 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReading Recognition in the Wild
May 30, 2025To enable egocentric contextual AI in always-on smart glasses, it is crucial to be able to keep a record of the user's interactions with the world, including during reading. In this paper, we introduce a new task of reading recognition to determine when the user is reading. We first introduce the first-of-its-kind large-scale multimodal Reading in the Wild dataset, containing 100 hours of reading and non-reading videos in diverse and realistic scenarios. We then identify three modalities (egocentric RGB, eye gaze, head pose) that can be used to solve the task, and present a flexible transformer model that performs the task using these modalities, either individually or combined. We show that these modalities are relevant and complementary to the task, and investigate how to efficiently and effectively encode each modality. Additionally, we show the usefulness of this dataset towards classifying types of reading, extending current reading understanding studies conducted in constrained settings to larger scale, diversity and realism. Code, model, and data will be public.
CrossScore: Towards Multi-View Image Evaluation and Scoring
Apr 22, 2024We introduce a novel cross-reference image quality assessment method that effectively fills the gap in the image assessment landscape, complementing the array of established evaluation schemes -- ranging from full-reference metrics like SSIM, no-reference metrics such as NIQE, to general-reference metrics including FID, and Multi-modal-reference metrics, e.g., CLIPScore. Utilising a neural network with the cross-attention mechanism and a unique data collection pipeline from NVS optimisation, our method enables accurate image quality assessment without requiring ground truth references. By comparing a query image against multiple views of the same scene, our method addresses the limitations of existing metrics in novel view synthesis (NVS) and similar tasks where direct reference images are unavailable. Experimental results show that our method is closely correlated to the full-reference metric SSIM, while not requiring ground truth references.
Aria Everyday Activities Dataset
Feb 22, 2024



We present Aria Everyday Activities (AEA) Dataset, an egocentric multimodal open dataset recorded using Project Aria glasses. AEA contains 143 daily activity sequences recorded by multiple wearers in five geographically diverse indoor locations. Each of the recording contains multimodal sensor data recorded through the Project Aria glasses. In addition, AEA provides machine perception data including high frequency globally aligned 3D trajectories, scene point cloud, per-frame 3D eye gaze vector and time aligned speech transcription. In this paper, we demonstrate a few exemplar research applications enabled by this dataset, including neural scene reconstruction and prompted segmentation. AEA is an open source dataset that can be downloaded from https://www.projectaria.com/datasets/aea/. We are also providing open-source implementations and examples of how to use the dataset in Project Aria Tools https://github.com/facebookresearch/projectaria_tools.
Aria Digital Twin: A New Benchmark Dataset for Egocentric 3D Machine Perception
Jun 13, 2023
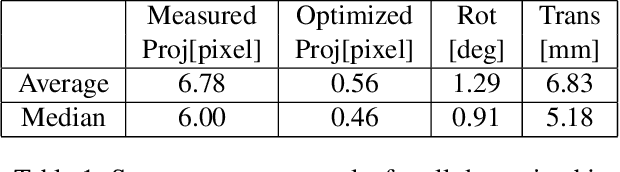
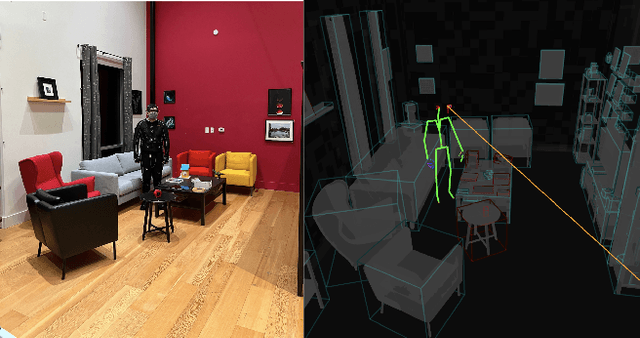
We introduce the Aria Digital Twin (ADT) - an egocentric dataset captured using Aria glasses with extensive object, environment, and human level ground truth. This ADT release contains 200 sequences of real-world activities conducted by Aria wearers in two real indoor scenes with 398 object instances (324 stationary and 74 dynamic). Each sequence consists of: a) raw data of two monochrome camera streams, one RGB camera stream, two IMU streams; b) complete sensor calibration; c) ground truth data including continuous 6-degree-of-freedom (6DoF) poses of the Aria devices, object 6DoF poses, 3D eye gaze vectors, 3D human poses, 2D image segmentations, image depth maps; and d) photo-realistic synthetic renderings. To the best of our knowledge, there is no existing egocentric dataset with a level of accuracy, photo-realism and comprehensiveness comparable to ADT. By contributing ADT to the research community, our mission is to set a new standard for evaluation in the egocentric machine perception domain, which includes very challenging research problems such as 3D object detection and tracking, scene reconstruction and understanding, sim-to-real learning, human pose prediction - while also inspiring new machine perception tasks for augmented reality (AR) applications. To kick start exploration of the ADT research use cases, we evaluated several existing state-of-the-art methods for object detection, segmentation and image translation tasks that demonstrate the usefulness of ADT as a benchmarking dataset.
End-to-End Visual Editing with a Generatively Pre-Trained Artist
May 03, 2022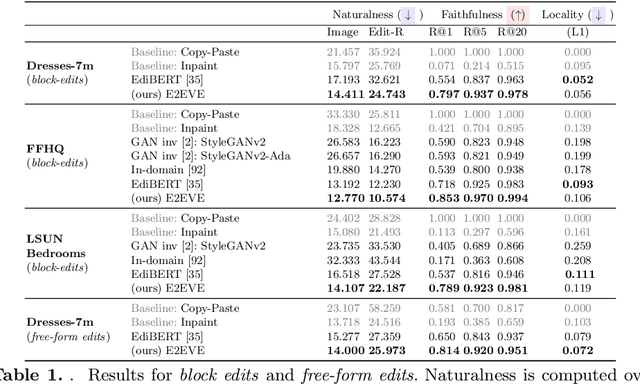

