 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Twin Assisted Beamforming Design for Integrated Sensing and Communication Systems
Dec 10, 2024



This paper explores a novel research direction where a digital twin is leveraged to assist the beamforming design for an integrated sensing and communication (ISAC) system. In this setup, a base station designs joint communication and sensing beamforming to serve the communication user and detect the sensing target concurrently. Utilizing the electromagnetic (EM) 3D model of the environment and ray tracing, the digital twin can provide various information, e.g., propagation path parameters and wireless channels, to aid communication and sensing systems. More specifically, our digital twin-based beamforming design first leverages the environment EM 3D model and ray tracing to (i) predict the directions of the line-of-sight (LoS) and non-line-of-sight (NLoS) sensing channel paths and (ii) identify the dominant one among these sensing channel paths. Then, to optimize the joint sensing and communication beam, we maximize the sensing signal-to-noise ratio (SNR) on the dominant sensing channel component while satisfying a minimum communication signal-to-interference-plus-noise ratio (SINR) requirement. Simulation results show that the proposed digital twin-assisted beamforming design achieves near-optimal target sensing SNR in both LoS and NLoS dominant areas, while ensuring the required SINR for the communication user. This highlights the potential of leveraging digital twins to assist ISAC systems.
Learnable Wireless Digital Twins: Reconstructing Electromagnetic Field with Neural Representations
Sep 04, 2024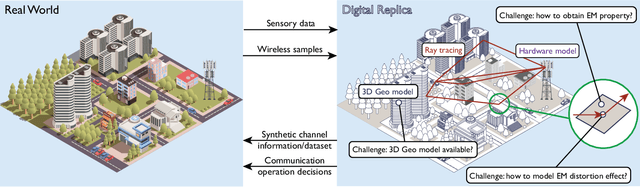
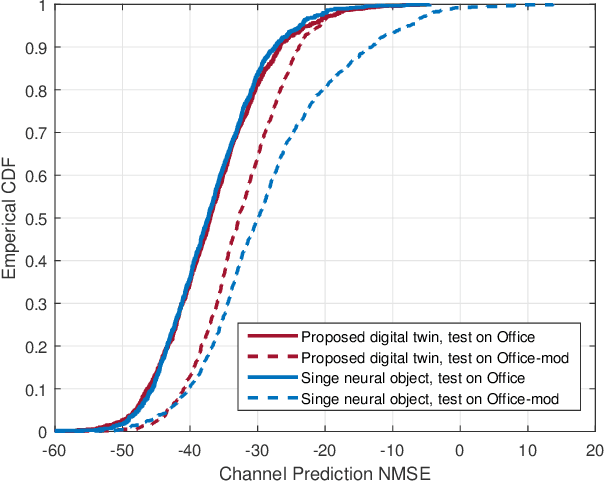
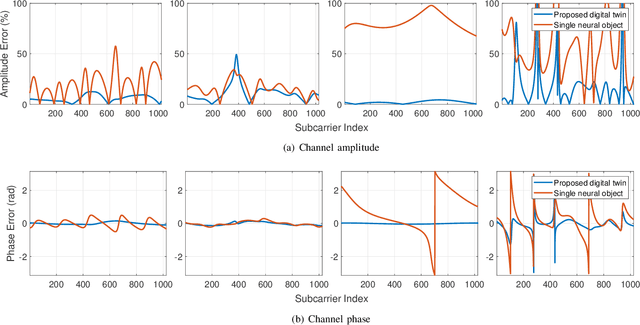
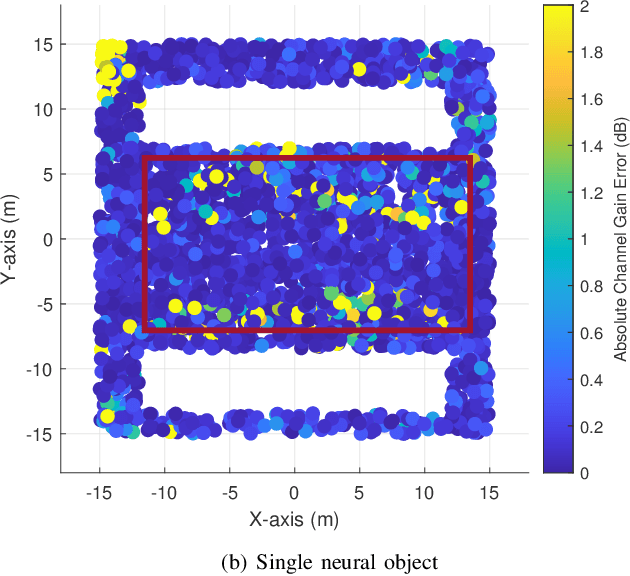
Fully harvesting the gain of multiple-input and multiple-output (MIMO) requires accurate channel information. However, conventional channel acquisition methods mainly rely on pilot training signals, resulting in significant training overheads (time, energy, spectrum). Digital twin-aided communications have been proposed in [1] to reduce or eliminate this overhead by approximating the real world with a digital replica. However, how to implement a digital twin-aided communication