 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeR: Robust Conditional 3D Shape Generation from Casual Captures
Jan 16, 2026Recent advances in 3D shape generation have achieved impressive results, but most existing methods rely on clean, unoccluded, and well-segmented inputs. Such conditions are rarely met in real-world scenarios. We present ShapeR, a novel approach for conditional 3D object shape generation from casually captured sequences. Given an image sequence, we leverage off-the-shelf visual-inertial SLAM, 3D detection algorithms, and vision-language models to extract, for each object, a set of sparse SLAM points, posed multi-view images, and machine-generated captions. A rectified flow transformer trained to effectively condition on these modalities then generates high-fidelity metric 3D shapes. To ensure robustness to the challenges of casually captured data, we employ a range of techniques including on-the-fly compositional augmentations, a curriculum training scheme spanning object- and scene-level datasets, and strategies to handle background clutter. Additionally, we introduce a new evaluation benchmark comprising 178 in-the-wild objects across 7 real-world scenes with geometry annotations. Experiments show that ShapeR significantly outperforms existing approaches in this challenging setting, achieving an improvement of 2.7x in Chamfer distance compared to state of the art.
DGS-LRM: Real-Time Deformable 3D Gaussian Reconstruction From Monocular Videos
Jun 11, 2025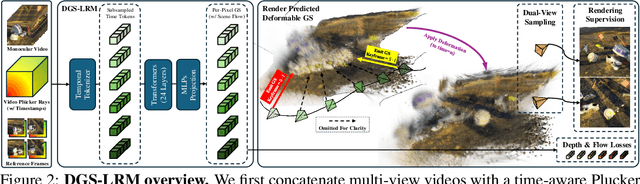
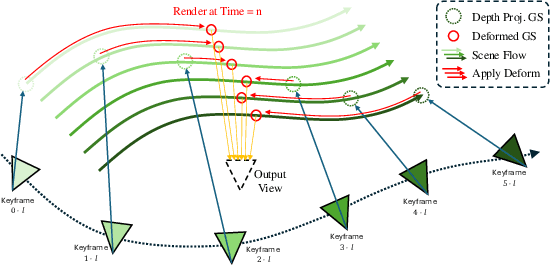
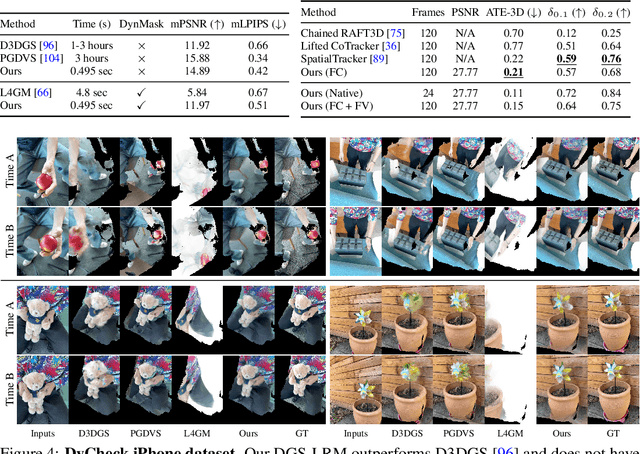

We introduce the Deformable Gaussian Splats Large Reconstruction Model (DGS-LRM), the first feed-forward method predicting deformable 3D Gaussian splats from a monocular posed video of any dynamic scene. Feed-forward scene reconstruction has gained significant attention for its ability to rapidly create digital replicas of real-world environments. However, most existing models are limited to static scenes and fail to reconstruct the motion of moving objects. Developing a feed-forward model for dynamic scene reconstruction poses significant challenges, including the scarcity of training data and the need for appropriate 3D representations and training paradigms. To address these challenges, we introduce several key technical contributions: an enhanced large-scale synthetic dataset with ground-truth multi-view videos and dense 3D scene flow supervision; a per-pixel deformable 3D Gaussian representation that is easy to learn, supports high-quality dynamic view synthesis, and enables long-range 3D tracking; and a large transformer network that achieves real-time, generalizable dynamic scene reconstruction. Extensive qualitative and quantitative experiments demonstrate that DGS-LRM achieves dynamic scene reconstruction quality comparable to optimization-based methods, while significantly outperforming the state-of-the-art predictive dynamic reconstruction method on real-world examples. Its predicted physically grounded 3D deformation is accurate and can readily adapt for long-range 3D tracking tasks, achieving performance on par with state-of-the-art monocular video 3D tracking methods.
Sonata: Self-Supervised Learning of Reliable Point Representations
Mar 20, 2025In this paper, we question whether we have a reliable self-supervised point cloud model that can be used for diverse 3D tasks via simple linear probing, even with limited data and minimal computation. We find that existing 3D self-supervised learning approaches fall short when evaluated on representation quality through linear probing. We hypothesize that this is due to what we term the "geometric shortcut", which causes representations to collapse to low-level spatial features. This challenge is unique to 3D and arises from the sparse nature of point cloud data. We address it through two key strategies: obscuring spatial information and enhancing the reliance on input features, ultimately composing a Sonata of 140k point clouds through self-distillation. Sonata is simple and intuitive, yet its learned representations are strong and reliable: zero-shot visualizations demonstrate semantic grouping, alongside strong spatial reasoning through nearest-neighbor relationships. Sonata demonstrates exceptional parameter and data efficiency, tripling linear probing accuracy (from 21.8% to 72.5%) on ScanNet and nearly doubling performance with only 1% of the data compared to previous approaches. Full fine-tuning further advances SOTA across both 3D indoor and outdoor perception tasks.
Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling
Mar 14, 2025We present a novel human-in-the-loop approach to estimate 3D scene layout that uses human feedback from an egocentric standpoint. We study this approach through introduction of a novel local correction task, where users identify local errors and prompt a model to automatically correct them. Building on SceneScript, a state-of-the-art framework for 3D scene layout estimation that leverages structured language, we propose a solution that structures this problem as "infilling", a task studied in natural language processing. We train a multi-task version of SceneScript that maintains performance on global predictions while significantly improving its local correction ability. We integrate this into a human-in-the-loop system, enabling a user to iteratively refine scene layout estimates via a low-friction "one-click fix'' workflow. Our system enables the final refined layout to diverge from the training distribution, allowing for more accurate modelling of complex layouts.
EFM3D: A Benchmark for Measuring Progress Towards 3D Egocentric Foundation Models
Jun 14, 2024



