 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
R-MAE: Regions Meet Masked Autoencoders
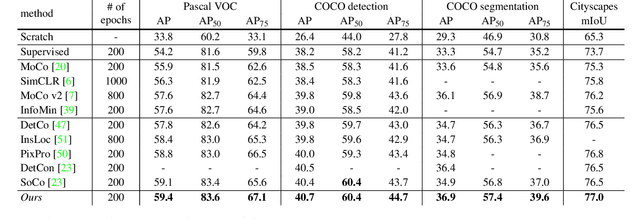
Jun 08, 2023Vision-specific concepts such as "region" have played a key role in extending general machine learning frameworks to tasks like object detection. Given the success of region-based detectors for supervised learning and the progress of intra-image methods for contrastive learning, we explore the use of regions for reconstructive pre-training. Starting from Masked Autoencoding (MAE) both as a baseline and an inspiration, we propose a parallel pre-text task tailored to address the one-to-many mapping between images and regions. Since such regions can be generated in an unsupervised way, our approach (R-MAE) inherits the wide applicability from MAE, while being more "region-aware". We conduct thorough analyses during the development of R-MAE, and converge on a variant that is both effective and efficient (1.3% overhead over MAE). Moreover, it shows consistent quantitative improvements when generalized to various pre-training data and downstream detection and segmentation benchmarks. Finally, we provide extensive qualitative visualizations to enhance the understanding of R-MAE's behaviour and potential. Code will be made available at https://github.com/facebookresearch/r-mae.
Segment Anything
Apr 05, 2023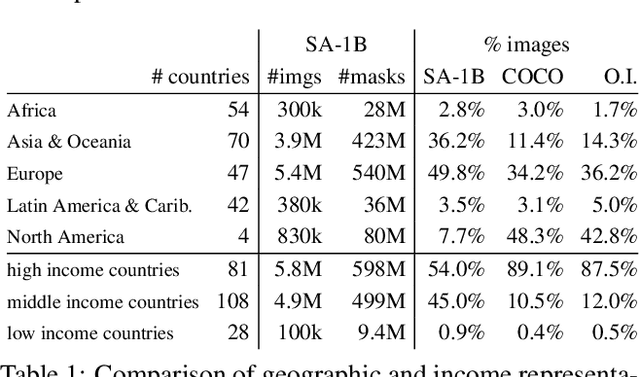

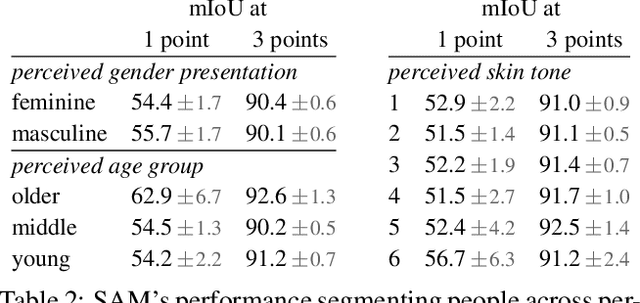

We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive -- often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images at https://segment-anything.com to foster research into foundation models for computer vision.
Point-Level Region Contrast for Object Detection Pre-Training
Feb 09, 2022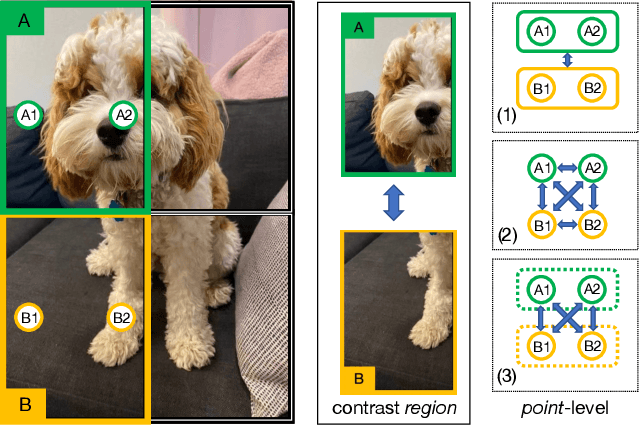
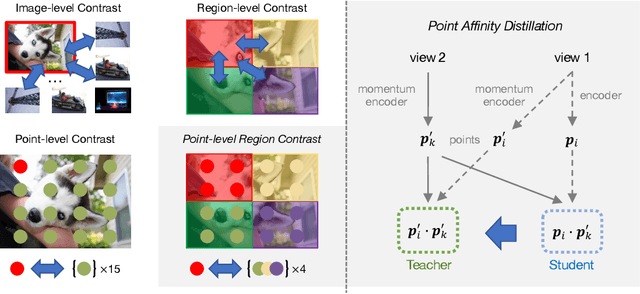

In this work we present point-level region contrast, a self-supervised pre-training approach for the task of object detection. This approach is motivated by the two key factors in detection: localization and recognition. While accurate localization favors models that operate at the pixel- or point-level, correct recognition typically relies on a more holistic, region-level view of objects. Incorporating this perspective in pre-training, our approach performs contrastive learning by directly sampling individual point pairs from different regions. Compared to an aggregated representation per region, our approach is more robust to the change in input region quality, and further enables us to implicitly improve initial region assignments via online knowledge distillation during training. Both advantages are important when dealing with imperfect regions encountered in the unsupervised setting. Experiments show point-level region contrast improves on state-of-the-art pre-training methods for object detection and segmentation across multiple tasks and datasets, and we provide extensive ablation studies and visualizations to aid understanding. Code will be made available.
