 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Electro-communication and Electro-sensing in Weakly Electric Fish using Multi-Agent Deep Reinforcement Learning
Nov 11, 2025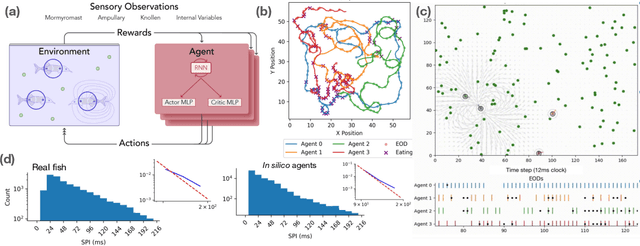
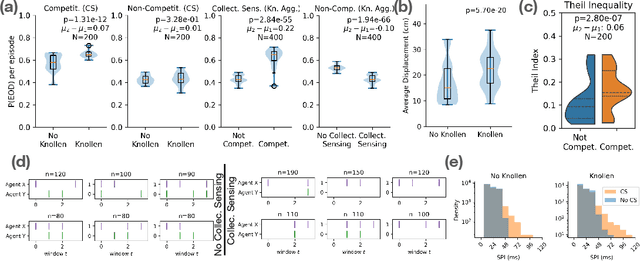
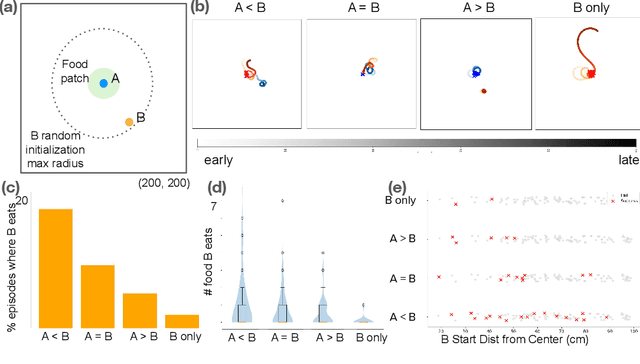
Weakly electric fish, like Gnathonemus petersii, use a remarkable electrical modality for active sensing and communication, but studying their rich electrosensing and electrocommunication behavior and associated neural activity in naturalistic settings remains experimentally challenging. Here, we present a novel biologically-inspired computational framework to study these behaviors, where recurrent neural network (RNN) based artificial agents trained via multi-agent reinforcement learning (MARL) learn to modulate their electric organ discharges (EODs) and movement patterns to collectively forage in virtual environments. Trained agents demonstrate several emergent features consistent with real fish collectives, including heavy tailed EOD interval distributions, environmental context dependent shifts in EOD interval distributions, and social interaction patterns like freeloading, where agents reduce their EOD rates while benefiting from neighboring agents' active sensing. A minimal two-fish assay further isolates the role of electro-communication, showing that access to conspecific EODs and relative dominance jointly shape foraging success. Notably, these behaviors emerge through evolution-inspired rewards for individual fitness and emergent inter-agent interactions, rather than through rewarding agents explicitly for social interactions. Our work has broad implications for the neuroethology of weakly electric fish, as well as other social, communicating animals in which extensive recordings from multiple individuals, and thus traditional data-driven modeling, are infeasible.
Decomposing Elements of Problem Solving: What "Math" Does RL Teach?
