 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistribution-Guided and Constrained Quantum Machine Unlearning
Jan 07, 2026Machine unlearning aims to remove the influence of specific training data from a learned model without full retraining. While recent work has begun to explore unlearning in quantum machine learning, existing approaches largely rely on fixed, uniform target distributions and do not explicitly control the trade-off between forgetting and retained model behaviour. In this work, we propose a distribution-guided framework for class-level quantum machine unlearning that treats unlearning as a constrained optimization problem. Our method introduces a tunable target distribution derived from model similarity statistics, decoupling the suppression of forgotten-class confidence from assumptions about redistribution among retained classes. We further incorporate an anchor-based preservation constraint that explicitly maintains predictive behaviour on selected retained data, yielding a controlled optimization trajectory that limits deviation from the original model. We evaluate the approach on variational quantum classifiers trained on the Iris and Covertype datasets. Results demonstrate sharp suppression of forgotten-class confidence, minimal degradation of retained-class performance, and closer alignment with the gold retrained model baselines compared to uniform-target unlearning. These findings highlight the importance of target design and constraint-based formulations for reliable and interpretable quantum machine unlearning.
Robust and Noise-resilient Long-Term Prediction of Spatiotemporal Data Using Variational Mode Graph Neural Networks with 3D Attention
Apr 09, 2025This paper focuses on improving the robustness of spatiotemporal long-term prediction using a variational mode graph convolutional network (VMGCN) by introducing 3D channel attention. The deep learning network for this task relies on historical data inputs, yet real-time data can be corrupted by sensor noise, altering its distribution. We model this noise as independent and identically distributed (i.i.d.) Gaussian noise and incorporate it into the LargeST traffic volume dataset, resulting in data with both inherent and additive noise components. Our approach involves decomposing the corrupted signal into modes using variational mode decomposition, followed by feeding the data into a learning pipeline for prediction. We integrate a 3D attention mechanism encompassing spatial, temporal, and channel attention. The spatial and temporal attention modules learn their respective correlations, while the channel attention mechanism is used to suppress noise and highlight the significant modes in the spatiotemporal signals. Additionally, a learnable soft thresholding method is implemented to exclude unimportant modes from the feature vector, and a feature reduction method based on the signal-to-noise ratio (SNR) is applied. We compare the performance of our approach against baseline models, demonstrating that our method achieves superior long-term prediction accuracy, robustness to noise, and improved performance with mode truncation compared to the baseline models. The code of the paper is available at https://github.com/OsamaAhmad369/VMGCN.
Spatiotemporal Air Quality Mapping in Urban Areas Using Sparse Sensor Data, Satellite Imagery, Meteorological Factors, and Spatial Features
Jan 20, 2025Monitoring air pollution is crucial for protecting human health from exposure to harmful substances. Traditional methods of air quality monitoring, such as ground-based sensors and satellite-based remote sensing, face limitations due to high deployment costs, sparse sensor coverage, and environmental interferences. To address these challenges, this paper proposes a framework for high-resolution spatiotemporal Air Quality Index (AQI) mapping using sparse sensor data, satellite imagery, and various spatiotemporal factors. By leveraging Graph Neural Networks (GNNs), we estimate AQI values at unmonitored locations based on both spatial and temporal dependencies. The framework incorporates a wide range of environmental features, including meteorological data, road networks, points of interest (PoIs), population density, and urban green spaces, which enhance prediction accuracy. We illustrate the use of our approach through a case study in Lahore, Pakistan, where multi-resolution data is used to generate the air quality index map at a fine spatiotemporal scale.