SLIP: Self-supervision meets Language-Image Pre-training
Dec 23, 2021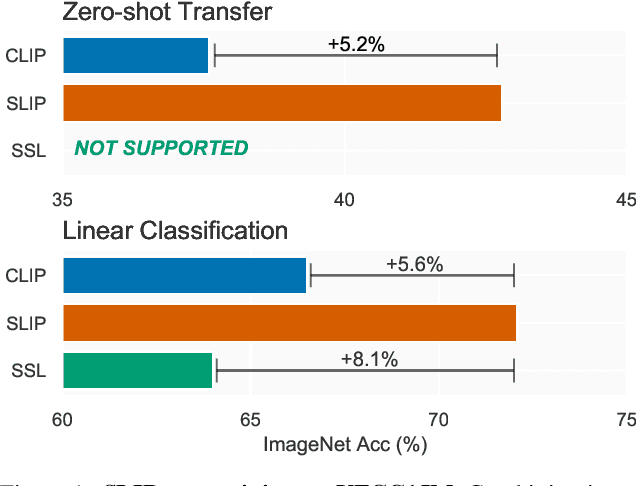
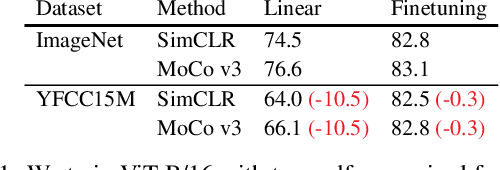
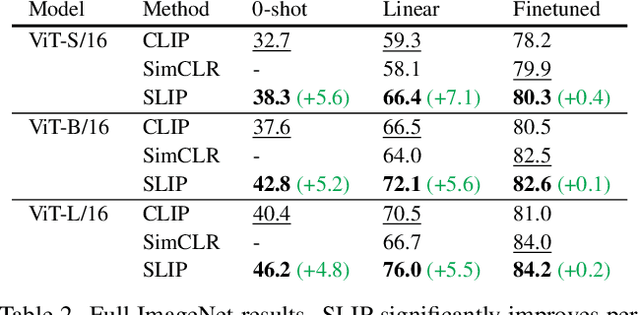
Recent work has shown that self-supervised pre-training leads to improvements over supervised learning on challenging visual recognition tasks. CLIP, an exciting new approach to learning with language supervision, demonstrates promising performance on a wide variety of benchmarks. In this work, we explore whether self-supervised learning can aid in the use of language supervision for visual representation learning. We introduce SLIP, a multi-task learning framework for combining self-supervised learning and CLIP pre-training. After pre-training with Vision Transformers, we thoroughly evaluate representation quality and compare performance to both CLIP and self-supervised learning under three distinct settings: zero-shot transfer, linear classification, and end-to-end finetuning. Across ImageNet and a battery of additional datasets, we find that SLIP improves accuracy by a large margin. We validate our results further with experiments on different model sizes, training schedules, and pre-training datasets. Our findings show that SLIP enjoys the best of both worlds: better performance than self-supervision (+8.1% linear accuracy) and language supervision (+5.2% zero-shot accuracy).
