 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin Catalog: A Large-Scale Photorealistic 3D Object Digital Twin Dataset
Apr 11, 2025



We introduce Digital Twin Catalog (DTC), a new large-scale photorealistic 3D object digital twin dataset. A digital twin of a 3D object is a highly detailed, virtually indistinguishable representation of a physical object, accurately capturing its shape, appearance, physical properties, and other attributes. Recent advances in neural-based 3D reconstruction and inverse rendering have significantly improved the quality of 3D object reconstruction. Despite these advancements, there remains a lack of a large-scale, digital twin quality real-world dataset and benchmark that can quantitatively assess and compare the performance of different reconstruction methods, as well as improve reconstruction quality through training or fine-tuning. Moreover, to democratize 3D digital twin creation, it is essential to integrate creation techniques with next-generation egocentric computing platforms, such as AR glasses. Currently, there is no dataset available to evaluate 3D object reconstruction using egocentric captured images. To address these gaps, the DTC dataset features 2,000 scanned digital twin-quality 3D objects, along with image sequences captured under different lighting conditions using DSLR cameras and egocentric AR glasses. This dataset establishes the first comprehensive real-world evaluation benchmark for 3D digital twin creation tasks, offering a robust foundation for comparing and improving existing reconstruction methods. The DTC dataset is already released at https://www.projectaria.com/datasets/dtc/ and we will also make the baseline evaluations open-source.
Learnable Wireless Digital Twins: Reconstructing Electromagnetic Field with Neural Representations