Variational Mode-Driven Graph Convolutional Network for Spatiotemporal Traffic Forecasting
Aug 29, 2024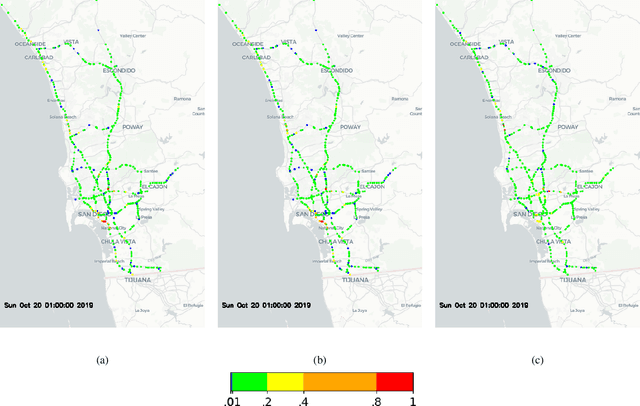



This paper focuses on spatio-temporal (ST) traffic prediction traffic using graph neural networks. Given that ST data consists of non-stationary and complex time events, interpreting and predicting such trends is comparatively complicated. Representation of ST data in modes helps us infer behavior and assess the impact of noise on prediction applications. We propose a framework that decomposes ST data into modes using the variational mode decomposition (VMD) method, which is then fed into the neural network for forecasting future states. This hybrid approach is known as a variational mode graph convolutional network (VMGCN). Instead of exhaustively searching for the number of modes, they are determined using the reconstruction loss from the real-time application data. We also study the significance of each mode and the impact of bandwidth constraints on different horizon predictions in traffic flow data. We evaluate the performance of our proposed network on the LargeST dataset for both short and long-term predictions. Our framework yields better results compared to state-of-the-art methods.
TFNet: Tuning Fork Network with Neighborhood Pixel Aggregation for Improved Building Footprint Extraction
Nov 05, 2023



This paper considers the problem of extracting building footprints from satellite imagery -- a task that is critical for many urban planning and decision-making applications. While recent advancements in deep learning have made great strides in automated detection of building footprints, state-of-the-art methods available in existing literature often generate erroneous results for areas with densely connected buildings. Moreover, these methods do not incorporate the context of neighborhood images during training thus generally resulting in poor performance at image boundaries. In light of these gaps, we propose a novel Tuning Fork Network (TFNet) design for deep semantic segmentation that not only performs well for widely-spaced building but also has good performance for