 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Image is Worth More Than 16x16 Patches: Exploring Transformers on Individual Pixels
Jun 13, 2024This work does not introduce a new method. Instead, we present an interesting finding that questions the necessity of the inductive bias -- locality in modern computer vision architectures. Concretely, we find that vanilla Transformers can operate by directly treating each individual pixel as a token and achieve highly performant results. This is substantially different from the popular design in Vision Transformer, which maintains the inductive bias from ConvNets towards local neighborhoods (e.g. by treating each 16x16 patch as a token). We mainly showcase the effectiveness of pixels-as-tokens across three well-studied tasks in computer vision: supervised learning for object classification, self-supervised learning via masked autoencoding, and image generation with diffusion models. Although directly operating on individual pixels is less computationally practical, we believe the community must be aware of this surprising piece of knowledge when devising the next generation of neural architectures for computer vision.
SimPLR: A Simple and Plain Transformer for Object Detection and Segmentation
Oct 09, 2023The ability to detect objects in images at varying scales has played a pivotal role in the design of modern object detectors. Despite considerable progress in removing handcrafted components using transformers, multi-scale feature maps remain a key factor for their empirical success, even with a plain backbone like the Vision Transformer (ViT). In this paper, we show that this reliance on feature pyramids is unnecessary and a transformer-based detector with scale-aware attention enables the plain detector `SimPLR' whose backbone and detection head both operate on single-scale features. The plain architecture allows SimPLR to effectively take advantages of self-supervised learning and scaling approaches with ViTs, yielding strong performance compared to multi-scale counterparts. We demonstrate through our experiments that when scaling to larger backbones, SimPLR indicates better performance than end-to-end detectors (Mask2Former) and plain-backbone detectors (ViTDet), while consistently being faster. The code will be released.
R-MAE: Regions Meet Masked Autoencoders
Jun 08, 2023Vision-specific concepts such as "region" have played a key role in extending general machine learning frameworks to tasks like object detection. Given the success of region-based detectors for supervised learning and the progress of intra-image methods for contrastive learning, we explore the use of regions for reconstructive pre-training. Starting from Masked Autoencoding (MAE) both as a baseline and an inspiration, we propose a parallel pre-text task tailored to address the one-to-many mapping between images and regions. Since such regions can be generated in an unsupervised way, our approach (R-MAE) inherits the wide applicability from MAE, while being more "region-aware". We conduct thorough analyses during the development of R-MAE, and converge on a variant that is both effective and efficient (1.3% overhead over MAE). Moreover, it shows consistent quantitative improvements when generalized to various pre-training data and downstream detection and segmentation benchmarks. Finally, we provide extensive qualitative visualizations to enhance the understanding of R-MAE's behaviour and potential. Code will be made available at https://github.com/facebookresearch/r-mae.
BoxeR: Box-Attention for 2D and 3D Transformers
Nov 25, 2021
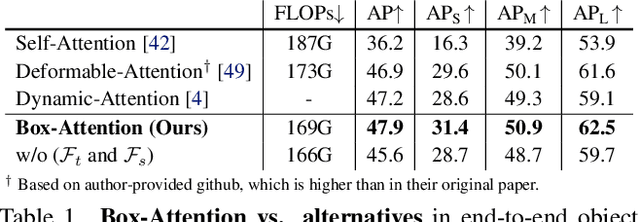
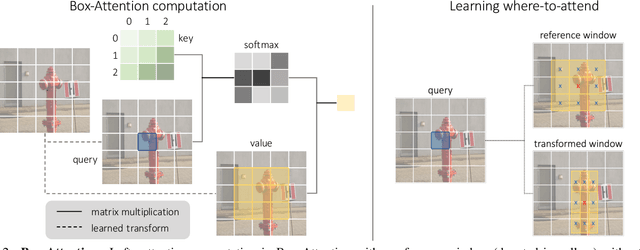