May 28, 2025Mathematical reasoning tasks have become prominent benchmarks for assessing the reasoning capabilities of LLMs, especially with reinforcement learning (RL) methods such as GRPO showing significant performance gains. However, accuracy metrics alone do not support fine-grained assessment of capabilities and fail to reveal which problem-solving skills have been internalized. To better understand these capabilities, we propose to decompose problem solving into fundamental capabilities: Plan (mapping questions to sequences of steps), Execute (correctly performing solution steps), and Verify (identifying the correctness of a solution). Empirically, we find that GRPO mainly enhances the execution skill-improving execution robustness on problems the model already knows how to solve-a phenomenon we call temperature distillation. More importantly, we show that RL-trained models struggle with fundamentally new problems, hitting a 'coverage wall' due to insufficient planning skills. To explore RL's impact more deeply, we construct a minimal, synthetic solution-tree navigation task as an analogy for mathematical problem-solving. This controlled setup replicates our empirical findings, confirming RL primarily boosts execution robustness. Importantly, in this setting, we identify conditions under which RL can potentially overcome the coverage wall through improved exploration and generalization to new solution paths. Our findings provide insights into the role of RL in enhancing LLM reasoning, expose key limitations, and suggest a path toward overcoming these barriers. Code is available at https://github.com/cfpark00/RL-Wall.
Convergent Functions, Divergent Forms
May 27, 2025We introduce LOKI, a compute-efficient framework for co-designing morphologies and control policies that generalize across unseen tasks. Inspired by biological adaptation -- where animals quickly adjust to morphological changes -- our method overcomes the inefficiencies of traditional evolutionary and quality-diversity algorithms. We propose learning convergent functions: shared control policies trained across clusters of morphologically similar designs in a learned latent space, drastically reducing the training cost per design. Simultaneously, we promote divergent forms by replacing mutation with dynamic local search, enabling broader exploration and preventing premature convergence. The policy reuse allows us to explore 780$\times$ more designs using 78% fewer simulation steps and 40% less compute per design. Local competition paired with a broader search results in a diverse set of high-performing final morphologies. Using the UNIMAL design space and a flat-terrain locomotion task, LOKI discovers a rich variety of designs -- ranging from quadrupeds to crabs, bipedals, and spinners -- far more diverse than those produced by prior work. These morphologies also transfer better to unseen downstream tasks in agility, stability, and manipulation domains (e.g., 2$\times$ higher reward on bump and push box incline tasks). Overall, our approach produces designs that are both diverse and adaptable, with substantially greater sample efficiency than existing co-design methods. (Project website: https://loki-codesign.github.io/)
Data-Efficient Multi-Agent Spatial Planning with LLMs
Feb 26, 2025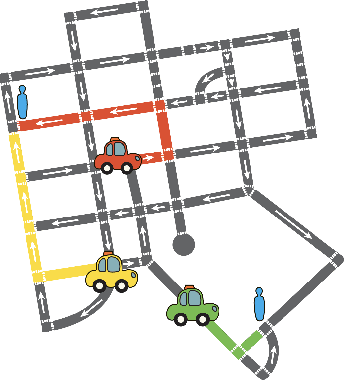
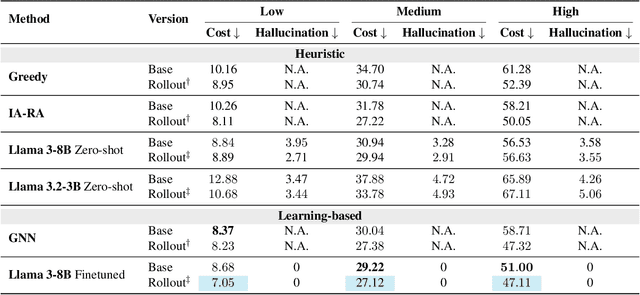
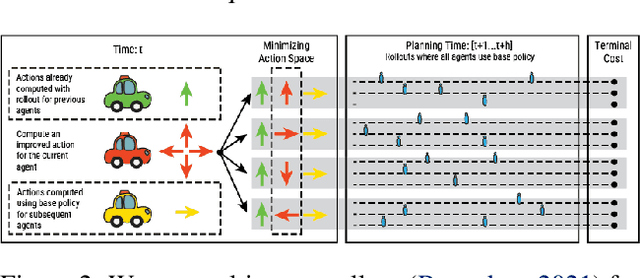
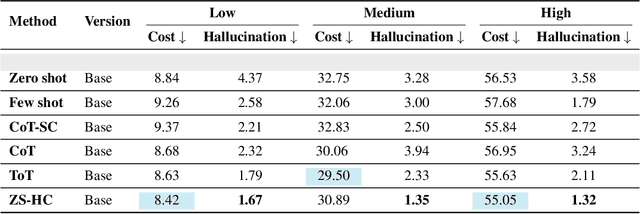
In this project, our goal is to determine how to leverage the world-knowledge of pretrained large language models for efficient and robust learning in multiagent decision making. We examine this in a taxi routing and assignment problem where agents must decide how to best pick up passengers in order to minimize overall waiting time. While this problem is situated on a graphical road network, we show that with the proper prompting zero-shot performance is quite strong on this task. Furthermore, with limited fine-tuning along with the one-at-a-time rollout algorithm for look ahead, LLMs can out-compete existing approaches with 50 times fewer environmental interactions. We also explore the benefits of various linguistic prompting approaches and show that including certain easy-to-compute information in the prompt significantly improves performance. Finally, we highlight the LLM's built-in semantic understanding, showing its ability to adapt to environmental factors through simple prompts.
