 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024

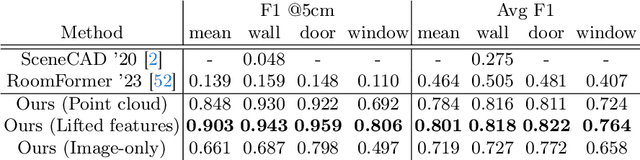
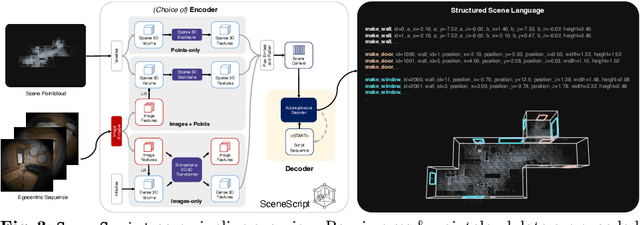
We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Apr 04, 2023Humans can orient themselves in their 3D environments using simple 2D maps. Differently, algorithms for visual localization mostly rely on complex 3D point clouds that are expensive to build, store, and maintain over time. We bridge this gap by introducing OrienterNet, the first deep neural network that can localize an image with sub-meter accuracy using the same 2D semantic maps that humans use. OrienterNet estimates the location and orientation of a query image by matching a neural Bird's-Eye View with open and globally available maps from OpenStreetMap, enabling anyone to localize anywhere such maps are available. OrienterNet is supervised only by camera poses but learns to perform semantic matching with a wide range of map elements in an end-to-end manner. To enable this, we introduce a large crowd-sourced dataset of images captured across 12 cities from the diverse viewpoints of cars, bikes, and pedestrians. OrienterNet generalizes to new datasets and pushes the state of the art in both robotics and AR scenarios. The code and trained model will be released publicly.
Nerfels: Renderable Neural Codes for Improved Camera Pose Estimation
Jun 04, 2022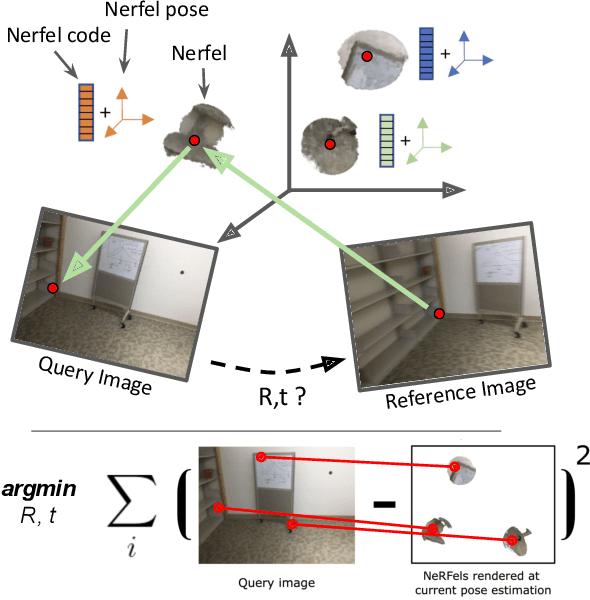
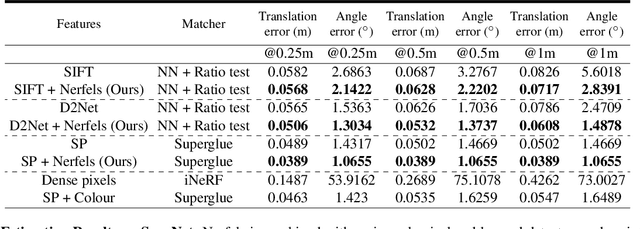


This paper presents a framework that combines traditional keypoint-based camera pose optimization with an invertible neural rendering mechanism. Our proposed 3D scene representation, Nerfels, is locally dense yet globally sparse. As opposed to existing invertible neural rendering systems which overfit a model to the entire scene, we adopt a feature-driven approach for representing scene-agnostic, local 3D patches with renderable codes. By modelling a scene only where local features are detected, our framework effectively generalizes to unseen local regions in the scene via an optimizable code conditioning mechanism in the neural renderer, all while maintaining the low memory footprint of a sparse 3D map representation. Our model can be incorporated to existing state-of-the-art hand-crafted and learned local feature pose estimators, yielding improved performance when evaluating on ScanNet for wide camera baseline scenarios.
NinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
Dec 23, 2021