system brings new challenges. In particular, how to model the 3D environment and the associated EM properties, as well as how to update the environment dynamics in a coherent manner. To address these challenges, motivated by the latest advancements in computer vision, 3D reconstruction and neural radiance field, we propose an end-to-end deep learning framework for future generation wireless systems that can reconstruct the 3D EM field covered by a wireless access point, based on widely available crowd-sourced world-locked wireless samples between the access point and the devices. This visionary framework is grounded in classical EM theory and employs deep learning models to learn the EM properties and interaction behaviors of the objects in the environment. Simulation results demonstrate that the proposed learnable digital twin can implicitly learn the EM properties of the objects, accurately predict wireless channels, and generalize to changes in the environment, highlighting the prospect of this novel direction for future generation wireless platforms.
Digital Twin Aided Massive MIMO: CSI Compression and Feedback
Mar 01, 2024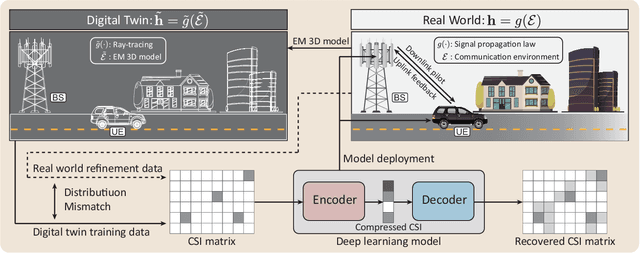
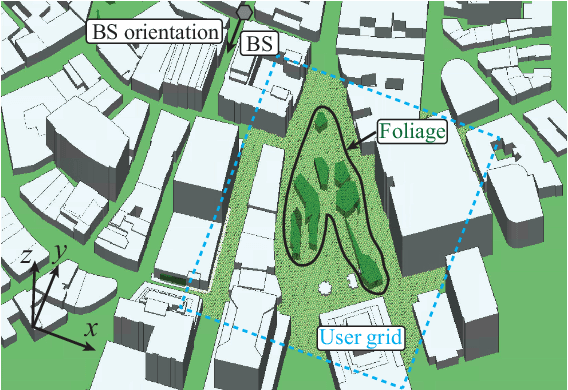
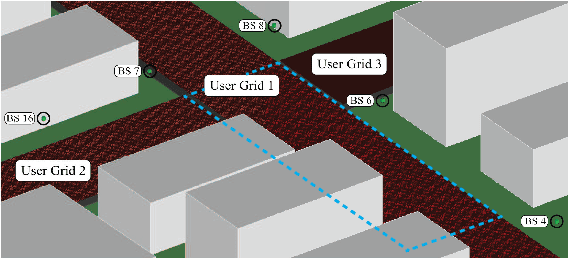
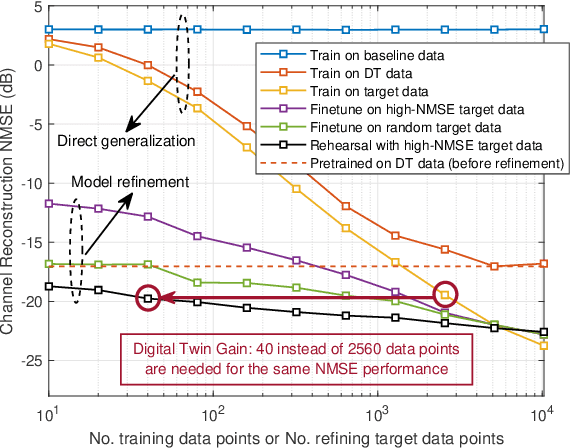
Deep learning (DL) approaches have demonstrated high performance in compressing and reconstructing the channel state information (CSI) and reducing the CSI feedback overhead in massive MIMO systems. One key challenge, however, with the DL approaches is the demand for extensive training data. Collecting this real-world CSI data incurs significant overhead that hinders the DL approaches from scaling to a large number of communication sites. To address this challenge, we propose a novel direction that utilizes site-specific \textit{digital twins} to aid the training of DL models. The proposed digital twin approach generates site-specific synthetic CSI data from the EM 3D model and ray tracing, which can then be used to train the DL model without real-world data collection. To further improve the performance, we adopt online data selection to refine the DL model training with a small real-world CSI dataset. Results show that a DL model trained solely on the digital twin data can achieve high performance when tested in a real-world deployment. Further, leveraging domain adaptation techniques, the proposed approach requires orders of magnitude less real-world data to approach the same performance of the model trained completely on a real-world CSI dataset.