Mask2Former for Video Instance Segmentation
Dec 20, 2021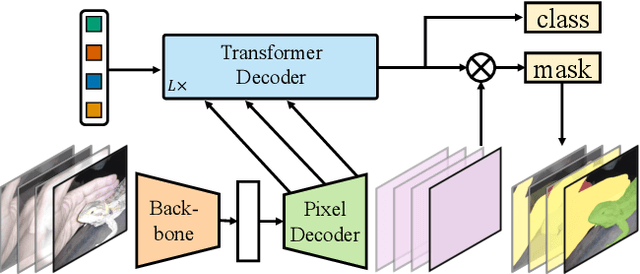
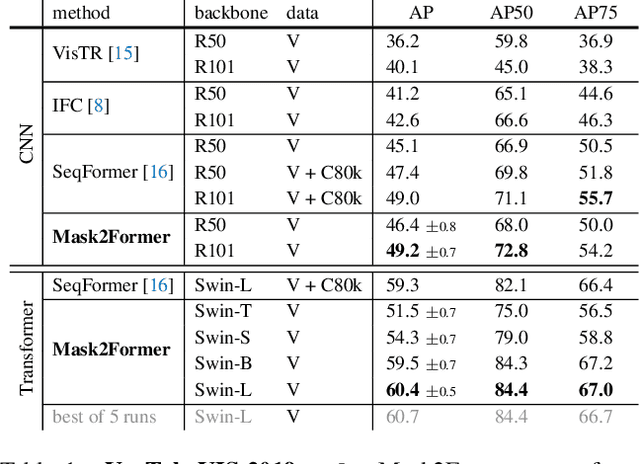
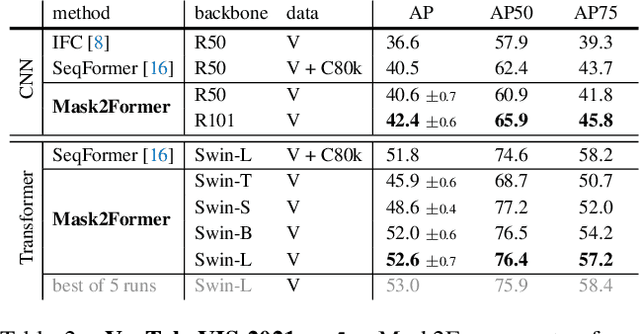
We find Mask2Former also achieves state-of-the-art performance on video instance segmentation without modifying the architecture, the loss or even the training pipeline. In this report, we show universal image segmentation architectures trivially generalize to video segmentation by directly predicting 3D segmentation volumes. Specifically, Mask2Former sets a new state-of-the-art of 60.4 AP on YouTubeVIS-2019 and 52.6 AP on YouTubeVIS-2021. We believe Mask2Former is also capable of handling video semantic and panoptic segmentation, given its versatility in image segmentation. We hope this will make state-of-the-art video segmentation research more accessible and bring more attention to designing universal image and video segmentation architectures.
Masked-attention Mask Transformer for Universal Image Segmentation
Dec 10, 2021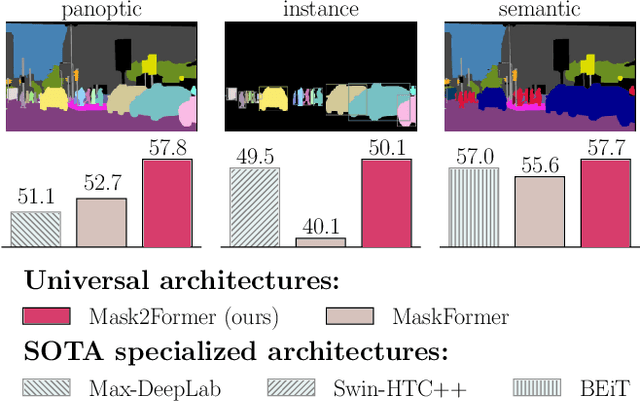
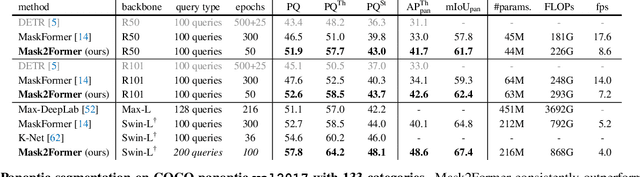
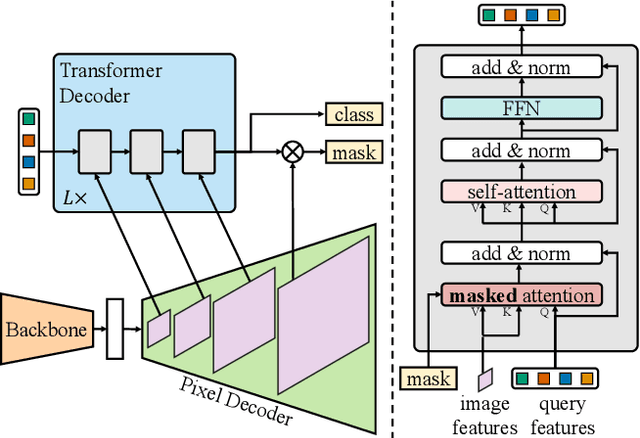
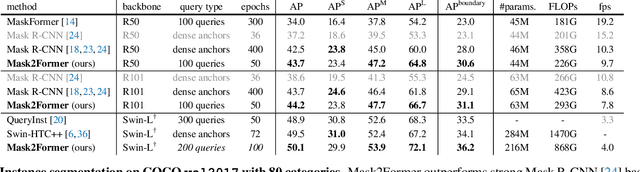
Image segmentation is about grouping pixels with different semantics, e.g., category or instance membership, where each choice of semantics defines a task. While only the semantics of each task differ, current research focuses on designing specialized architectures for each task. We present Masked-attention Mask Transformer (Mask2Former), a new architecture capable of addressing