Sep 04, 2024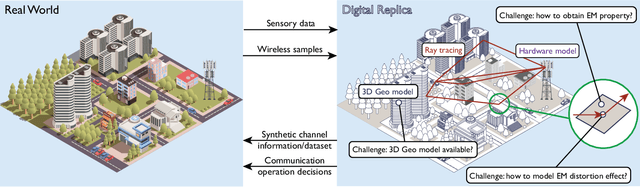
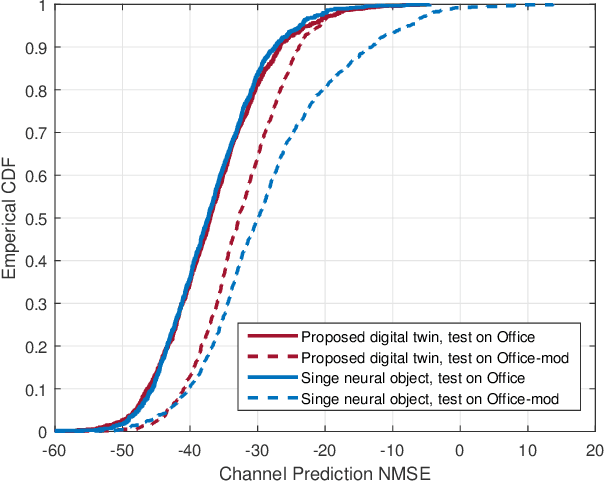
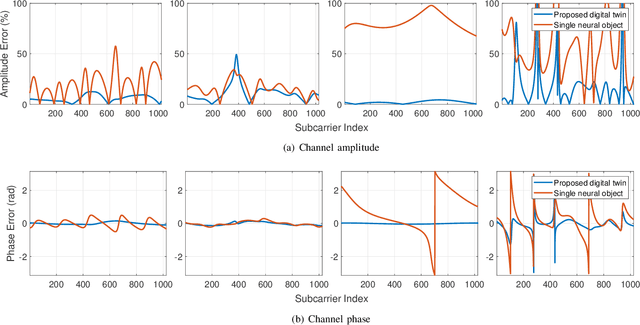
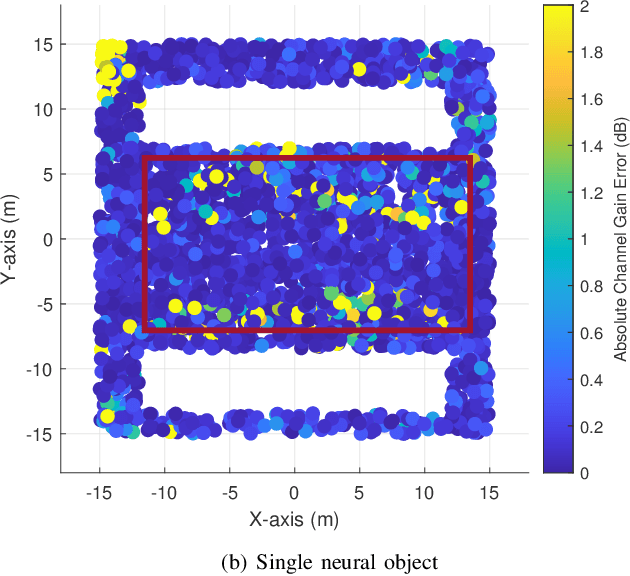
Fully harvesting the gain of multiple-input and multiple-output (MIMO) requires accurate channel information. However, conventional channel acquisition methods mainly rely on pilot training signals, resulting in significant training overheads (time, energy, spectrum). Digital twin-aided communications have been proposed in [1] to reduce or eliminate this overhead by approximating the real world with a digital replica. However, how to implement a digital twin-aided communication system brings new challenges. In particular, how to model the 3D environment and the associated EM properties, as well as how to update the environment dynamics in a coherent manner. To address these challenges, motivated by the latest advancements in computer vision, 3D reconstruction and neural radiance field, we propose an end-to-end deep learning framework for future generation wireless systems that can reconstruct the 3D EM field covered by a wireless access point, based on widely available crowd-sourced world-locked wireless samples between the access point and the devices. This visionary framework is grounded in classical EM theory and employs deep learning models to learn the EM properties and interaction behaviors of the objects in the environment. Simulation results demonstrate that the proposed learnable digital twin can implicitly learn the EM properties of the objects, accurately predict wireless channels, and generalize to changes in the environment, highlighting the prospect of this novel direction for future generation wireless platforms.
Aria Everyday Activities Dataset
Feb 22, 2024