Learning to Build by Building Your Own Instructions
Oct 01, 2024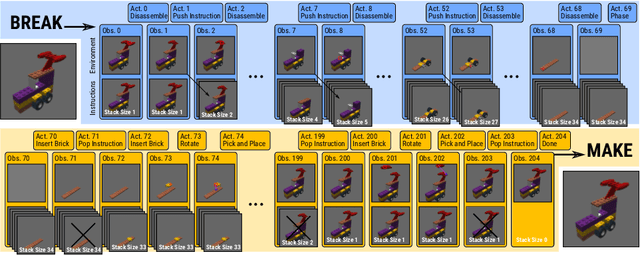
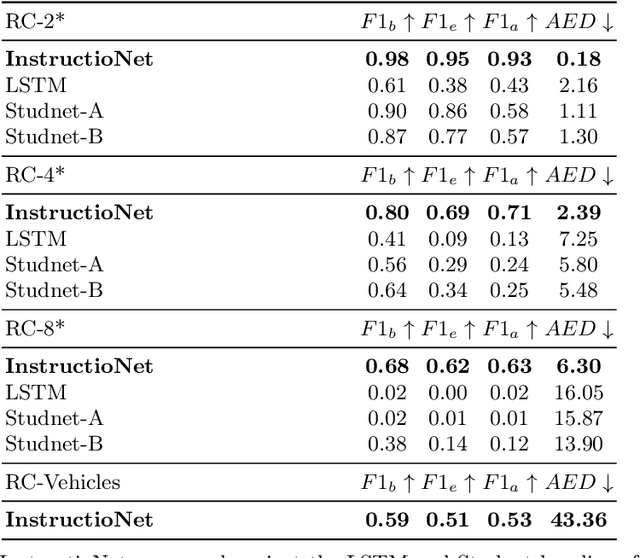

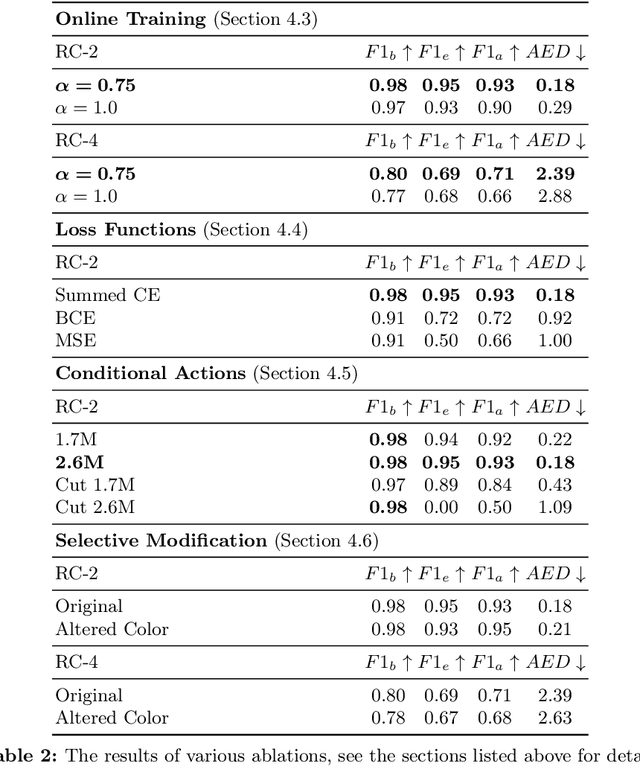
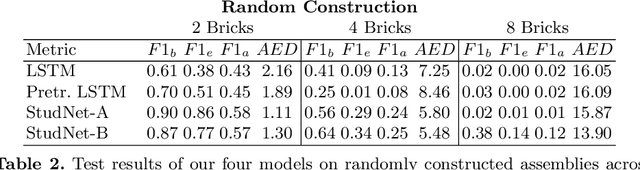
Structural understanding of complex visual objects is an important unsolved component of artificial intelligence. To study this, we develop a new technique for the recently proposed Break-and-Make problem in LTRON where an agent must learn to build a previously unseen LEGO assembly using a single interactive session to gather information about its components and their structure. We attack this problem by building an agent that we call \textbf{\ours} that is able to make its own visual instruction book. By disassembling an unseen assembly and periodically saving images of it, the agent is able to create a set of instructions so that it has the information necessary to rebuild it. These instructions form an explicit memory that allows the model to reason about the assembly process one step at a time, avoiding the need for long-term implicit memory. This in turn allows us to train on much larger LEGO assemblies than has been possible in the past. To demonstrate the power of this model, we release a new dataset of procedurally built LEGO vehicles that contain an average of 31 bricks each and require over one hundred steps to disassemble and reassemble. We train these models using online imitation learning which allows the model to learn from its own mistakes. Finally, we also provide some small improvements to LTRON and the Break-and-Make problem that simplify the learning environment and improve usability.
URDFormer: A Pipeline for Constructing Articulated Simulation Environments from Real-World Images
May 19, 2024