In this paper, we propose a simple attention mechanism, we call Box-Attention. It enables spatial interaction between grid features, as sampled from boxes of interest, and improves the learning capability of transformers for several vision tasks. Specifically, we present BoxeR, short for Box Transformer, which attends to a set of boxes by predicting their transformation from a reference window on an input feature map. The BoxeR computes attention weights on these boxes by considering its grid structure. Notably, BoxeR-2D naturally reasons about box information within its attention module, making it suitable for end-to-end instance detection and segmentation tasks. By learning invariance to rotation in the box-attention module, BoxeR-3D is capable of generating discriminative information from a bird-eye-view plane for 3D end-to-end object detection. Our experiments demonstrate that the proposed BoxeR-2D achieves better results on COCO detection, and reaches comparable performance with well-established and highly-optimized Mask R-CNN on COCO instance segmentation. BoxeR-3D already obtains a compelling performance for the vehicle category of Waymo Open, without any class-specific optimization. The code will be released.
Revisiting Modulated Convolutions for Visual Counting and Beyond
Apr 24, 2020



This paper targets at visual counting, where the setup is to estimate the total number of occurrences in a natural image given an input query (e.g. a question or a category). Most existing work for counting focuses on explicit, symbolic models that iteratively examine relevant regions to arrive at the final number, mimicking the intuitive process specifically for counting. However, such models can be computationally expensive, and more importantly place a limit on their generalization to other reasoning tasks. In this paper, we propose a simple and effective alternative for visual counting by revisiting modulated convolutions that fuse query and image locally. The modulation is performed on a per-bottleneck basis by fusing query representations with input convolutional feature maps of that residual bottleneck. Therefore, we call our method MoVie, short for Modulated conVolutional bottleneck. Notably, MoVie reasons implicitly and holistically for counting and only needs a single forward-pass during inference. Nevertheless, MoVie showcases strong empirical performance. First, it significantly advances the state-of-the-art accuracies on multiple counting-specific Visual Question Answering (VQA) datasets (i.e., HowMany-QA and TallyQA). Moreover, it also works on common object counting, outperforming prior-art on difficult benchmarks like COCO. Third, integrated as a module, MoVie can be used to improve number-related questions for generic VQA models. Finally, we find MoVie achieves similar, near-perfect results on CLEVR and competitive ones on GQA, suggesting modulated convolutions as a mechanism can be useful for more general reasoning tasks beyond counting.
UR2KiD: Unifying Retrieval, Keypoint Detection, and Keypoint Description without Local Correspondence Supervision
Jan 20, 2020
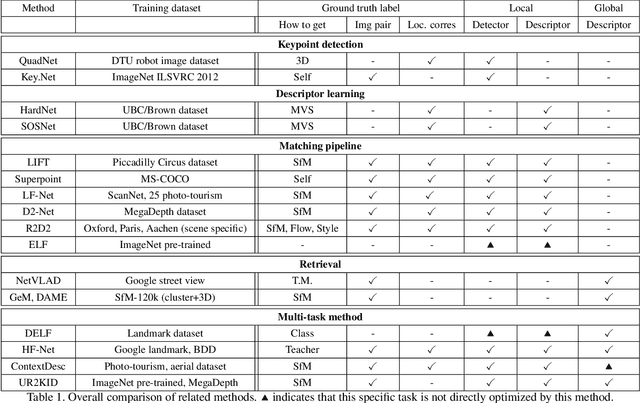

