 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePandora: Articulated 3D Scene Graphs from Egocentric Vision
Mar 30, 2026Robotic mapping systems typically approach building metric-semantic scene representations from the robot's own sensors and cameras. However, these "first person" maps inherit the robot's own limitations due to its embodiment or skillset, which may leave many aspects of the environment unexplored. For example, the robot might not be able to open drawers or access wall cabinets. In this sense, the map representation is not as complete, and requires a more capable robot to fill in the gaps. We narrow these blind spots in current methods by leveraging egocentric data captured as a human naturally explores a scene wearing Project Aria glasses, giving a way to directly transfer knowledge about articulation from the human to any deployable robot. We demonstrate that, by using simple heuristics, we can leverage egocentric data to recover models of articulate object parts, with quality comparable to those of state-of-the-art methods based on other input modalities. We also show how to integrate these models into 3D scene graph representations, leading to a better understanding of object dynamics and object-container relationships. We finally demonstrate that these articulated 3D scene graphs enhance a robot's ability to perform mobile manipulation tasks, showcasing an application where a Boston Dynamics Spot is tasked with retrieving concealed target items, given only the 3D scene graph as input.
Human-in-the-Loop Local Corrections of 3D Scene Layouts via Infilling
Mar 14, 2025We present a novel human-in-the-loop approach to estimate 3D scene layout that uses human feedback from an egocentric standpoint. We study this approach through introduction of a novel local correction task, where users identify local errors and prompt a model to automatically correct them. Building on SceneScript, a state-of-the-art framework for 3D scene layout estimation that leverages structured language, we propose a solution that structures this problem as "infilling", a task studied in natural language processing. We train a multi-task version of SceneScript that maintains performance on global predictions while significantly improving its local correction ability. We integrate this into a human-in-the-loop system, enabling a user to iteratively refine scene layout estimates via a low-friction "one-click fix'' workflow. Our system enables the final refined layout to diverge from the training distribution, allowing for more accurate modelling of complex layouts.
SceneScript: Reconstructing Scenes With An Autoregressive Structured Language Model
Mar 19, 2024

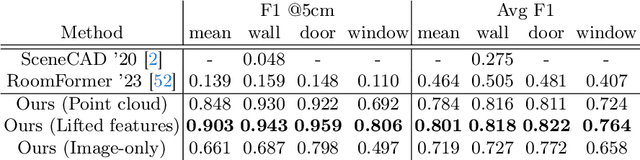
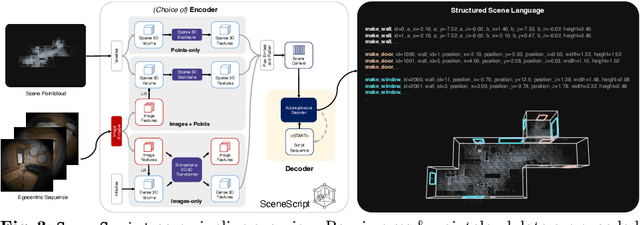
We introduce SceneScript, a method that directly produces full scene models as a sequence of structured language commands using an autoregressive, token-based approach. Our proposed scene representation is inspired by recent successes in transformers & LLMs, and departs from more traditional methods which commonly describe scenes as meshes, voxel grids, point clouds or radiance fields. Our method infers the set of structured language commands directly from encoded visual data using a scene language encoder-decoder architecture. To train SceneScript, we generate and release a large-scale synthetic dataset called Aria Synthetic Environments consisting of 100k high-quality in-door scenes, with photorealistic and ground-truth annotated renders of egocentric scene walkthroughs. Our method gives state-of-the art results in architectural layout estimation, and competitive results in 3D object detection. Lastly, we explore an advantage for SceneScript, which is the ability to readily adapt to new commands via simple additions to the structured language, which we illustrate for tasks such as coarse 3D object part reconstruction.
RICE: Refining Instance Masks in Cluttered Environments with Graph Neural Networks
Jun 29, 2021



Segmenting unseen object instances in cluttered environments is an important capability that robots need when functioning in unstructured environments. While previous methods have exhibited promising results, they still tend to provide incorrect results in highly cluttered scenes. We postulate that a network architecture that encodes relations between objects at a high-level can be beneficial. Thus, in this work, we propose a novel framework that refines the output of such methods by utilizing a graph-based representation of instance masks. We train deep networks capable of sampling smart perturbations to the segmentations, and a graph neural network, which can encode relations between objects, to evaluate the perturbed segmentations. Our proposed method is orthogonal to previous works and achieves state-of-the-art performance when combined with them. We demonstrate an application that uses uncertainty estimates generated by our method to guide a manipulator, leading to efficient understanding of cluttered scenes. Code, models, and video can be found at https://github.com/chrisdxie/rice .
FiG-NeRF: Figure-Ground Neural Radiance Fields for 3D Object Category Modelling
Apr 17, 2021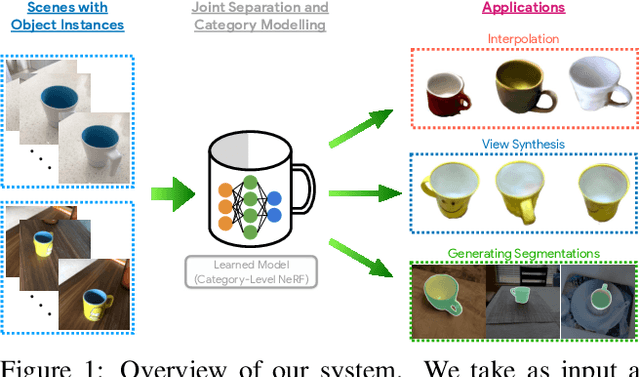