Constructing simulation scenes that are both visually and physically realistic is a problem of practical interest in domains ranging from robotics to computer vision. This problem has become even more relevant as researchers wielding large data-hungry learning methods seek new sources of training data for physical decision-making systems. However, building simulation models is often still done by hand. A graphic designer and a simulation engineer work with predefined assets to construct rich scenes with realistic dynamic and kinematic properties. While this may scale to small numbers of scenes, to achieve the generalization properties that are required for data-driven robotic control, we require a pipeline that is able to synthesize large numbers of realistic scenes, complete with 'natural' kinematic and dynamic structures. To attack this problem, we develop models for inferring structure and generating simulation scenes from natural images, allowing for scalable scene generation from web-scale datasets. To train these image-to-simulation models, we show how controllable text-to-image generative models can be used in generating paired training data that allows for modeling of the inverse problem, mapping from realistic images back to complete scene models. We show how this paradigm allows us to build large datasets of scenes in simulation with semantic and physical realism. We present an integrated end-to-end pipeline that generates simulation scenes complete with articulated kinematic and dynamic structures from real-world images and use these for training robotic control policies. We then robustly deploy in the real world for tasks like articulated object manipulation. In doing so, our work provides both a pipeline for large-scale generation of simulation environments and an integrated system for training robust robotic control policies in the resulting environments.
