 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment Semantic Communication: Enabling Distributed Sensing Aided Networks
Feb 22, 2024



Millimeter-wave (mmWave) and terahertz (THz) communication systems require large antenna arrays and use narrow directive beams to ensure sufficient receive signal power. However, selecting the optimal beams for these large antenna arrays incurs a significant beam training overhead, making it challenging to support applications involving high mobility. In recent years, machine learning (ML) solutions have shown promising results in reducing the beam training overhead by utilizing various sensing modalities such as GPS position and RGB images. However, the existing approaches are mainly limited to scenarios with only a single object of interest present in the wireless environment and focus only on co-located sensing, where all the sensors are installed at the communication terminal. This brings key challenges such as the limited sensing coverage compared to the coverage of the communication system and the difficulty in handling non-line-of-sight scenarios. To overcome these limitations, our paper proposes the deployment of multiple distributed sensing nodes, each equipped with an RGB camera. These nodes focus on extracting environmental semantics from the captured RGB images. The semantic data, rather than the raw images, are then transmitted to the basestation. This strategy significantly alleviates the overhead associated with the data storage and transmission of the raw images. Furthermore, semantic communication enhances the system's adaptability and responsiveness to dynamic environments, allowing for prioritization and transmission of contextually relevant information. Experimental results on the DeepSense 6G dataset demonstrate the effectiveness of the proposed solution in reducing the sensing data transmission overhead while accurately predicting the optimal beams in realistic communication environments.
Environment Semantic Aided Communication: A Real World Demonstration for Beam Prediction
Feb 13, 2023



Millimeter-wave (mmWave) and terahertz (THz) communication systems adopt large antenna arrays to ensure adequate receive signal power. However, adjusting the narrow beams of these antenna arrays typically incurs high beam training overhead that scales with the number of antennas. Recently proposed vision-aided beam prediction solutions, which utilize \textit{raw RGB images} captured at the basestation to predict the optimal beams, have shown initial promising results. However, they still have a considerable computational complexity, limiting their adoption in the real world. To address these challenges, this paper focuses on developing and comparing various approaches that extract lightweight semantic information from the visual data. The results show that the proposed solutions can significantly decrease the computational requirements while achieving similar beam prediction accuracy compared to the previously proposed vision-aided solutions.
A Deep-Unfolded Spatiotemporal RPCA Network For L+S Decomposition
Nov 06, 2022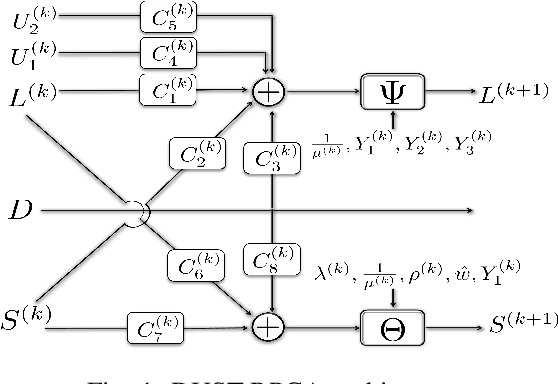

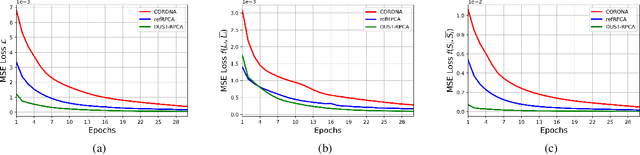
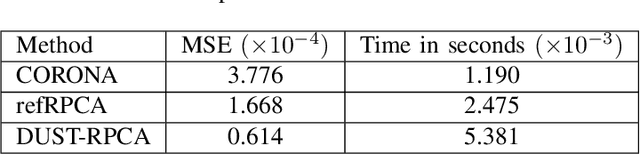
Low-rank and sparse decomposition based methods find their use in many applications involving background modeling such as clutter suppression and object tracking. While Robust Principal Component Analysis (RPCA) has achieved great success in performing this task, it can take hundreds of iterations to converge and its performance decreases in the presence of different phenomena such as occlusion, jitter and fast motion. The recently proposed deep unfolded networks, on the other hand, have demonstrated better accuracy and improved convergence over both their iterative equivalents as well as over other neural network architectures. In this work, we propose a novel deep unfolded spatiotemporal RPCA (DUST-RPCA) network, which explicitly takes advantage of the spatial and temporal continuity in the low-rank component. Our experimental results on the moving MNIST dataset indicate that DUST-RPCA gives better accuracy when compared with the existing state of the art deep unfolded RPCA networks.