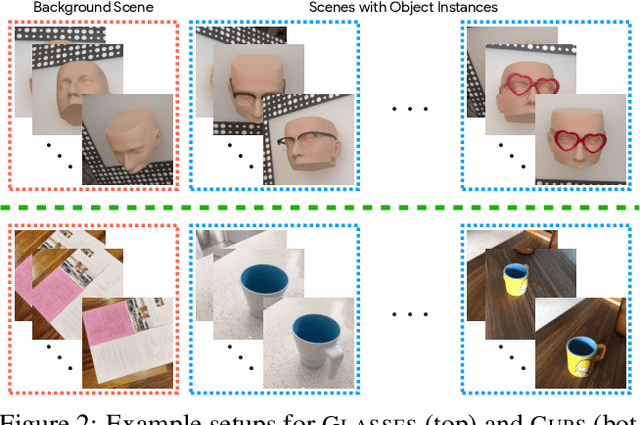
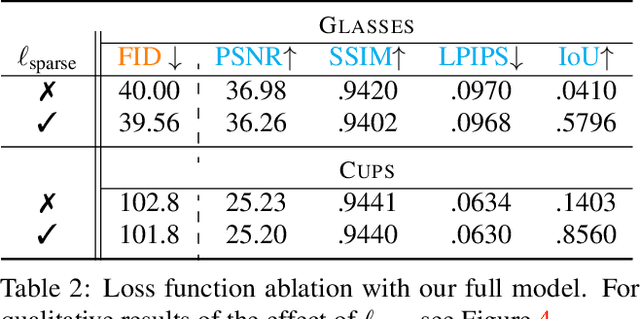
We investigate the use of Neural Radiance Fields (NeRF) to learn high quality 3D object category models from collections of input images. In contrast to previous work, we are able to do this whilst simultaneously separating foreground objects from their varying backgrounds. We achieve this via a 2-component NeRF model, FiG-NeRF, that prefers explanation of the scene as a geometrically constant background and a deformable foreground that represents the object category. We show that this method can learn accurate 3D object category models using only photometric supervision and casually captured images of the objects. Additionally, our 2-part decomposition allows the model to perform accurate and crisp amodal segmentation. We quantitatively evaluate our method with view synthesis and image fidelity metrics, using synthetic, lab-captured, and in-the-wild data. Our results demonstrate convincing 3D object category modelling that exceed the performance of existing methods.
Amodal 3D Reconstruction for Robotic Manipulation via Stability and Connectivity
Sep 28, 2020



Learning-based 3D object reconstruction enables single- or few-shot estimation of 3D object models. For robotics, this holds the potential to allow model-based methods to rapidly adapt to novel objects and scenes. Existing 3D reconstruction techniques optimize for visual reconstruction fidelity, typically measured by chamfer distance or voxel IOU. We find that when applied to realistic, cluttered robotics environments, these systems produce reconstructions with low physical realism, resulting in poor task performance when used for model-based control. We propose ARM, an amodal 3D reconstruction system that introduces (1) a stability prior over object shapes, (2) a connectivity prior, and (3) a multi-channel input representation that allows for reasoning over relationships between groups of objects. By using these priors over the physical properties of objects, our system improves reconstruction quality not just by standard visual metrics, but also performance of model-based control on a variety of robotics manipulation tasks in challenging, cluttered environments. Code is available at github.com/wagnew3/ARM.
Learning RGB-D Feature Embeddings for Unseen Object Instance Segmentation
Jul 30, 2020



Segmenting unseen objects in cluttered scenes is an important skill that robots need to acquire in order to perform tasks in new environments. In this work, we propose a new method for unseen object instance segmentation by learning RGB-D feature embeddings from synthetic data. A metric learning loss function is utilized to learn to produce pixel-wise feature embeddings such that pixels from the same object are close to each other and pixels from different objects are separated in the embedding space. With the learned feature embeddings, a mean shift clustering algorithm can be applied to discover and segment unseen objects. We further improve the segmentation accuracy with a new two-stage clustering algorithm. Our method demonstrates that non-photorealistic synthetic RGB and depth images can be used to learn feature embeddings that transfer well to real-world images for unseen object instance segmentation.
Unseen Object Instance Segmentation for Robotic Environments
Jul 16, 2020