ENTL: Embodied Navigation Trajectory Learner
Apr 07, 2023



We propose Embodied Navigation Trajectory Learner (ENTL), a method for extracting long sequence representations for embodied navigation. Our approach unifies world modeling, localization and imitation learning into a single sequence prediction task. We train our model using vector-quantized predictions of future states conditioned on current states and actions. ENTL's generic architecture enables sharing of the spatio-temporal sequence encoder for multiple challenging embodied tasks. We achieve competitive performance on navigation tasks using significantly less data than strong baselines while performing auxiliary tasks such as localization and future frame prediction (a proxy for world modeling). A key property of our approach is that the model is pre-trained without any explicit reward signal, which makes the resulting model generalizable to multiple tasks and environments.
Break and Make: Interactive Structural Understanding Using LEGO Bricks
Jul 27, 2022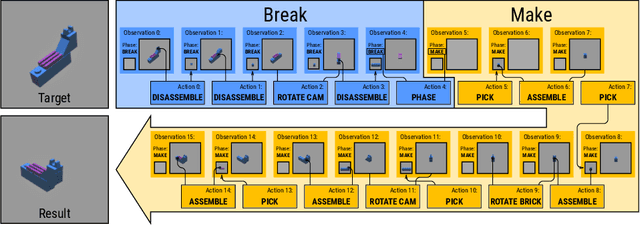
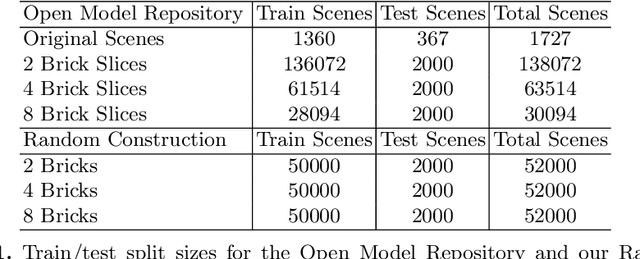
Visual understanding of geometric structures with complex spatial relationships is a fundamental component of human intelligence. As children, we learn how to reason about structure not only from observation, but also by interacting with the world around us -- by taking things apart and putting them back together again. The ability to reason about structure and compositionality allows us to not only build things, but also understand and reverse-engineer complex systems. In order to advance research in interactive reasoning for part-based geometric understanding, we propose a challenging new assembly problem using LEGO bricks that we call Break and Make. In this problem an agent is given a LEGO model and attempts to understand its structure by interactively inspecting and disassembling it. After this inspection period, the agent must then prove its understanding by rebuilding the model from scratch using low-level action primitives. In order to facilitate research on this problem we have built LTRON, a fully interactive 3D simulator that allows learning agents to assemble, disassemble and manipulate LEGO models. We pair this simulator with a new dataset of fan-made LEGO creations that have been uploaded to the internet in order to provide complex scenes containing over a thousand unique brick shapes. We take a first step towards solving this problem using sequence-to-sequence models that provide guidance for how to make progress on this challenging problem. Our simulator and data are available at github.com/aaronwalsman/ltron. Additional training code and PyTorch examples are available at github.com/aaronwalsman/ltron-torch-eccv22.
Amodal 3D Reconstruction for Robotic Manipulation via Stability and Connectivity
Sep 28, 2020



Learning-based 3D object reconstruction enables single- or few-shot estimation of 3D object models. For robotics, this holds the potential to allow model-based methods to rapidly adapt to novel objects and scenes. Existing 3D reconstruction techniques optimize for visual reconstruction fidelity, typically measured by chamfer distance or voxel IOU. We find that when applied to realistic, cluttered robotics environments, these systems produce reconstructions with low physical realism, resulting in poor task performance when used for model-based control. We propose ARM, an amodal 3D reconstruction system that introduces (1) a stability prior over object shapes, (2) a connectivity prior, and (3) a multi-channel input representation that allows for reasoning over relationships between groups of objects. By using these priors over the physical properties of objects, our system improves reconstruction quality not just by standard visual metrics, but also performance of model-based control on a variety of robotics manipulation tasks in challenging, cluttered environments. Code is available at github.com/wagnew3/ARM.