any image segmentation task (panoptic, instance or semantic). Its key components include masked attention, which extracts localized features by constraining cross-attention within predicted mask regions. In addition to reducing the research effort by at least three times, it outperforms the best specialized architectures by a significant margin on four popular datasets. Most notably, Mask2Former sets a new state-of-the-art for panoptic segmentation (57.8 PQ on COCO), instance segmentation (50.1 AP on COCO) and semantic segmentation (57.7 mIoU on ADE20K).
Recognizing Scenes from Novel Viewpoints
Dec 02, 2021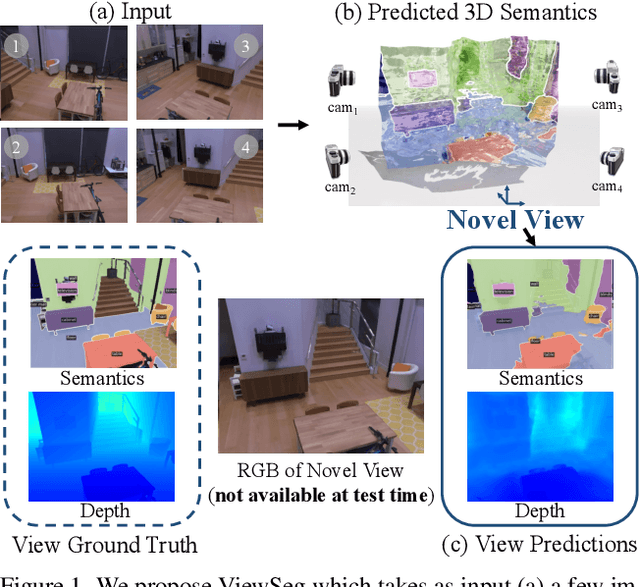

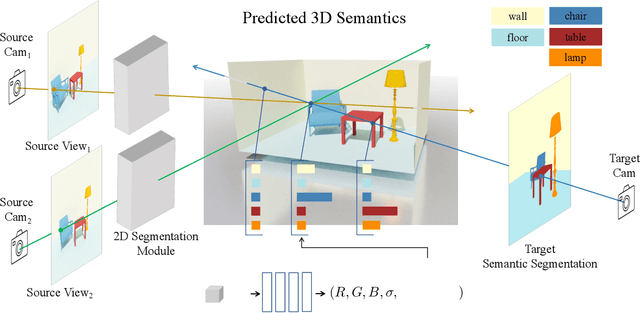

Humans can perceive scenes in 3D from a handful of 2D views. For AI agents, the ability to recognize a scene from any viewpoint given only a few images enables them to efficiently interact with the scene and its objects. In this work, we attempt to endow machines with this ability. We propose a model which takes as input a few RGB images of a new scene and recognizes the scene from novel viewpoints by segmenting it into semantic categories. All this without access to the RGB images from those views. We pair 2D scene recognition with an implicit 3D representation and learn from multi-view 2D annotations of hundreds of scenes without any 3D supervision beyond camera poses. We experiment on challenging datasets and demonstrate our model's ability to jointly capture semantics and geometry of novel scenes with diverse layouts, object types and shapes.
