 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearnable Wireless Digital Twins: Reconstructing Electromagnetic Field with Neural Representations
Sep 04, 2024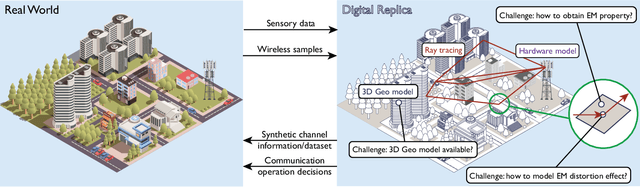
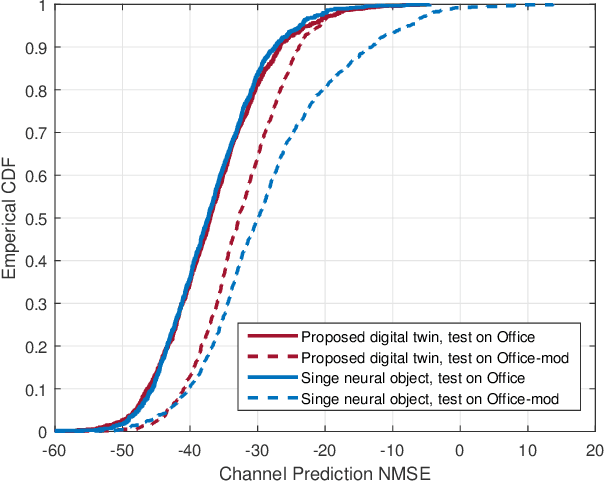
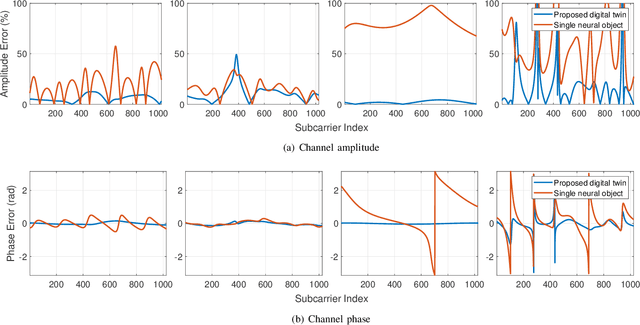
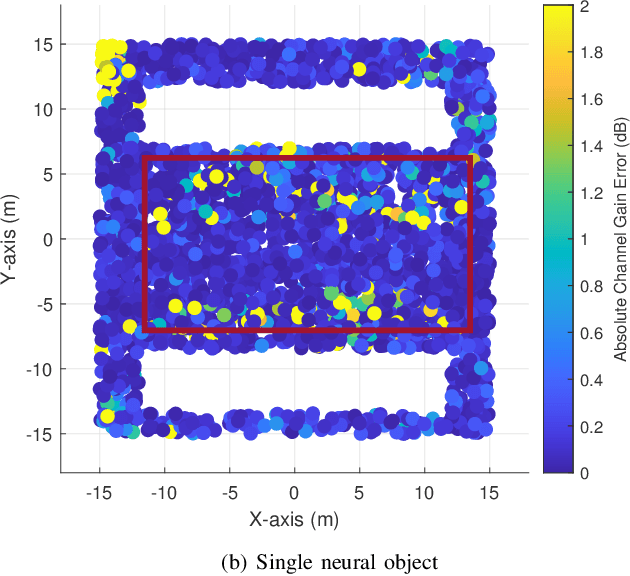
Fully harvesting the gain of multiple-input and multiple-output (MIMO) requires accurate channel information. However, conventional channel acquisition methods mainly rely on pilot training signals, resulting in significant training overheads (time, energy, spectrum). Digital twin-aided communications have been proposed in [1] to reduce or eliminate this overhead by approximating the real world with a digital replica. However, how to implement a digital twin-aided communication system brings new challenges. In particular, how to model the 3D environment and the associated EM properties, as well as how to update the environment dynamics in a coherent manner. To address these challenges, motivated by the latest advancements in computer vision, 3D reconstruction and neural radiance field, we propose an end-to-end deep learning framework for future generation wireless systems that can reconstruct the 3D EM field covered by a wireless access point, based on widely available crowd-sourced world-locked wireless samples between the access point and the devices. This visionary framework is grounded in classical EM theory and employs deep learning models to learn the EM properties and interaction behaviors of the objects in the environment. Simulation results demonstrate that the proposed learnable digital twin can implicitly learn the EM properties of the objects, accurately predict wireless channels, and generalize to changes in the environment, highlighting the prospect of this novel direction for future generation wireless platforms.
Automatic Annotation of Grammaticality in Child-Caregiver Conversations
Mar 21, 2024

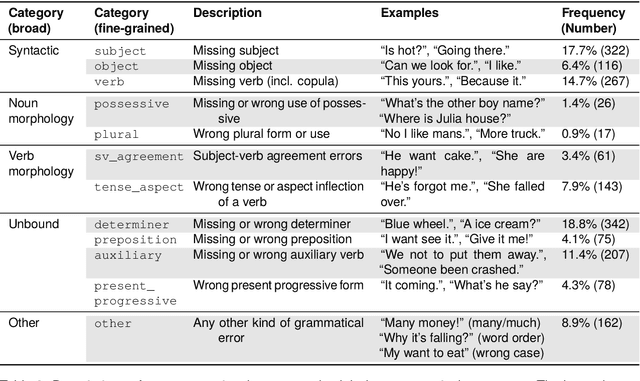

The acquisition of grammar has been a central question to adjudicate between theories of language acquisition. In order to conduct faster, more reproducible, and larger-scale corpus studies on grammaticality in child-caregiver conversations, tools for automatic annotation can offer an effective alternative to tedious manual annotation. We propose a coding scheme for context-dependent grammaticality in child-caregiver conversations and annotate more than 4,000 utterances from a large corpus of transcribed conversations. Based on these annotations, we train and evaluate a range of NLP models. Our results show that fine-tuned Transformer-based models perform best, achieving human inter-annotation agreement levels.As a first application and sanity check of this tool, we use the trained models to annotate a corpus almost two orders of magnitude larger than the manually annotated data and verify that children's grammaticality shows a steady increase with age.This work contributes to the growing literature on applying state-of-the-art NLP methods to help study child language acquisition at scale.