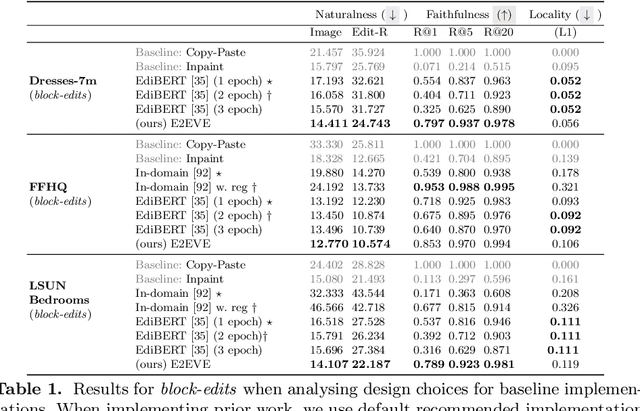
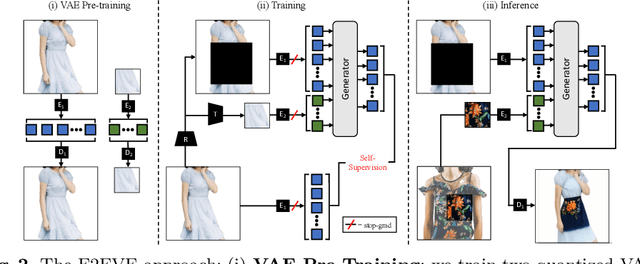
We consider the targeted image editing problem: blending a region in a source image with a driver image that specifies the desired change. Differently from prior works, we solve this problem by learning a conditional probability distribution of the edits, end-to-end. Training such a model requires addressing a fundamental technical challenge: the lack of example edits for training. To this end, we propose a self-supervised approach that simulates edits by augmenting off-the-shelf images in a target domain. The benefits are remarkable: implemented as a state-of-the-art auto-regressive transformer, our approach is simple, sidesteps difficulties with previous methods based on GAN-like priors, obtains significantly better edits, and is efficient. Furthermore, we show that different blending effects can be learned by an intuitive control of the augmentation process, with no other changes required to the model architecture. We demonstrate the superiority of this approach across several datasets in extensive quantitative and qualitative experiments, including human studies, significantly outperforming prior work.
Pointly-Supervised Instance Segmentation
Apr 13, 2021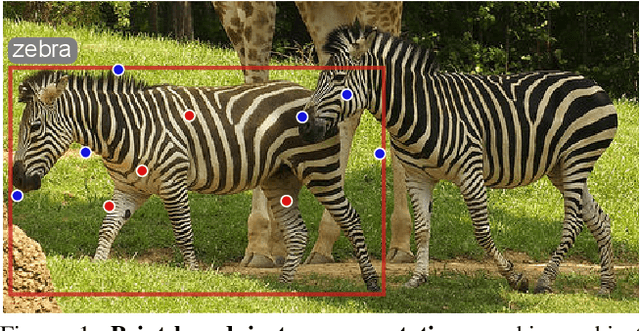

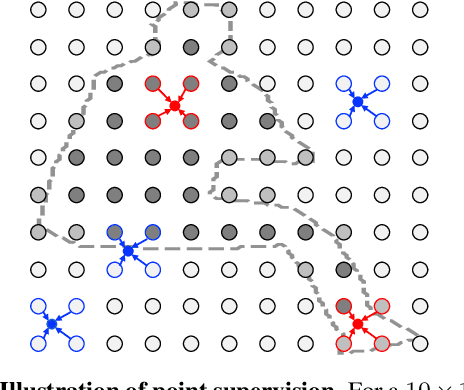

We propose point-based instance-level annotation, a new form of weak supervision for instance segmentation. It combines the standard bounding box annotation with labeled points that are uniformly sampled inside each bounding box. We show that the existing instance segmentation models developed for full mask supervision, like Mask R-CNN, can be seamlessly trained with the point-based annotation without any major modifications. In our experiments, Mask R-CNN models trained on COCO, PASCAL VOC, Cityscapes, and LVIS with only 10 annotated points per object achieve 94%--98% of their fully-supervised performance. The new point-based annotation is approximately 5 times faster to collect than object masks, making high-quality instance segmentation more accessible for new data. Inspired by the new annotation form, we propose a modification to PointRend instance segmentation module. For each object, the new architecture, called Implicit PointRend, generates parameters for a function that makes the final point-level mask prediction. Implicit PointRend is more straightforward and uses a single point-level mask loss. Our experiments show that the new module is more suitable for the proposed point-based supervision.