buildings that are closely packed together. The novelty of TFNet architecture lies in a a single encoder followed by two parallel decoders to separately reconstruct the building footprint and the building edge. In addition, the TFNet design is coupled with a novel methodology of incorporating neighborhood information at the tile boundaries during the training process. This methodology further improves performance, especially at the tile boundaries. For performance comparisons, we utilize the SpaceNet2 and WHU datasets, as well as a dataset from an area in Lahore, Pakistan that captures closely connected buildings. For all three datasets, the proposed methodology is found to significantly outperform benchmark methods.
Logistics Hub Location Optimization: A K-Means and P-Median Model Hybrid Approach Using Road Network Distances
Aug 18, 2023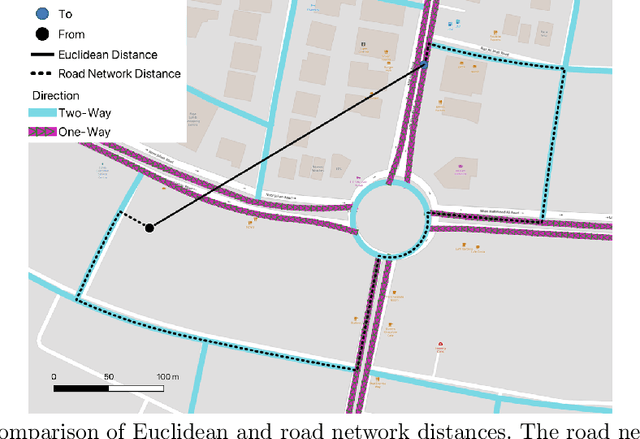
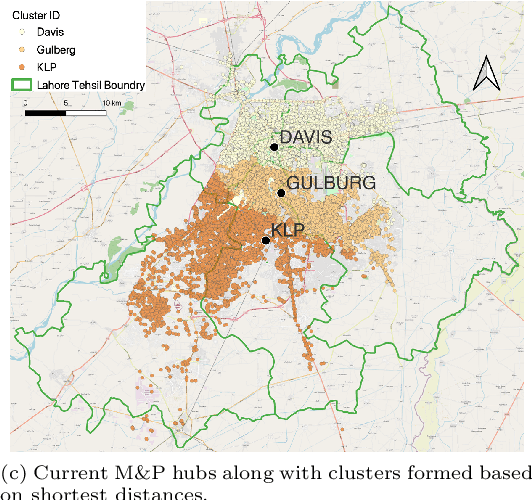
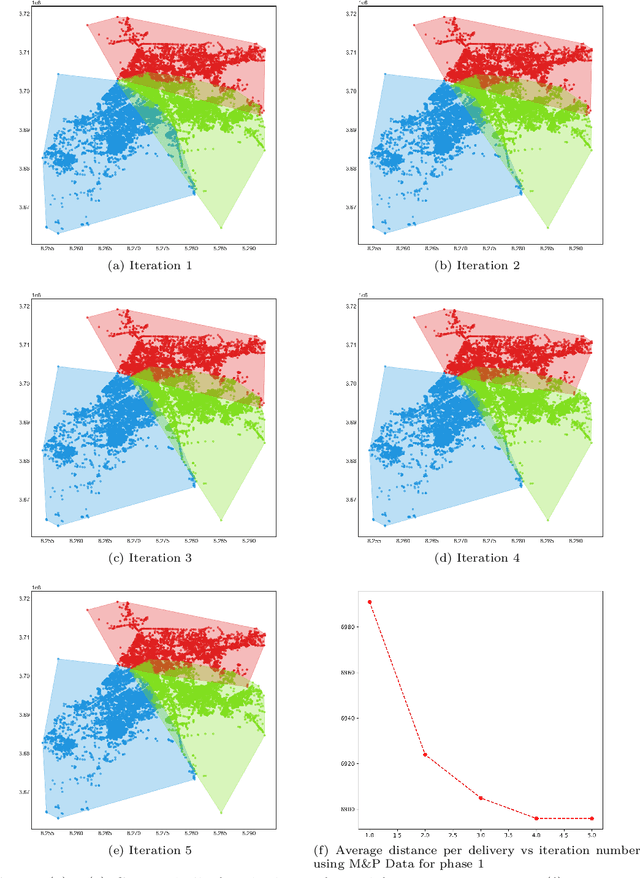
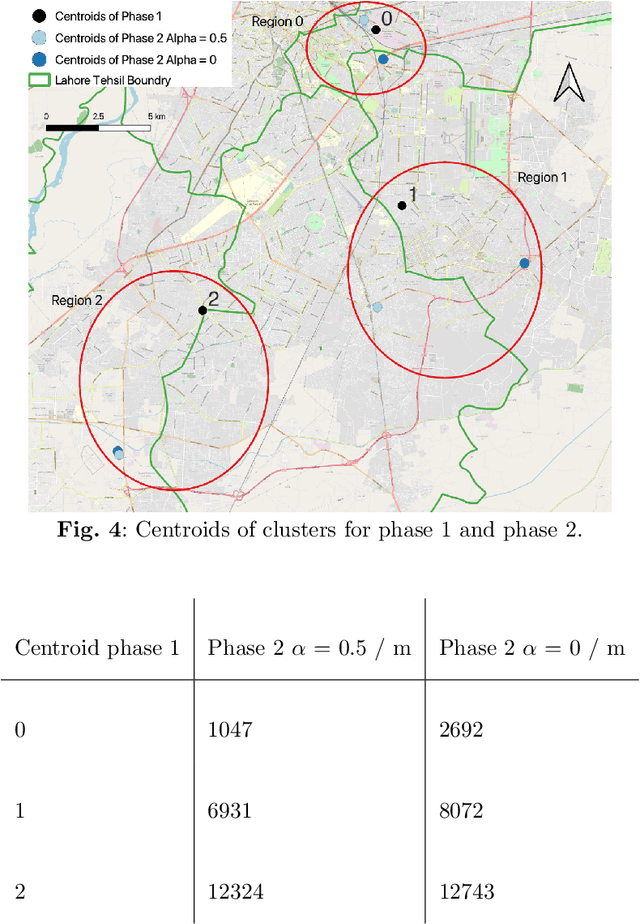
Logistic hubs play a pivotal role in the last-mile delivery distance; even a slight increment in distance negatively impacts the business of the e-commerce industry while also increasing its carbon footprint. The growth of this industry, particularly after Covid-19, has further intensified the need for optimized allocation of resources in an urban environment. In this study, we use a hybrid approach to optimize the placement of logistic hubs. The approach sequentially employs different techniques. Initially, delivery points are clustered using K-Means in relation to their spatial locations. The clustering method utilizes road network distances as opposed to Euclidean distances. Non-road network-based approaches have been avoided since they lead to erroneous and misleading results. Finally, hubs are located using the P-Median method. The P-Median method also incorporates the number of deliveries and population as weights. Real-world delivery data from Muller and Phipps (M&P) is used to demonstrate the effectiveness of the approach. Serving deliveries from the optimal hub locations results in the saving of 815 (10%) meters per delivery.