Vision Guided MIMO Radar Beamforming for Enhanced Vital Signs Detection in Crowds
Jun 18, 2023



Radar as a remote sensing technology has been used to analyze human activity for decades. Despite all the great features such as motion sensitivity, privacy preservation, penetrability, and more, radar has limited spatial degrees of freedom compared to optical sensors and thus makes it challenging to sense crowded environments without prior information. In this paper, we develop a novel dual-sensing system, in which a vision sensor is leveraged to guide digital beamforming in a multiple-input multiple-output (MIMO) radar. Also, we develop a calibration algorithm to align the two types of sensors and show that the calibrated dual system achieves about two centimeters precision in three-dimensional space within a field of view of $75^\circ$ by $65^\circ$ and for a range of two meters. Finally, we show that the proposed approach is capable of detecting the vital signs simultaneously for a group of closely spaced subjects, sitting and standing, in a cluttered environment, which highlights a promising direction for vital signs detection in realistic environments.
Real-Time Digital Twins: Vision and Research Directions for 6G and Beyond
Jan 26, 2023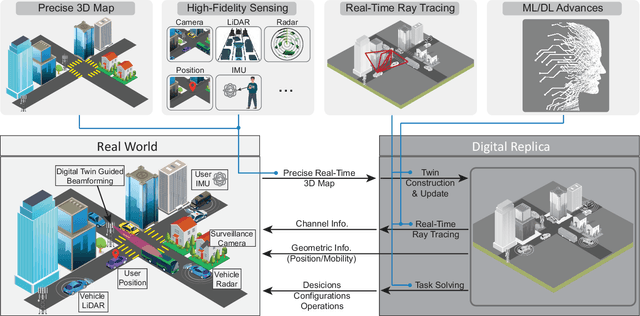
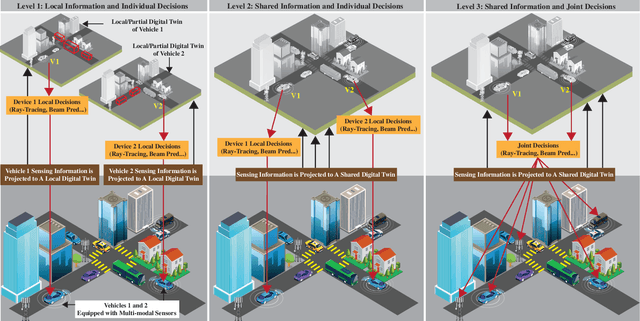
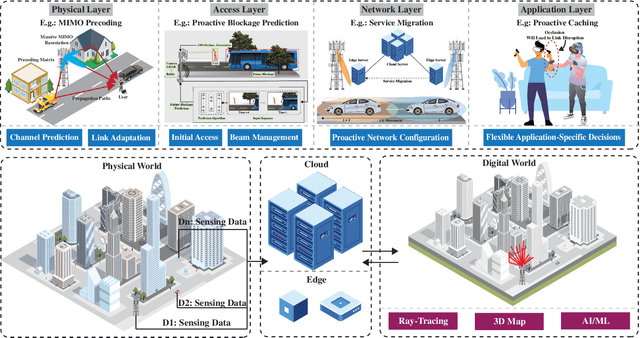
This article presents a vision where \textit{real-time} digital twins of the physical wireless environments are continuously updated using multi-modal sensing data from the distributed infrastructure and user devices, and are used to make communication and sensing decisions. This vision is mainly enabled by the advances in precise 3D maps, multi-modal sensing, ray-tracing computations, and machine/deep learning. This article details this vision, explains the different approaches for constructing and utilizing these real-time digital twins, discusses the applications and open problems, and presents a research platform that can be used to investigate various digital twin research directions.
