 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSensing-Aided 6G Drone Communications: Real-World Datasets and Demonstration
Dec 06, 2024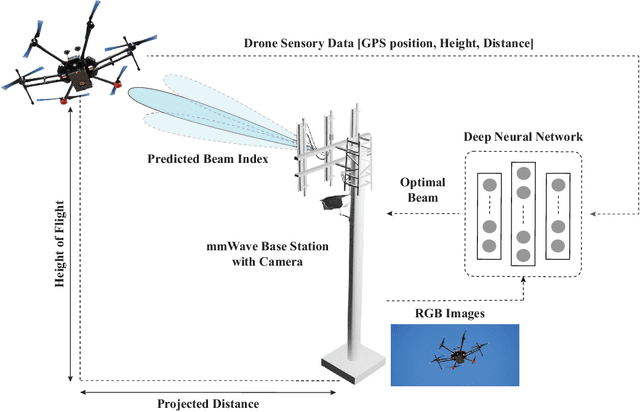


In the advent of next-generation wireless communication, millimeter-wave (mmWave) and terahertz (THz) technologies are pivotal for their high data rate capabilities. However, their reliance on large antenna arrays and narrow directive beams for ensuring adequate receive signal power introduces significant beam training overheads. This becomes particularly challenging in supporting highly-mobile applications such as drone communication, where the dynamic nature of drones demands frequent beam alignment to maintain connectivity. Addressing this critical bottleneck, our paper introduces a novel machine learning-based framework that leverages multi-modal sensory data, including visual and positional information, to expedite and refine mmWave/THz beam prediction. Unlike conventional approaches that solely depend on exhaustive beam training methods, our solution incorporates additional layers of contextual data to accurately predict beam directions, significantly mitigating the training overhead. Additionally, our framework is capable of predicting future beam alignments ahead of time. This feature enhances the system's responsiveness and reliability by addressing the challenges posed by the drones' mobility and the computational delays encountered in real-time processing. This capability for advanced beam tracking asserts a critical advancement in maintaining seamless connectivity for highly-mobile drones. We validate our approach through comprehensive evaluations on a unique, real-world mmWave drone communication dataset, which integrates concurrent camera visuals, practical GPS coordinates, and mmWave beam training data...
Large Wireless Model (LWM): A Foundation Model for Wireless Channels
Nov 13, 2024



This paper presents the Large Wireless Model (LWM) -- the world's first foundation model for wireless channels. Designed as a task-agnostic model, LWM generates universal, rich, contextualized channel embeddings (features) that potentially enhance performance across a wide range of downstream tasks in wireless communication and sensing systems. Towards this objective, LWM, which has a transformer-based architecture, was pre-trained in a self-supervised manner on large-scale wireless channel datasets. Our results show consistent improvements in classification and regression tasks when using the LWM embeddings compared to raw channel representations, especially in scenarios with high-complexity machine learning tasks and limited training datasets. This LWM's ability to learn from large-scale wireless data opens a promising direction for intelligent systems that can efficiently adapt to diverse tasks with limited data, paving the way for addressing key challenges in wireless communication and sensing systems.
Pixel-Level GPS Localization and Denoising using Computer Vision and 6G Communication Beams
Jul 28, 2024



Accurate localization is crucial for various applications, including autonomous vehicles and next-generation wireless networks. However, the reliability and precision of Global Navigation Satellite Systems (GNSS), such as the Global Positioning System (GPS), are compromised by multi-path errors and non-line-of-sight scenarios. This paper presents a novel approach to enhance GPS accuracy by combining visual data from RGB cameras with wireless signals captured at millimeter-wave (mmWave) and sub-terahertz (sub-THz) basestations. We propose a sensing-aided framework for (i) site-specific GPS data characterization and (ii) GPS position de-noising that utilizes multi-modal visual and wireless information. Our approach is validated in a realistic Vehicle-to-Infrastructure (V2I) scenario using a comprehensive real-world dataset, demonstrating a substantial reduction in localization error to sub-meter levels. This method represents a significant advancement in achieving precise localization, particularly beneficial for high-mobility applications in 5G and beyond networks.
DeepSense-V2V: A Vehicle-to-Vehicle Multi-Modal Sensing, Localization, and Communications Dataset
Jun 25, 2024High data rate and low-latency vehicle-to-vehicle (V2V) communication are essential for future intelligent transport systems to enable coordination, enhance safety, and support distributed computing and intelligence requirements. Developing effective communication strategies, however, demands realistic test scenarios and datasets. This is important at the high-frequency bands where more spectrum is available, yet harvesting this bandwidth is challenged by the need for direction transmission and the sensitivity of signal propagation to blockages. This work presents the first large-scale multi-modal dataset for studying mmWave vehicle-to-vehicle communications. It presents a two-vehicle testbed that comprises data from a 360-degree camera, four radars, four 60 GHz phased arrays, a 3D lidar, and two precise GPSs. The dataset contains vehicles driving during the day and night for 120 km in intercity and rural settings, with speeds up to 100 km per hour. More than one million objects were detected across all images, from trucks to bicycles. This work further includes detailed dataset statistics that prove the coverage of various situations and highlights how this dataset can enable novel machine-learning applications.
Environment Semantic Communication: Enabling Distributed Sensing Aided Networks
Feb 22, 2024