The advent of wearable computers enables a new source of context for AI that is embedded in egocentric sensor data. This new egocentric data comes equipped with fine-grained 3D location information and thus presents the opportunity for a novel class of spatial foundation models that are rooted in 3D space. To measure progress on what we term Egocentric Foundation Models (EFMs) we establish EFM3D, a benchmark with two core 3D egocentric perception tasks. EFM3D is the first benchmark for 3D object detection and surface regression on high quality annotated egocentric data of Project Aria. We propose Egocentric Voxel Lifting (EVL), a baseline for 3D EFMs. EVL leverages all available egocentric modalities and inherits foundational capabilities from 2D foundation models. This model, trained on a large simulated dataset, outperforms existing methods on the EFM3D benchmark.
EgoLifter: Open-world 3D Segmentation for Egocentric Perception
Mar 26, 2024In this paper we present EgoLifter, a novel system that can automatically segment scenes captured from egocentric sensors into a complete decomposition of individual 3D objects. The system is specifically designed for egocentric data where scenes contain hundreds of objects captured from natural (non-scanning) motion. EgoLifter adopts 3D Gaussians as the underlying representation of 3D scenes and objects and uses segmentation masks from the Segment Anything Model (SAM) as weak supervision to learn flexible and promptable definitions of object instances free of any specific object taxonomy. To handle the challenge of dynamic objects in ego-centric videos, we design a transient prediction module that learns to filter out dynamic objects in the 3D reconstruction. The result is a fully automatic pipeline that is able to reconstruct 3D object instances as collections of 3D Gaussians that collectively compose the entire scene. We created a new benchmark on the Aria Digital Twin dataset that quantitatively demonstrates its state-of-the-art performance in open-world 3D segmentation from natural egocentric input. We run EgoLifter on various egocentric activity datasets which shows the promise of the method for 3D egocentric perception at scale.
Pixel-Aligned Recurrent Queries for Multi-View 3D Object Detection
Oct 02, 2023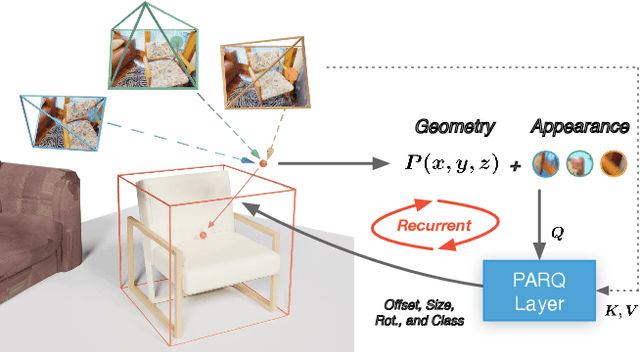