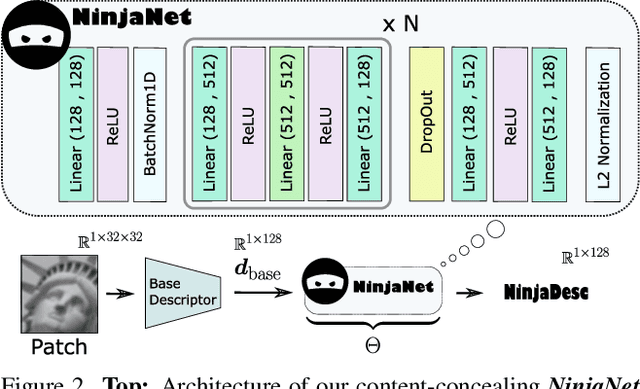
In the light of recent analyses on privacy-concerning scene revelation from visual descriptors, we develop descriptors that conceal the input image content. In particular, we propose an adversarial learning framework for training visual descriptors that prevent image reconstruction, while maintaining the matching accuracy. We let a feature encoding network and image reconstruction network compete with each other, such that the feature encoder tries to impede the image reconstruction with its generated descriptors, while the reconstructor tries to recover the input image from the descriptors. The experimental results demonstrate that the visual descriptors obtained with our method significantly deteriorate the image reconstruction quality with minimal impact on correspondence matching and camera localization performance.
UR2KiD: Unifying Retrieval, Keypoint Detection, and Keypoint Description without Local Correspondence Supervision
Jan 20, 2020
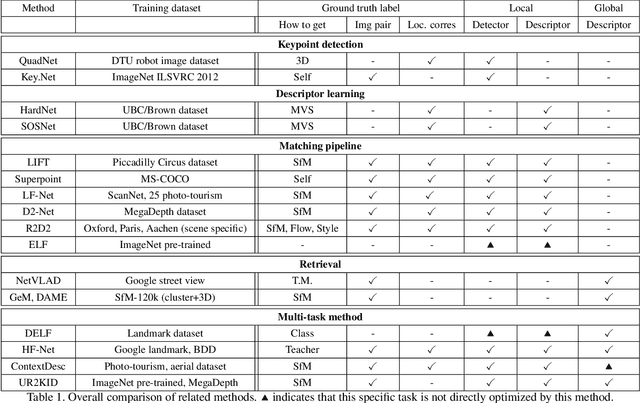

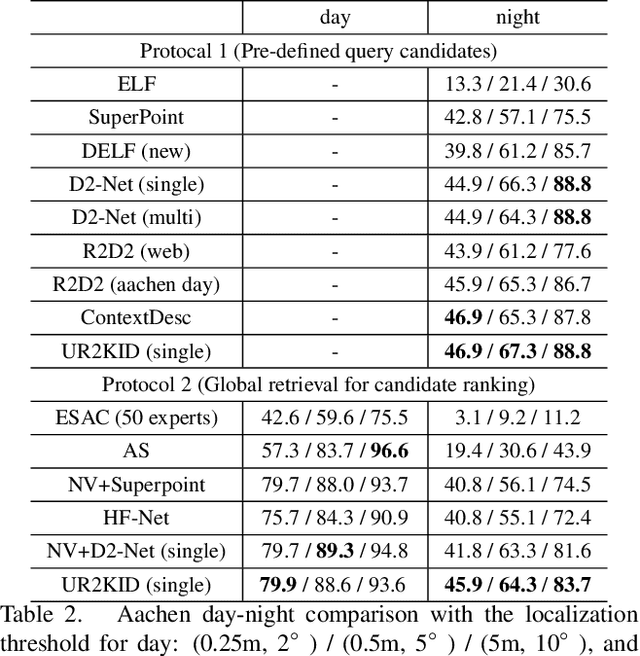
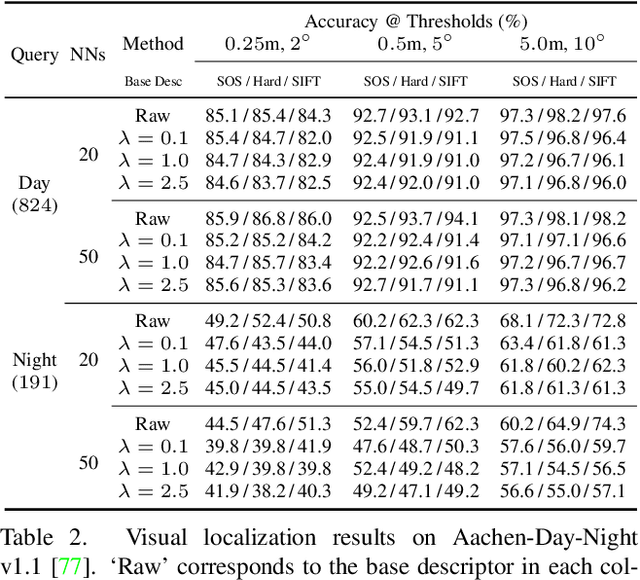
In this paper, we explore how three related tasks, namely keypoint detection, description, and image retrieval can be jointly tackled using a single unified framework, which is trained without the need of training data with point to point correspondences. By leveraging diverse information from sequential layers of a standard ResNet-based architecture, we are able to extract keypoints and descriptors that encode local information using generic techniques such as local activation norms, channel grouping and dropping, and self-distillation. Subsequently, global information for image retrieval is encoded in an end-to-end pipeline, based on pooling of the aforementioned local responses. In contrast to previous methods in local matching, our method does not depend on pointwise/pixelwise correspondences, and requires no such supervision at all i.e. no depth-maps from an SfM model nor manually created synthetic affine transformations. We illustrate that this simple and direct paradigm, is able to achieve very competitive results against the state-of-the-art methods in various challenging benchmark conditions such as viewpoint changes, scale changes, and day-night shifting localization.