Digital Twin Based Beam Prediction: Can we Train in the Digital World and Deploy in Reality?
Jan 18, 2023



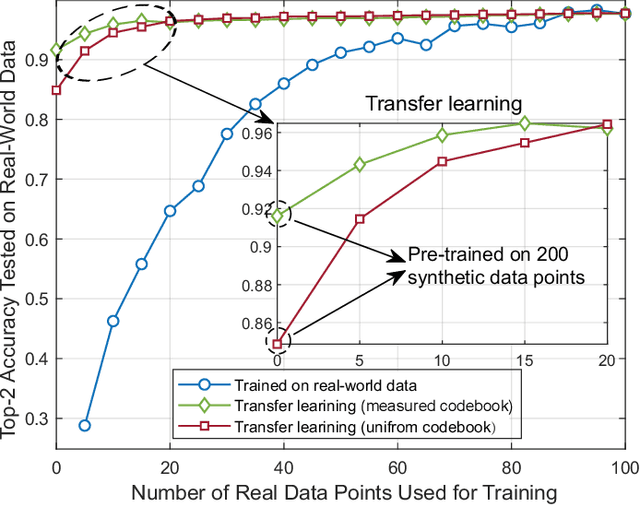
Realizing the potential gains of large-scale MIMO systems requires the accurate estimation of their channels or the fine adjustment of their narrow beams. This, however, is typically associated with high channel acquisition/beam sweeping overhead that scales with the number of antennas. Machine and deep learning represent promising approaches to overcome these challenges thanks to their powerful ability to learn from prior observations and side information. Training machine and deep learning models, however, requires large-scale datasets that are expensive to collect in deployed systems. To address this challenge, we propose a novel direction that utilizes digital replicas of the physical world to reduce or even eliminate the MIMO channel acquisition overhead. In the proposed digital twin aided communication, 3D models that approximate the real-world communication environment are constructed and accurate ray-tracing is utilized to simulate the site-specific channels. These channels can then be used to aid various communication tasks. Further, we propose to use machine learning to approximate the digital replicas and reduce the ray tracing computational cost. To evaluate the proposed digital twin based approach, we conduct a case study focusing on the position-aided beam prediction task. The results show that a learning model trained solely with the data generated by the digital replica can achieve relatively good performance on the real-world data. Moreover, a small number of real-world data points can quickly achieve near-optimal performance, overcoming the modeling mismatches between the physical and digital worlds and significantly reducing the data acquisition overhead.