Millimeter-wave (mmWave) and terahertz (THz) communication systems require large antenna arrays and use narrow directive beams to ensure sufficient receive signal power. However, selecting the optimal beams for these large antenna arrays incurs a significant beam training overhead, making it challenging to support applications involving high mobility. In recent years, machine learning (ML) solutions have shown promising results in reducing the beam training overhead by utilizing various sensing modalities such as GPS position and RGB images. However, the existing approaches are mainly limited to scenarios with only a single object of interest present in the wireless environment and focus only on co-located sensing, where all the sensors are installed at the communication terminal. This brings key challenges such as the limited sensing coverage compared to the coverage of the communication system and the difficulty in handling non-line-of-sight scenarios. To overcome these limitations, our paper proposes the deployment of multiple distributed sensing nodes, each equipped with an RGB camera. These nodes focus on extracting environmental semantics from the captured RGB images. The semantic data, rather than the raw images, are then transmitted to the basestation. This strategy significantly alleviates the overhead associated with the data storage and transmission of the raw images. Furthermore, semantic communication enhances the system's adaptability and responsiveness to dynamic environments, allowing for prioritization and transmission of contextually relevant information. Experimental results on the DeepSense 6G dataset demonstrate the effectiveness of the proposed solution in reducing the sensing data transmission overhead while accurately predicting the optimal beams in realistic communication environments.
Vehicle Cameras Guide mmWave Beams: Approach and Real-World V2V Demonstration
Aug 20, 2023



Accurately aligning millimeter-wave (mmWave) and terahertz (THz) narrow beams is essential to satisfy reliability and high data rates of 5G and beyond wireless communication systems. However, achieving this objective is difficult, especially in vehicle-to-vehicle (V2V) communication scenarios, where both transmitter and receiver are constantly mobile. Recently, additional sensing modalities, such as visual sensors, have attracted significant interest due to their capability to provide accurate information about the wireless environment. To that end, in this paper, we develop a deep learning solution for V2V scenarios to predict future beams using images from a 360 camera attached to the vehicle. The developed solution is evaluated on a real-world multi-modal mmWave V2V communication dataset comprising co-existing 360 camera and mmWave beam training data. The proposed vision-aided solution achieves $\approx 85\%$ top-5 beam prediction accuracy while significantly reducing the beam training overhead. This highlights the potential of utilizing vision for enabling highly-mobile V2V communications.
Camera Based mmWave Beam Prediction: Towards Multi-Candidate Real-World Scenarios
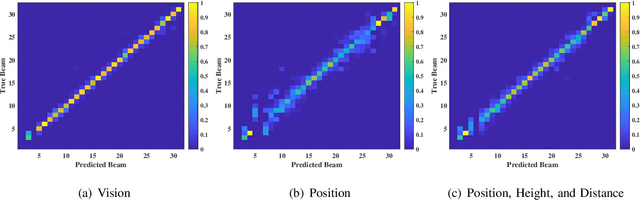
Aug 14, 2023Leveraging sensory information to aid the millimeter-wave (mmWave) and sub-terahertz (sub-THz) beam selection process is attracting increasing interest. This sensory data, captured for example by cameras at the basestations, has the potential of significantly reducing the beam sweeping overhead and enabling highly-mobile applications. The solutions developed so far, however, have mainly considered single-candidate scenarios, i.e., scenarios with a single candidate user in the visual scene, and were evaluated using synthetic datasets. To address these limitations, this paper extensively investigates the sensing-aided beam prediction problem in a real-world multi-object vehicle-to-infrastructure (V2I) scenario and presents a comprehensive machine learning-based framework. In particular, this paper proposes to utilize visual and positional data to predict the optimal beam indices as an alternative to the conventional beam sweeping approaches. For this, a novel user (transmitter) identification solution has been developed, a key step in realizing sensing-aided multi-candidate and multi-user beam prediction solutions. The proposed solutions are evaluated on the large-scale real-world DeepSense $6$G dataset. Experimental results in realistic V2I communication scenarios indicate that the proposed solutions achieve close to $100\%$ top-5 beam prediction accuracy for the scenarios with single-user and close to $95\%$ top-5 beam prediction accuracy for multi-candidate scenarios. Furthermore, the proposed approach can identify the probable transmitting candidate with more than $93\%$ accuracy across the different scenarios. This highlights a promising approach for nearly eliminating the beam training overhead in mmWave/THz communication systems.
Environment Semantic Aided Communication: A Real World Demonstration for Beam Prediction
Feb 13, 2023