PD-SEG: Population Disaggregation Using Deep Segmentation Networks For Improved Built Settlement Mask
Jul 29, 2023


Any policy-level decision-making procedure and academic research involving the optimum use of resources for development and planning initiatives depends on accurate population density statistics. The current cutting-edge datasets offered by WorldPop and Meta do not succeed in achieving this aim for developing nations like Pakistan; the inputs to their algorithms provide flawed estimates that fail to capture the spatial and land-use dynamics. In order to precisely estimate population counts at a resolution of 30 meters by 30 meters, we use an accurate built settlement mask obtained using deep segmentation networks and satellite imagery. The Points of Interest (POI) data is also used to exclude non-residential areas.
STEF-DHNet: Spatiotemporal External Factors Based Deep Hybrid Network for Enhanced Long-Term Taxi Demand Prediction
Jun 26, 2023Accurately predicting the demand for ride-hailing services can result in significant benefits such as more effective surge pricing strategies, improved driver positioning, and enhanced customer service. By understanding the demand fluctuations, companies can anticipate and respond to consumer requirements more efficiently, leading to increased efficiency and revenue. However, forecasting demand in a particular region can be challenging, as it is influenced by several external factors, such as time of day, weather conditions, and location. Thus, understanding and evaluating these factors is essential for predicting consumer behavior and adapting to their needs effectively. Grid-based deep learning approaches have proven effective in predicting regional taxi demand. However, these models have limitations in integrating external factors in their spatiotemporal complexity and maintaining high accuracy over extended time horizons without continuous retraining, which makes them less suitable for practical and commercial applications. To address these limitations, this paper introduces STEF-DHNet, a demand prediction model that combines Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM) to integrate external features as spatiotemporal information and capture their influence on ride-hailing demand. The proposed model is evaluated using a long-term performance metric called the rolling error, which assesses its ability to maintain high accuracy over long periods without retraining. The results show that STEF-DHNet outperforms existing state-of-the-art methods on three diverse datasets, demonstrating its potential for practical use in real-world scenarios.
Feature Selection on Sentinel-2 Multi-spectral Imagery for Efficient Tree Cover Estimation
May 31, 2023This paper proposes a multi-spectral random forest classifier with suitable feature selection and masking for tree cover estimation in urban areas. The key feature of the proposed classifier is filtering out the built-up region using spectral indices followed by random forest classification on the remaining mask with carefully selected features. Using Sentinel-2 satellite imagery, we evaluate the performance of the proposed technique on a specified area (approximately 82 acres) of Lahore University of Management Sciences (LUMS) and demonstrate that our method outperforms a conventional random forest classifier as well as state-of-the-art methods such as European Space Agency (ESA) WorldCover 10m 2020 product as well as a DeepLabv3 deep learning architecture.
Improved flood mapping for efficient policy design by fusion of Sentinel-1, Sentinel-2, and Landsat-9 imagery to identify population and infrastructure exposed to floods
May 31, 2023A reliable yet inexpensive tool for the estimation of flood water spread is conducive for efficient disaster management. The application of optical and SAR imagery in tandem provides a means of extended availability and enhanced reliability of flood mapping. We propose a methodology to merge these two types of imagery into a common data space and demonstrate its use in the identification of affected populations and infrastructure for the 2022 floods in Pakistan. The merging of optical and SAR data provides us with improved observations in cloud-prone regions; that is then used to gain additional insights into flood mapping applications. The use of open source datasets from WorldPop and OSM for population and roads respectively makes the exercise globally replicable. The integration of flood maps with spatial data on population and infrastructure facilitates informed policy design. We have shown that within the top five flood-affected districts in Sindh province, Pakistan, the affected population accounts for 31 %, while the length of affected roads measures 1410.25 km out of a total of 7537.96 km.