We present Aria Everyday Activities (AEA) Dataset, an egocentric multimodal open dataset recorded using Project Aria glasses. AEA contains 143 daily activity sequences recorded by multiple wearers in five geographically diverse indoor locations. Each of the recording contains multimodal sensor data recorded through the Project Aria glasses. In addition, AEA provides machine perception data including high frequency globally aligned 3D trajectories, scene point cloud, per-frame 3D eye gaze vector and time aligned speech transcription. In this paper, we demonstrate a few exemplar research applications enabled by this dataset, including neural scene reconstruction and prompted segmentation. AEA is an open source dataset that can be downloaded from https://www.projectaria.com/datasets/aea/. We are also providing open-source implementations and examples of how to use the dataset in Project Aria Tools https://github.com/facebookresearch/projectaria_tools.
Ego-Exo4D: Understanding Skilled Human Activity from First- and Third-Person Perspectives
Nov 30, 2023



We present Ego-Exo4D, a diverse, large-scale multimodal multiview video dataset and benchmark challenge. Ego-Exo4D centers around simultaneously-captured egocentric and exocentric video of skilled human activities (e.g., sports, music, dance, bike repair). More than 800 participants from 13 cities worldwide performed these activities in 131 different natural scene contexts, yielding long-form captures from 1 to 42 minutes each and 1,422 hours of video combined. The multimodal nature of the dataset is unprecedented: the video is accompanied by multichannel audio, eye gaze, 3D point clouds, camera poses, IMU, and multiple paired language descriptions -- including a novel "expert commentary" done by coaches and teachers and tailored to the skilled-activity domain. To push the frontier of first-person video understanding of skilled human activity, we also present a suite of benchmark tasks and their annotations, including fine-grained activity understanding, proficiency estimation, cross-view translation, and 3D hand/body pose. All resources will be open sourced to fuel new research in the community.
Aria Digital Twin: A New Benchmark Dataset for Egocentric 3D Machine Perception
Jun 13, 2023
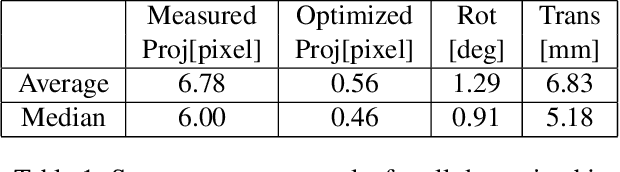
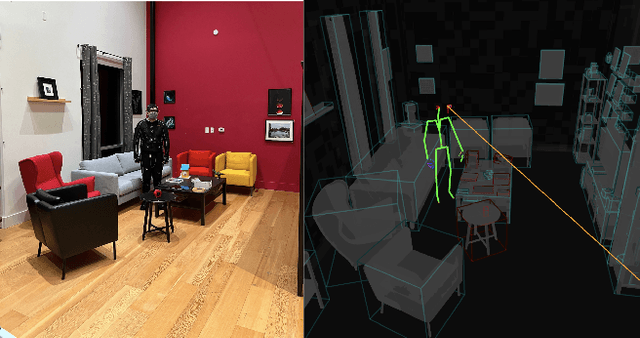
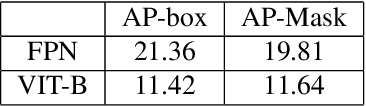
We introduce the Aria Digital Twin (ADT) - an egocentric dataset captured using Aria glasses with extensive object, environment, and human level ground truth. This ADT release contains 200 sequences of real-world activities conducted by Aria wearers in two real indoor scenes with 398 object instances (324 stationary and 74 dynamic). Each sequence consists of: a) raw data of two monochrome camera streams, one RGB camera stream, two IMU streams; b) complete sensor calibration; c) ground truth data including continuous 6-degree-of-freedom (6DoF) poses of the Aria devices, object 6DoF poses, 3D eye gaze vectors, 3D human poses, 2D image segmentations, image depth maps; and d) photo-realistic synthetic renderings. To the best of our knowledge, there is no existing egocentric dataset with a level of accuracy, photo-realism and comprehensiveness comparable to ADT. By contributing ADT to the research community, our mission is to set a new standard for evaluation in the egocentric machine perception domain, which includes very challenging research problems such as 3D object detection and tracking, scene reconstruction and understanding, sim-to-real learning, human pose prediction - while also inspiring new machine perception tasks for augmented reality (AR) applications. To kick start exploration of the ADT research use cases, we evaluated several existing state-of-the-art methods for object detection, segmentation and image translation tasks that demonstrate the usefulness of ADT as a benchmarking dataset.
The Replica Dataset: A Digital Replica of Indoor Spaces
Jun 13, 2019



We introduce Replica, a dataset of 18 highly photo-realistic 3D indoor scene reconstructions at room and building scale. Each scene consists of a dense mesh, high-resolution high-dynamic-range (HDR) textures, per-primitive semantic class and instance information, and planar mirror and glass reflectors. The goal of Replica is to enable machine learning (ML) research that relies on visually, geometrically, and semantically realistic generative models of the world - for instance, egocentric computer vision, semantic segmentation in 2D and 3D, geometric inference, and the development of embodied agents (virtual robots) performing navigation, instruction following, and question answering. Due to the high level of realism of the renderings from Replica, there is hope that ML systems trained on Replica may transfer directly to real world image and video data. Together with the data, we are releasing a minimal C++ SDK as a starting point for working with the Replica dataset. In addition, Replica is `Habitat-compatible', i.e. can be natively used with AI Habitat for training and testing embodied agents.
Design, Analysis and Application of A Volumetric Convolutional Neural Network
Feb 01, 2017