In the Wild: From ML Models to Pragmatic ML Systems
Jul 06, 2020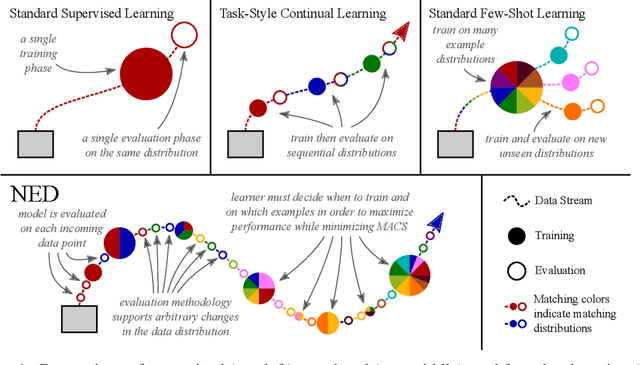
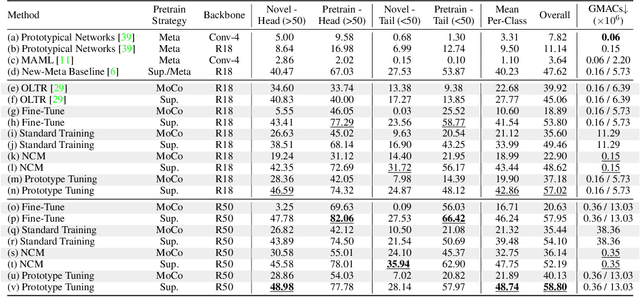
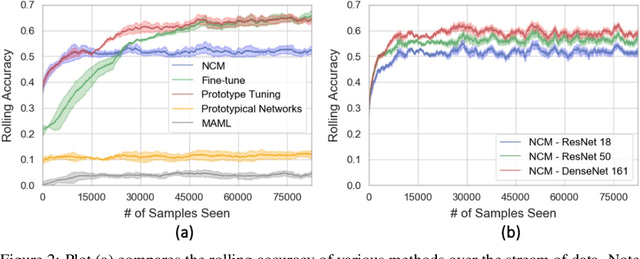
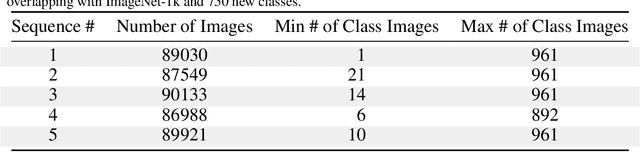
Enabling robust intelligence in the wild entails learning systems that offer uninterrupted inference while affording sustained training, with varying amounts of data & supervision. Such a pragmatic ML system should be able to cope with the openness & flexibility inherent in the real world. The machine learning community has organically broken down this challenging task into manageable sub tasks such as supervised, few-shot, continual, & self-supervised learning; each affording distinctive challenges & leading to a unique set of methods. Notwithstanding this amazing progress, the restricted & isolated nature of these tasks has resulted in methods that excel in one setting, but struggle to extend beyond them. To foster the research required to extend ML models to ML systems, we introduce a unified learning & evaluation framework - iN thE wilD (NED). NED is designed to be a more general paradigm by loosening the restrictive design decisions of past settings (e.g. closed-world assumption) & imposing fewer restrictions on learning algorithms (e.g. predefined train & test phases). The learners can infer the experimental parameters themselves by optimizing for both accuracy & compute. In NED, a learner receives a stream of data & makes sequential predictions while choosing how to update itself, adapt to data from novel categories, & deal with changing data distributions; while optimizing the total amount of compute. We evaluate a large set of existing methods across several sub fields using NED & present surprising yet revealing findings about modern day techniques. For instance, prominent few shot methods break down in NED, achieving dramatic drops of over 40% accuracy relative to simple baselines; & the SOTA self-supervised methods Momentum Contrast obtains 35% lower accuracy than supervised pretraining on novel classes. We also show that a simple baseline outperforms existing methods on NED.