Sensing Aided Reconfigurable Intelligent Surfaces for 3GPP 5G Transparent Operation
Nov 24, 2022

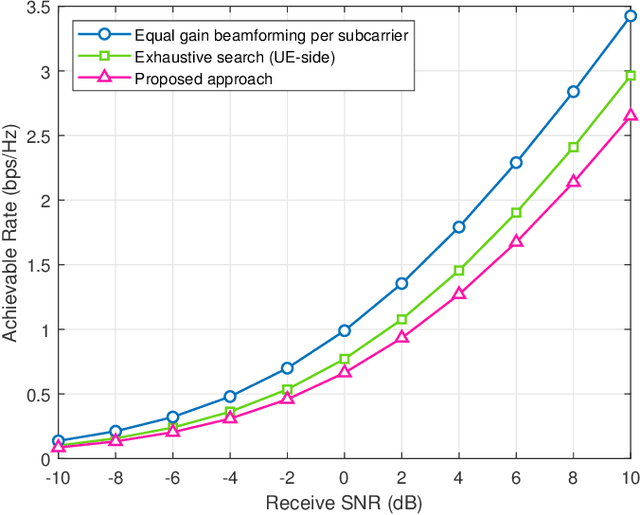

Can reconfigurable intelligent surfaces (RISs) operate in a standalone mode that is completely transparent to the 3GPP 5G initial access process? Realizing that may greatly simplify the deployment and operation of these surfaces and reduce the infrastructure control overhead. This paper investigates the feasibility of building standalone/transparent RIS systems and shows that one key challenge lies in determining the user equipment (UE)-side RIS beam reflection direction. To address this challenge, we propose to equip the RISs with multi-modal sensing capabilities (e.g., using wireless and visual sensors) that enable them to develop some perception of the surrounding environment and the mobile users. Based on that, we develop a machine learning framework that leverages the wireless and visual sensors at the RIS to select the optimal beams between the base station (BS) and users and enable 5G standalone/transparent RIS operation. Using a high-fidelity synthetic dataset with co-existing wireless and visual data, we extensively evaluate the performance of the proposed framework. Experimental results demonstrate that the proposed approach can accurately predict the BS and UE-side candidate beams, and that the standalone RIS beam selection solution is capable of realizing near-optimal achievable rates with significantly reduced beam training overhead.
Camera Aided Reconfigurable Intelligent Surfaces: Computer Vision Based Fast Beam Selection
Nov 14, 2022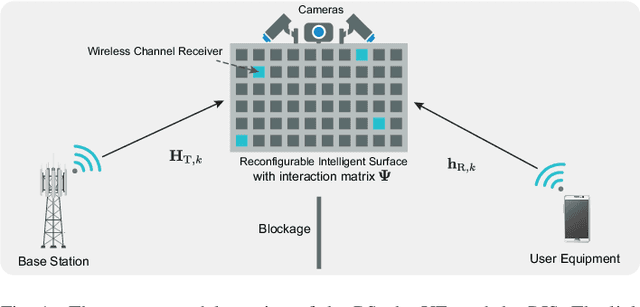
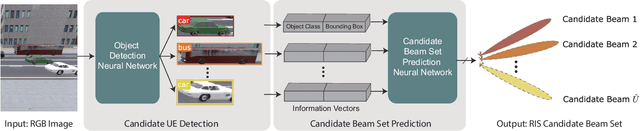
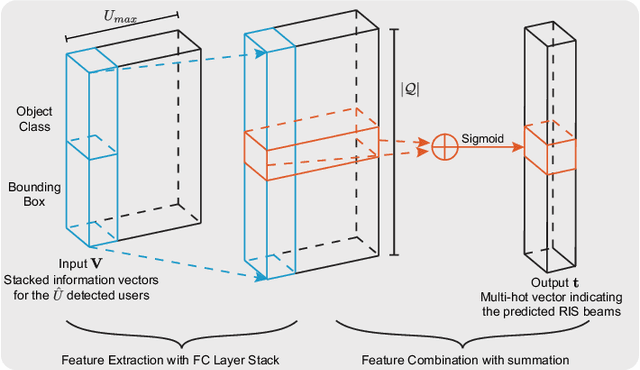
Reconfigurable intelligent surfaces (RISs) have attracted increasing interest due to their ability to improve the coverage, reliability, and energy efficiency of millimeter wave (mmWave) communication systems. However, designing the RIS beamforming typically requires large channel estimation or beam training overhead, which degrades the efficiency of these systems. In this paper, we propose to equip the RIS surfaces with visual sensors (cameras) that obtain sensing information about the surroundings and user/basestation locations, guide the RIS beam selection, and reduce the beam training overhead. We develop a machine learning (ML) framework that leverages this visual sensing information to efficiently select the optimal RIS reflection beams that reflect the signals between the basestation and mobile users. To evaluate the developed approach, we build a high-fidelity synthetic dataset that comprises co-existing wireless and visual data. Based on this dataset, the results show that the proposed vision-aided machine learning solution can accurately predict the RIS beams and achieve near-optimal achievable rate while significantly reducing the beam training overhead.