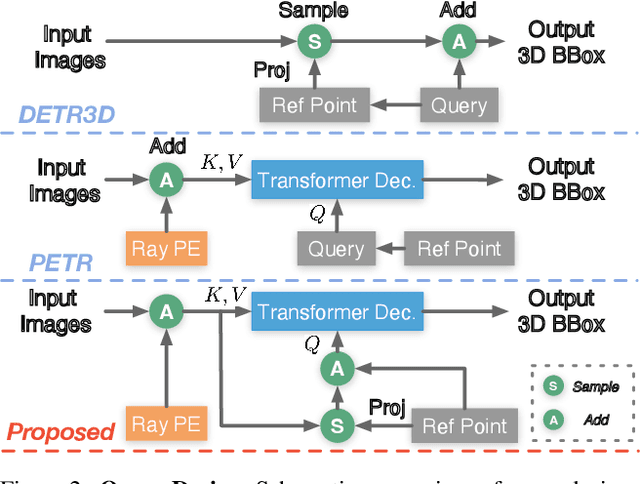

We present PARQ - a multi-view 3D object detector with transformer and pixel-aligned recurrent queries. Unlike previous works that use learnable features or only encode 3D point positions as queries in the decoder, PARQ leverages appearance-enhanced queries initialized from reference points in 3D space and updates their 3D location with recurrent cross-attention operations. Incorporating pixel-aligned features and cross attention enables the model to encode the necessary 3D-to-2D correspondences and capture global contextual information of the input images. PARQ outperforms prior best methods on the ScanNet and ARKitScenes datasets, learns and detects faster, is more robust to distribution shifts in reference points, can leverage additional input views without retraining, and can adapt inference compute by changing the number of recurrent iterations.
Project Aria: A New Tool for Egocentric Multi-Modal AI Research
Sep 12, 2023



Egocentric, multi-modal data as available on future augmented reality (AR) devices provides unique challenges and opportunities for machine perception. These future devices will need to be all-day wearable in a socially acceptable form-factor to support always available, context-aware and personalized AI applications. Our team at Meta Reality Labs Research built the Aria device, an egocentric, multi-modal data recording and streaming device with the goal to foster and accelerate research in this area. In this paper, we describe the Aria device hardware including its sensor configuration and the corresponding software tools that enable recording and processing of such data.
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Apr 04, 2023Humans can orient themselves in their 3D environments using simple 2D maps. Differently, algorithms for visual localization mostly rely on complex 3D point clouds that are expensive to build, store, and maintain over time. We bridge this gap by introducing OrienterNet, the first deep neural network that can localize an image with sub-meter accuracy using the same 2D semantic maps that humans use. OrienterNet estimates the location and orientation of a query image by matching a neural Bird's-Eye View with open and globally available maps from OpenStreetMap, enabling anyone to localize anywhere such maps are available. OrienterNet is supervised only by camera poses but learns to perform semantic matching with a wide range of map elements in an end-to-end manner. To enable this, we introduce a large crowd-sourced dataset of images captured across 12 cities from the diverse viewpoints of cars, bikes, and pedestrians. OrienterNet generalizes to new datasets and pushes the state of the art in both robotics and AR scenarios. The code and trained model will be released publicly.
Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild
Jul 21, 2022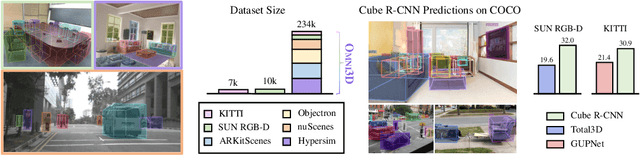
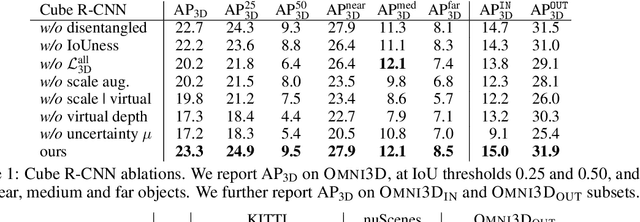
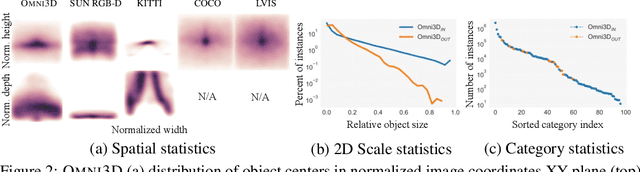
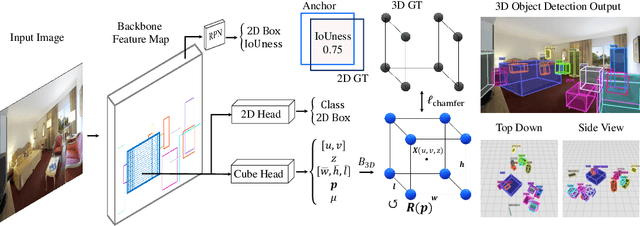
Recognizing scenes and objects in 3D from a single image is a longstanding goal of computer vision with applications in robotics and AR/VR. For 2D recognition, large datasets and scalable solutions have led to unprecedented advances. In 3D, existing benchmarks are small in size and approaches specialize in few object categories and specific domains, e.g. urban driving scenes. Motivated by the success of 2D recognition, we revisit the task of 3D object detection by introducing a large benchmark, called Omni3D. Omni3D re-purposes and combines existing datasets resulting in 234k images annotated with more than 3 million instances and 97 categories.3D detection at such scale is challenging due to variations in camera intrinsics and the rich diversity of scene and object types. We propose a model, called Cube R-CNN, designed to generalize across camera and scene types with a unified approach. We show that Cube R-CNN outperforms prior works on the larger Omni3D and existing benchmarks. Finally, we prove that Omni3D is a powerful dataset for 3D object recognition, show that it improves single-dataset performance and can accelerate learning on new smaller datasets via pre-training.