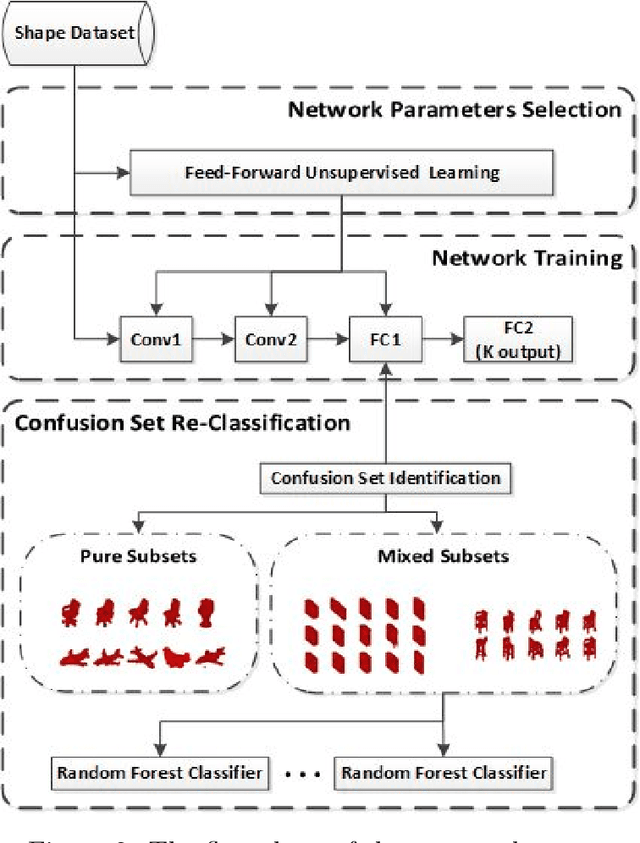
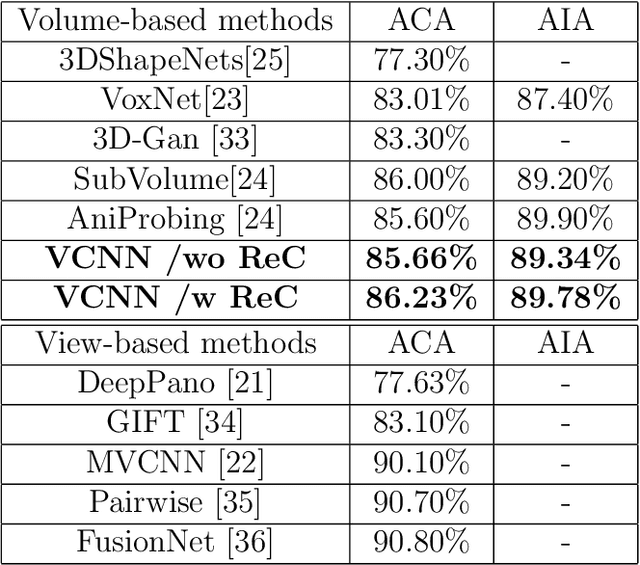
The design, analysis and application of a volumetric convolutional neural network (VCNN) are studied in this work. Although many CNNs have been proposed in the literature, their design is empirical. In the design of the VCNN, we propose a feed-forward K-means clustering algorithm to determine the filter number and size at each convolutional layer systematically. For the analysis of the VCNN, the cause of confusing classes in the output of the VCNN is explained by analyzing the relationship between the filter weights (also known as anchor vectors) from the last fully-connected layer to the output. Furthermore, a hierarchical clustering method followed by a random forest classification method is proposed to boost the classification performance among confusing classes. For the application of the VCNN, we examine the 3D shape classification problem and conduct experiments on a popular ModelNet40 dataset. The proposed VCNN offers the state-of-the-art performance among all volume-based CNN methods.
3D Shape Retrieval via Irrelevance Filtering and Similarity Ranking (IF/SR)
Jan 30, 2017
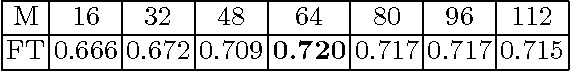


A novel solution for the content-based 3D shape retrieval problem using an unsupervised clustering approach, which does not need any label information of 3D shapes, is presented in this work. The proposed shape retrieval system consists of two modules in cascade: the irrelevance filtering (IF) module and the similarity ranking (SR) module. The IF module attempts to cluster gallery shapes that are similar to each other by examining global and local features simultaneously. However, shapes that are close in the local feature space can be distant in the global feature space, and vice versa. To resolve this issue, we propose a joint cost function that strikes a balance between two distances. Irrelevant samples that are close in the local feature space but distant in the global feature space can be removed in this stage. The remaining gallery samples are ranked in the SR module using the local feature. The superior performance of the proposed IF/SR method is demonstrated by extensive experiments conducted on the popular SHREC12 dataset.
A Two-Stage Shape Retrieval Method with Global and Local Features
May 03, 2016



A robust two-stage shape retrieval (TSR) method is proposed to address the 2D shape retrieval problem. Most state-of-the-art shape retrieval methods are based on local features matching and ranking. Their retrieval performance is not robust since they may retrieve globally dissimilar shapes in high ranks. To overcome this challenge, we decompose the decision process into two stages. In the first irrelevant cluster filtering (ICF) stage, we consider both global and local features and use them to predict the relevance of gallery shapes with respect to the query. Irrelevant shapes are removed from the candidate shape set. After that, a local-features-based matching and ranking (LMR) method follows in the second stage. We apply the proposed TSR system to MPEG-7, Kimia99 and Tari1000 three datasets and show that it outperforms all other existing methods. The robust retrieval performance of the TSR system is demonstrated.