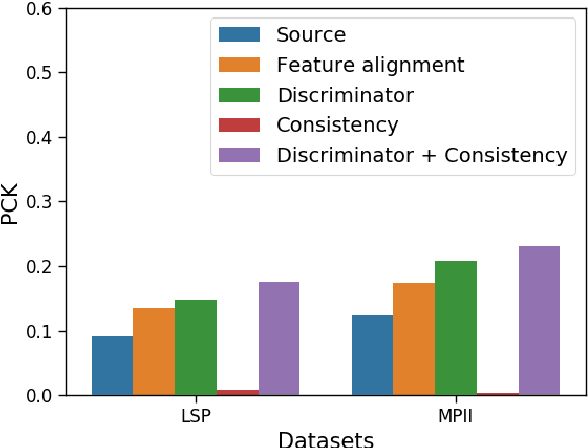
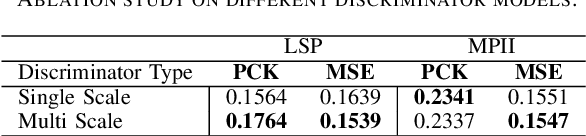
Recent unsupervised domain adaptation methods based on deep architectures have shown remarkable performance not only in traditional classification tasks but also in more complex problems involving structured predictions (e.g. semantic segmentation, depth estimation). Following this trend, in this paper we present a novel deep adaptation framework for estimating keypoints under domain shift}, i.e. when the training (source) and the test (target) images significantly differ in terms of visual appearance. Our method seamlessly combines three different components: feature alignment, adversarial training and self-supervision. Specifically, our deep architecture leverages from domain-specific distribution alignment layers to perform target adaptation at the feature level. Furthermore, a novel loss is proposed which combines an adversarial term for ensuring aligned predictions in the output space and a geometric consistency term which guarantees coherent predictions between a target sample and its perturbed version. Our extensive experimental evaluation conducted on three publicly available benchmarks shows that our approach outperforms state-of-the-art domain adaptation methods in the 2D keypoint prediction task.
Unsupervised Domain Adaptation using Feature-Whitening and Consensus Loss
Mar 07, 2019
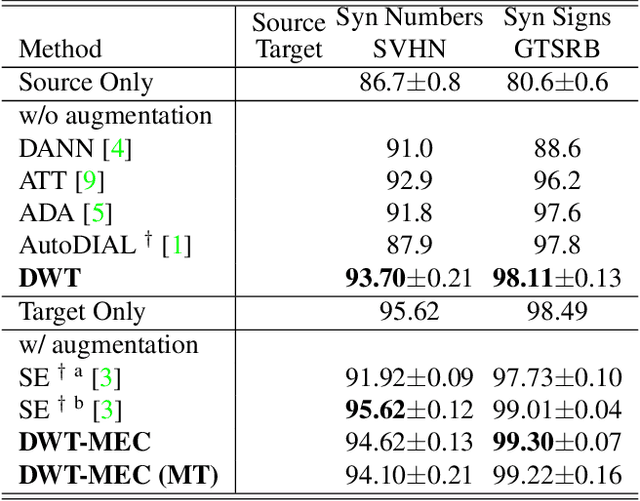


A classifier trained on a dataset seldom works on other datasets obtained under different conditions due to domain shift. This problem is commonly addressed by domain adaptation methods. In this work we introduce a novel deep learning framework which unifies different paradigms in unsupervised domain adaptation. Specifically, we propose domain alignment layers which implement feature whitening for the purpose of matching source and target feature distributions. Additionally, we leverage the unlabeled target data by proposing the Min-Entropy Consensus loss, which regularizes training while avoiding the adoption of many user-defined hyper-parameters. We report results on publicly available datasets, considering both digit classification and object recognition tasks. We show that, in most of our experiments, our approach improves upon previous methods, setting new state-of-the-art performances.