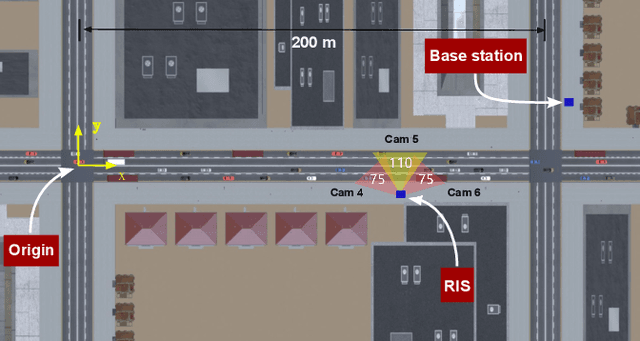
Sensing Aided OTFS Channel Estimation for Massive MIMO Systems
Sep 22, 2022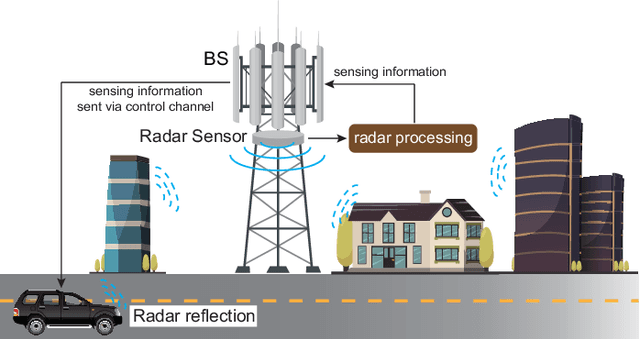
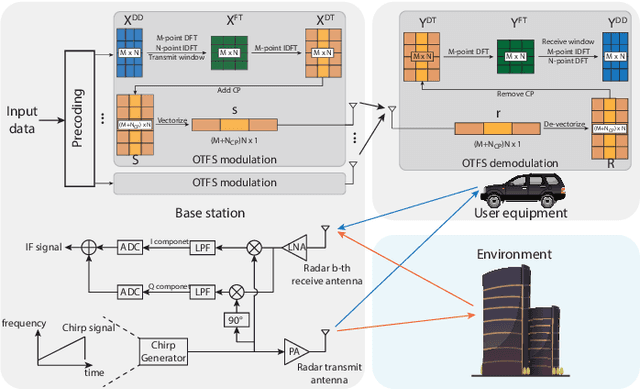
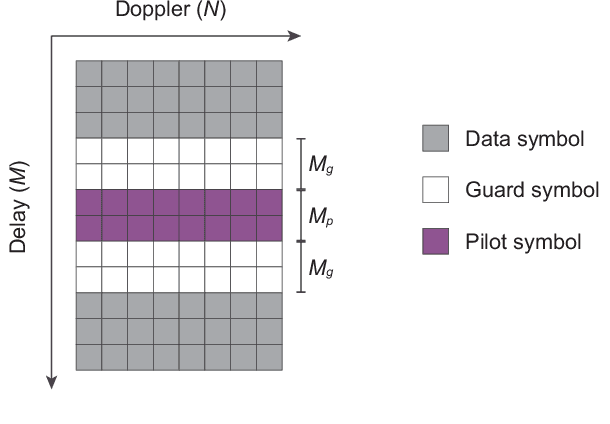
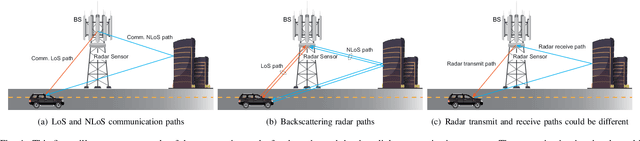
Orthogonal time frequency space (OTFS) modulation has the potential to enable robust communications in highly-mobile scenarios. Estimating the channels for OTFS systems, however, is associated with high pilot signaling overhead that scales with the maximum delay and Doppler spreads. This becomes particularly challenging for massive MIMO systems where the overhead also scales with the number of antennas. An important observation however is that the delay, Doppler, and angle of departure/arrival information are directly related to the distance, velocity, and direction information of the mobile user and the various scatterers in the environment. With this motivation, we propose to leverage radar sensing to obtain this information about the mobile users and scatterers in the environment and leverage it to aid the OTFS channel estimation in massive MIMO systems. As one approach to realize our vision, this paper formulates the OTFS channel estimation problem in massive MIMO systems as a sparse recovery problem and utilizes the radar sensing information to determine the support (locations of the non-zero delay-Doppler taps). The proposed radar sensing aided sparse recovery algorithm is evaluated based on an accurate 3D ray-tracing