Millimeter-wave (mmWave) and terahertz (THz) communication systems adopt large antenna arrays to ensure adequate receive signal power. However, adjusting the narrow beams of these antenna arrays typically incurs high beam training overhead that scales with the number of antennas. Recently proposed vision-aided beam prediction solutions, which utilize \textit{raw RGB images} captured at the basestation to predict the optimal beams, have shown initial promising results. However, they still have a considerable computational complexity, limiting their adoption in the real world. To address these challenges, this paper focuses on developing and comparing various approaches that extract lightweight semantic information from the visual data. The results show that the proposed solutions can significantly decrease the computational requirements while achieving similar beam prediction accuracy compared to the previously proposed vision-aided solutions.
Real-Time Digital Twins: Vision and Research Directions for 6G and Beyond
Jan 26, 2023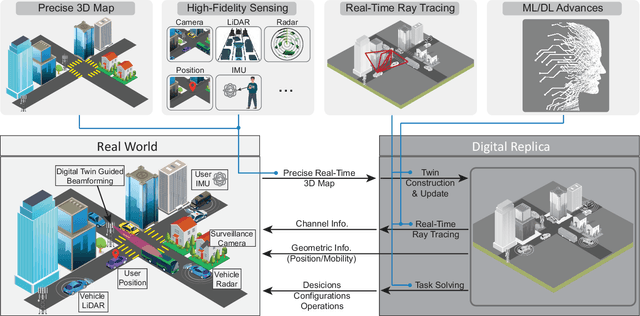
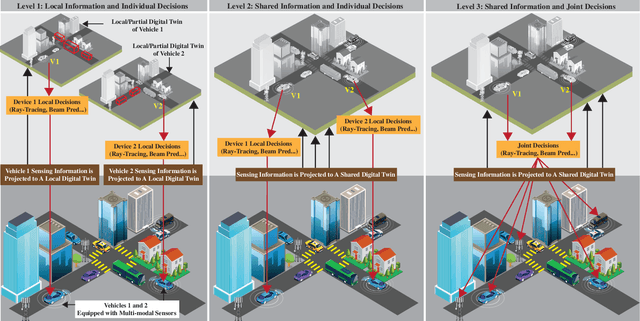
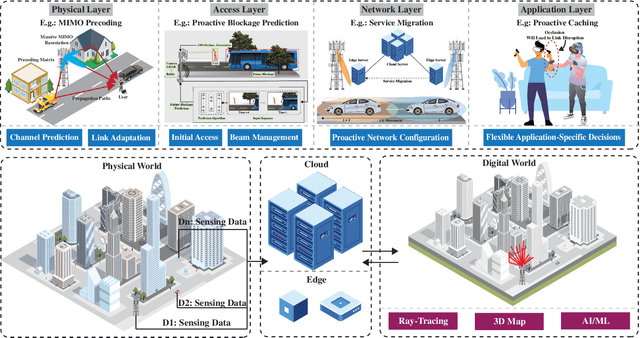
This article presents a vision where \textit{real-time} digital twins of the physical wireless environments are continuously updated using multi-modal sensing data from the distributed infrastructure and user devices, and are used to make communication and sensing decisions. This vision is mainly enabled by the advances in precise 3D maps, multi-modal sensing, ray-tracing computations, and machine/deep learning. This article details this vision, explains the different approaches for constructing and utilizing these real-time digital twins, discusses the applications and open problems, and presents a research platform that can be used to investigate various digital twin research directions.
DeepSense 6G: A Large-Scale Real-World Multi-Modal Sensing and Communication Dataset
Nov 17, 2022



This article presents the DeepSense 6G dataset, which is a large-scale dataset based on real-world measurements of co-existing multi-modal sensing and communication data. The DeepSense 6G dataset is built to advance deep learning research in a wide range of applications in the intersection of multi-modal sensing, communication, and positioning. This article provides a detailed overview of the DeepSense dataset structure, adopted testbeds, data collection and processing methodology, deployment scenarios, and example applications, with the objective of facilitating the adoption and reproducibility of multi-modal sensing and communication datasets.