In order to function in unstructured environments, robots need the ability to recognize unseen objects. We take a step in this direction by tackling the problem of segmenting unseen object instances in tabletop environments. However, the type of large-scale real-world dataset required for this task typically does not exist for most robotic settings, which motivates the use of synthetic data. Our proposed method, UOIS-Net, separately leverages synthetic RGB and synthetic depth for unseen object instance segmentation. UOIS-Net is comprised of two stages: first, it operates only on depth to produce object instance center votes in 2D or 3D and assembles them into rough initial masks. Secondly, these initial masks are refined using RGB. Surprisingly, our framework is able to learn from synthetic RGB-D data where the RGB is non-photorealistic. To train our method, we introduce a large-scale synthetic dataset of random objects on tabletops. We show that our method can produce sharp and accurate segmentation masks, outperforming state-of-the-art methods on unseen object instance segmentation. We also show that our method can segment unseen objects for robot grasping.
The Best of Both Modes: Separately Leveraging RGB and Depth for Unseen Object Instance Segmentation
Jul 30, 2019



In order to function in unstructured environments, robots need the ability to recognize unseen novel objects. We take a step in this direction by tackling the problem of segmenting unseen object instances in tabletop environments. However, the type of large-scale real-world dataset required for this task typically does not exist for most robotic settings, which motivates the use of synthetic data. We propose a novel method that separately leverages synthetic RGB and synthetic depth for unseen object instance segmentation. Our method is comprised of two stages where the first stage operates only on depth to produce rough initial masks, and the second stage refines these masks with RGB. Surprisingly, our framework is able to learn from synthetic RGB-D data where the RGB is non-photorealistic. To train our method, we introduce a large-scale synthetic dataset of random objects on tabletops. We show that our method, trained on this dataset, can produce sharp and accurate masks, outperforming state-of-the-art methods on unseen object instance segmentation. We also show that our method can segment unseen objects for robot grasping. Code, models and video can be found at https://rse-lab.cs.washington.edu/projects/unseen-object-instance-segmentation/.
Object Discovery in Videos as Foreground Motion Clustering
Dec 06, 2018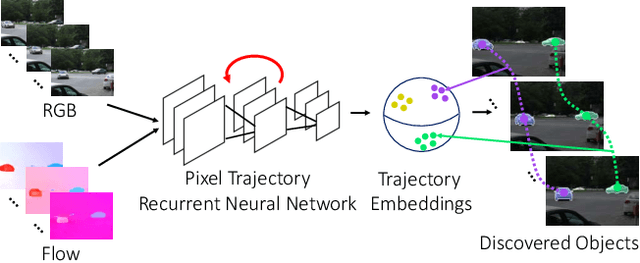
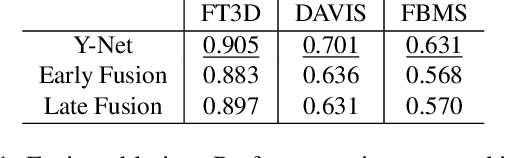
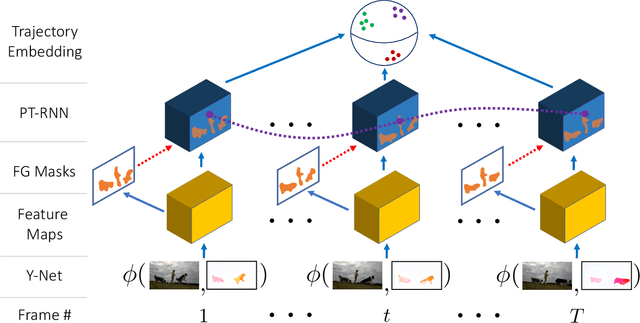
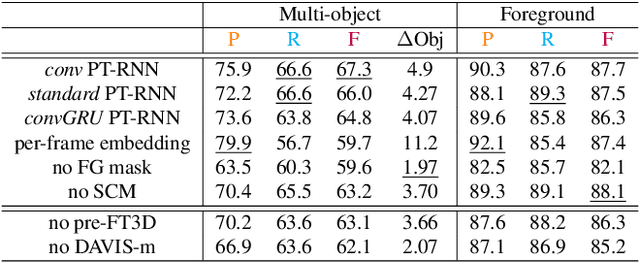
We consider the problem of providing dense segmentation masks for object discovery in videos. We formulate the object discovery problem as foreground motion clustering, where the goal is to cluster foreground pixels in videos into different objects. We introduce a novel pixel-trajectory recurrent neural network that learns feature embeddings of foreground pixel trajectories linked in time. By clustering the pixel trajectories using the learned feature embeddings, our method establishes correspondences between foreground object masks across video frames. To demonstrate the effectiveness of our framework for object discovery, we conduct experiments on commonly used datasets for motion segmentation, where we achieve state-of-the-art performance.