framework with co-existing radar and communication data. The results show that the developed sensing-aided solution consistently outperforms the standard sparse recovery algorithms (that do not leverage radar sensing data) and leads to a significant reduction in the pilot overhead, which highlights a promising direction for OTFS based massive MIMO systems.
LiDAR Aided Future Beam Prediction in Real-World Millimeter Wave V2I Communications
Mar 10, 2022

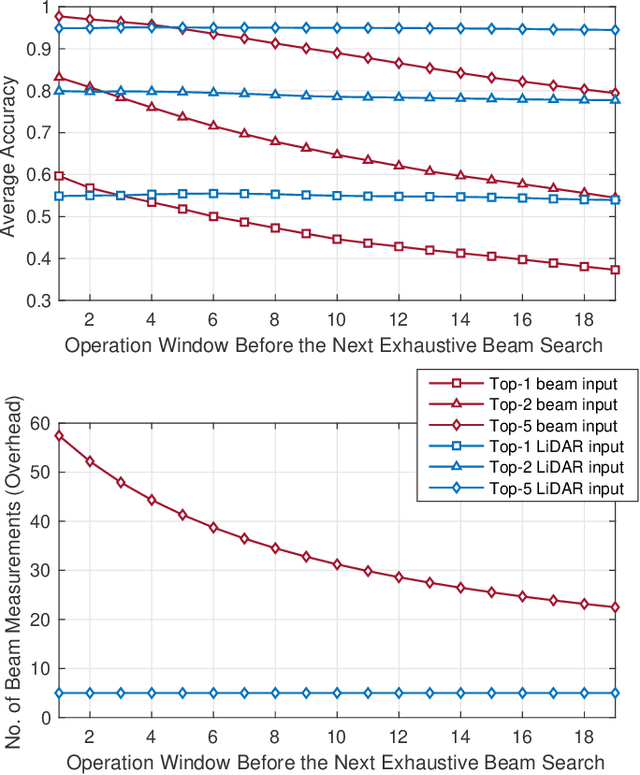

This paper presents the first large-scale real-world evaluation for using LiDAR data to guide the mmWave beam prediction task. A machine learning (ML) model that leverages the LiDAR sensory data to predict the current and future beams was developed. Based on the large-scale real-world dataset, DeepSense 6G, this model was evaluated in a vehicle-to-infrastructure communication scenario with highly-mobile vehicles. The experimental results show that the developed LiDAR-aided beam prediction and tracking model can predict the optimal beam in $95\%$ of the cases and with more than $90\%$ reduction in the beam training overhead. The LiDAR-aided beam tracking achieves comparable accuracy performance to a baseline solution that has perfect knowledge of the previous optimal beams, without requiring any knowledge about the previous optimal beam information and without any need for beam calibration. This highlights a promising solution for the critical beam alignment challenges in mmWave and terahertz communication systems.