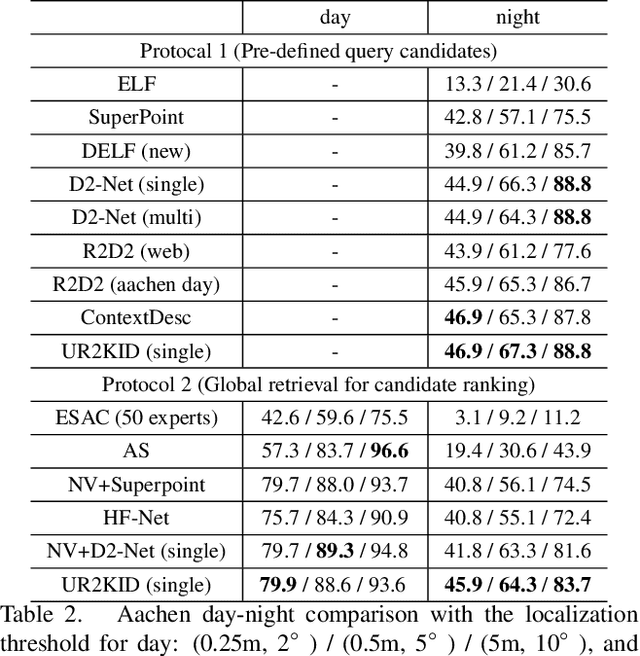
In this paper, we explore how three related tasks, namely keypoint detection, description, and image retrieval can be jointly tackled using a single unified framework, which is trained without the need of training data with point to point correspondences. By leveraging diverse information from sequential layers of a standard ResNet-based architecture, we are able to extract keypoints and descriptors that encode local information using generic techniques such as local activation norms, channel grouping and dropping, and self-distillation. Subsequently, global information for image retrieval is encoded in an end-to-end pipeline, based on pooling of the aforementioned local responses. In contrast to previous methods in local matching, our method does not depend on pointwise/pixelwise correspondences, and requires no such supervision at all i.e. no depth-maps from an SfM model nor manually created synthetic affine transformations. We illustrate that this simple and direct paradigm, is able to achieve very competitive results against the state-of-the-art methods in various challenging benchmark conditions such as viewpoint changes, scale changes, and day-night shifting localization.
Multi-task Learning of Hierarchical Vision-Language Representation
Dec 03, 2018



It is still challenging to build an AI system that can perform tasks that involve vision and language at human level. So far, researchers have singled out individual tasks separately, for each of which they have designed networks and trained them on its dedicated datasets. Although this approach has seen a certain degree of success, it comes with difficulties of understanding relations among different tasks and transferring the knowledge learned for a task to others. We propose a multi-task learning approach that enables to learn vision-language representation that is shared by many tasks from their diverse datasets. The representation is hierarchical, and prediction for each task is computed from the representation at its corresponding level of the hierarchy. We show through experiments that our method consistently outperforms previous single-task-learning methods on image caption retrieval, visual question answering, and visual grounding. We also analyze the learned hierarchical representation by visualizing attention maps generated in our network.
Improved Fusion of Visual and Language Representations by Dense Symmetric Co-Attention for Visual Question Answering
Apr 03, 2018


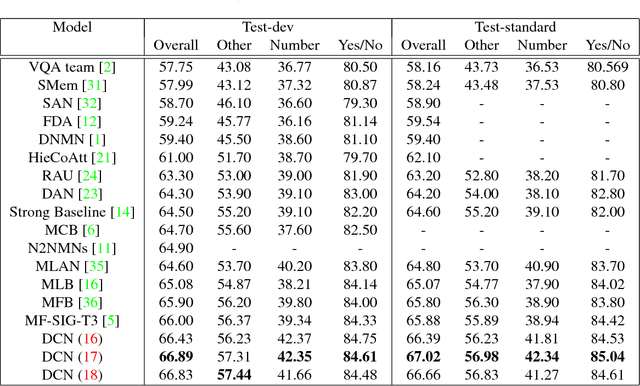
A key solution to visual question answering (VQA) exists in how to fuse visual and language features extracted from an input image and question. We show that an attention mechanism that enables dense, bi-directional interactions between the two modalities contributes to boost accuracy of prediction of answers. Specifically, we present a simple architecture that is fully symmetric between visual and language representations, in which each question word attends on image regions and each image region attends on question words. It can be stacked to form a hierarchy for multi-step interactions between an image-question pair. We show through experiments that the proposed architecture achieves a new state-of-the-art on VQA and VQA 2.0 despite its small size. We also present qualitative evaluation, demonstrating how the proposed attention mechanism can generate reasonable attention maps on images and questions, which leads to the correct answer prediction.