Per-Pixel Classification is Not All You Need for Semantic Segmentation
Jul 13, 2021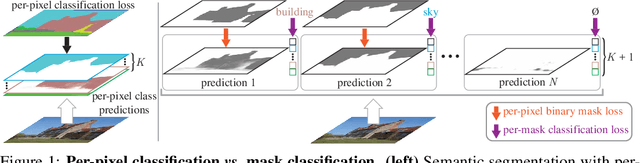
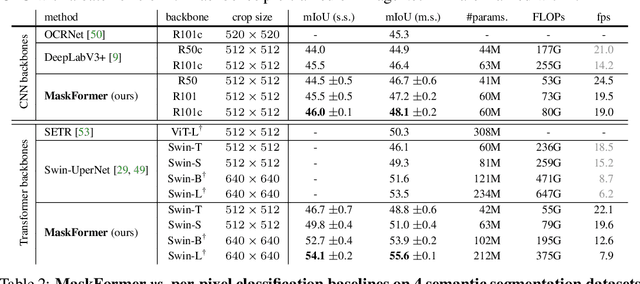
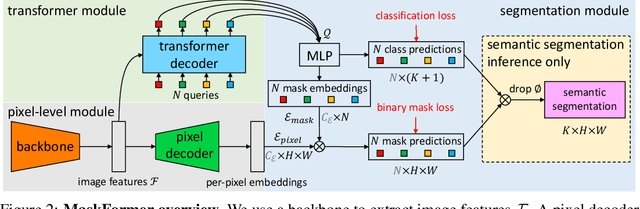

Modern approaches typically formulate semantic segmentation as a per-pixel classification task, while instance-level segmentation is handled with an alternative mask classification. Our key insight: mask classification is sufficiently general to solve both semantic- and instance-level segmentation tasks in a unified manner using the exact same model, loss, and training procedure. Following this observation, we propose MaskFormer, a simple mask classification model which predicts a set of binary masks, each associated with a single global class label prediction. Overall, the proposed mask classification-based method simplifies the landscape of effective approaches to semantic and panoptic segmentation tasks and shows excellent empirical results. In particular, we observe that MaskFormer outperforms per-pixel classification baselines when the number of classes is large. Our mask classification-based method outperforms both current state-of-the-art semantic (55.6 mIoU on ADE20K) and panoptic segmentation (52.7 PQ on COCO) models.
Pointly-Supervised Instance Segmentation
Apr 13, 2021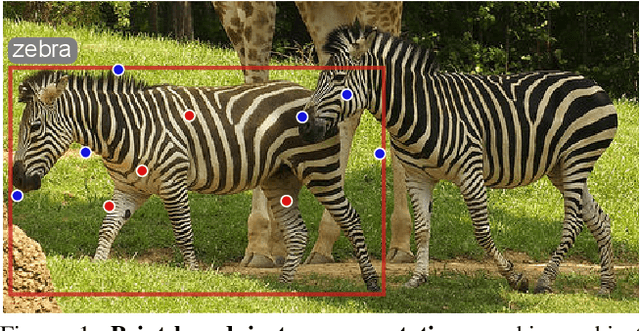

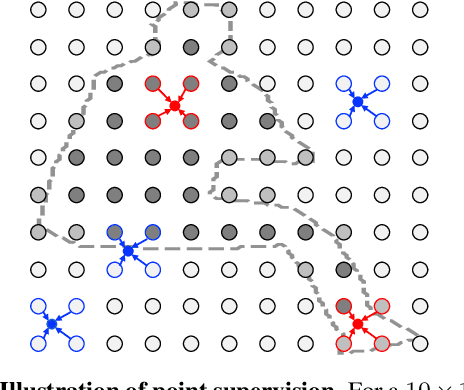

We propose point-based instance-level annotation, a new form of weak supervision for instance segmentation. It combines the standard bounding box annotation with labeled points that are uniformly sampled inside each bounding box. We show that the existing instance segmentation models developed for full mask supervision, like Mask R-CNN, can be seamlessly trained with the point-based annotation without any major modifications. In our experiments, Mask R-CNN models trained on COCO, PASCAL VOC, Cityscapes, and LVIS with only 10 annotated points per object achieve 94%--98% of their fully-supervised performance. The new point-based annotation is approximately 5 times faster to collect than object masks, making high-quality instance segmentation more accessible for new data. Inspired by the new annotation form, we propose a modification to PointRend instance segmentation module. For each object, the new architecture, called Implicit PointRend, generates parameters for a function that makes the final point-level mask prediction. Implicit PointRend is more straightforward and uses a single point-level mask loss. Our experiments show that the new module is more suitable for the proposed point-based supervision.