 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanisms of Misgeneralization in Physical Sequence Modeling
May 19, 2026Generative sequence models are often trained to plan motion in physical domains, from robotics to mechanical simulations. When constructing a dataset to train such a model, engineers may curate demonstrations to specify how trajectories should be distributed over a physical quantity like travel distance or mechanical energy. For example, a roboticist building a maze navigation agent might choose demonstrations whose travel distances cover a fixed range uniformly, hoping to constrain the agent's expected power usage. We find that standard deep learning can violate this intent: each generated trajectory can seem plausible on its own, but the aggregate distribution over the physical quantity is wrong. We call this failure physical misgeneralization, and develop an account of its mechanism. Using controlled synthetic tasks, we show that physical misgeneralization arises when local errors typical of the model class propagate through the physical measurement to shift the recovered distribution. We estimate these errors with a data deviation kernel, and we use it to predict which physical quantities gain or lose mass in both our synthetic and more applied maze navigation and double-pendulum motion tasks. Finally, our mechanistic interpretation helps identify which mitigation strategies are structurally promising, and we use it to propose a kernel-informed intervention.
When Is Collective Intelligence a Lottery? Multi-Agent Scaling Laws for Memetic Drift in LLMs
Mar 25, 2026Multi-agent systems powered by large language models (LLMs) are increasingly deployed in settings that shape consequential decisions, both directly and indirectly. Yet it remains unclear whether their outcomes reflect collective reasoning, systematic bias, or mere chance. Recent work has sharpened this question with naming games, showing that even when no individual agent favors any label a priori, populations rapidly break symmetry and reach consensus. Here, we reveal the mechanism by introducing a minimal model, Quantized Simplex Gossip (QSG), and trace the microscopic origin of this agreement to mutual in-context learning. In QSG, agents maintain internal belief states but learn from one another's sampled outputs, so one agent's arbitrary choice becomes the next agent's evidence and can compound toward agreement. By analogy with neutral evolution, we call this sampling-driven regime memetic drift. QSG predicts a crossover from a drift-dominated regime, where consensus is effectively a lottery, to a selection regime, where weak biases are amplified and shape the outcome. We derive scaling laws for drift-induced polarization as a function of population size, communication bandwidth, in-context adaptation rate, and agents' internal uncertainty, and we validate them in both QSG simulations and naming-game experiments with LLM populations. Together, these results provide a framework for studying the collective mechanisms of social representation formation in multi-agent systems.
Provable Low-Frequency Bias of In-Context Learning of Representations
Jul 17, 2025In-context learning (ICL) enables large language models (LLMs) to acquire new behaviors from the input sequence alone without any parameter updates. Recent studies have shown that ICL can surpass the original meaning learned in pretraining stage through internalizing the structure the data-generating process (DGP) of the prompt into the hidden representations. However, the mechanisms by which LLMs achieve this ability is left open. In this paper, we present the first rigorous explanation of such phenomena by introducing a unified framework of double convergence, where hidden representations converge both over context and across layers. This double convergence process leads to an implicit bias towards smooth (low-frequency) representations, which we prove analytically and verify empirically. Our theory explains several open empirical observations, including why learned representations exhibit globally structured but locally distorted geometry, and why their total energy decays without vanishing. Moreover, our theory predicts that ICL has an intrinsic robustness towards high-frequency noise, which we empirically confirm. These results provide new insights into the underlying mechanisms of ICL, and a theoretical foundation to study it that hopefully extends to more general data distributions and settings.
Decomposing Elements of Problem Solving: What "Math" Does RL Teach?
May 28, 2025Mathematical reasoning tasks have become prominent benchmarks for assessing the reasoning capabilities of LLMs, especially with reinforcement learning (RL) methods such as GRPO showing significant performance gains. However, accuracy metrics alone do not support fine-grained assessment of capabilities and fail to reveal which problem-solving skills have been internalized. To better understand these capabilities, we propose to decompose problem solving into fundamental capabilities: Plan (mapping questions to sequences of steps), Execute (correctly performing solution steps), and Verify (identifying the correctness of a solution). Empirically, we find that GRPO mainly enhances the execution skill-improving execution robustness on problems the model already knows how to solve-a phenomenon we call temperature distillation. More importantly, we show that RL-trained models struggle with fundamentally new problems, hitting a 'coverage wall' due to insufficient planning skills. To explore RL's impact more deeply, we construct a minimal, synthetic solution-tree navigation task as an analogy for mathematical problem-solving. This controlled setup replicates our empirical findings, confirming RL primarily boosts execution robustness. Importantly, in this setting, we identify conditions under which RL can potentially overcome the coverage wall through improved exploration and generalization to new solution paths. Our findings provide insights into the role of RL in enhancing LLM reasoning, expose key limitations, and suggest a path toward overcoming these barriers. Code is available at https://github.com/cfpark00/RL-Wall.
CT-OT Flow: Estimating Continuous-Time Dynamics from Discrete Temporal Snapshots
May 23, 2025In many real-world scenarios, such as single-cell RNA sequencing, data are observed only as discrete-time snapshots spanning finite time intervals and subject to noisy timestamps, with no continuous trajectories available. Recovering the underlying continuous-time dynamics from these snapshots with coarse and noisy observation times is a critical and challenging task. We propose Continuous-Time Optimal Transport Flow (CT-OT Flow), which first infers high-resolution time labels via partial optimal transport and then reconstructs a continuous-time data distribution through a temporal kernel smoothing. This reconstruction enables accurate training of dynamics models such as ODEs and SDEs. CT-OT Flow consistently outperforms state-of-the-art methods on synthetic benchmarks and achieves lower reconstruction errors on real scRNA-seq and typhoon-track datasets. Our results highlight the benefits of explicitly modeling temporal discretization and timestamp uncertainty, offering an accurate and general framework for bridging discrete snapshots and continuous-time processes.
$\textit{New News}$: System-2 Fine-tuning for Robust Integration of New Knowledge
May 03, 2025Humans and intelligent animals can effortlessly internalize new information ("news") and accurately extract the implications for performing downstream tasks. While large language models (LLMs) can achieve this through in-context learning (ICL) when the news is explicitly given as context, fine-tuning remains challenging for the models to consolidate learning in weights. In this paper, we introduce $\textit{New News}$, a dataset composed of hypothetical yet plausible news spanning multiple domains (mathematics, coding, discoveries, leaderboards, events), accompanied by downstream evaluation questions whose correct answers critically depend on understanding and internalizing the news. We first demonstrate a substantial gap between naive fine-tuning and in-context learning (FT-ICL gap) on our news dataset. To address this gap, we explore a suite of self-play data generation protocols -- paraphrases, implications and Self-QAs -- designed to distill the knowledge from the model with context into the weights of the model without the context, which we term $\textit{System-2 Fine-tuning}$ (Sys2-FT). We systematically evaluate ICL and Sys2-FT performance across data domains and model scales with the Qwen 2.5 family of models. Our results demonstrate that the self-QA protocol of Sys2-FT significantly improves models' in-weight learning of the news. Furthermore, we discover the $\textit{contexual shadowing effect}$, where training with the news $\textit{in context}$ followed by its rephrases or QAs degrade learning of the news. Finally, we show preliminary evidence of an emerging scaling law of Sys2-FT.
A ghost mechanism: An analytical model of abrupt learning
Jan 04, 2025\emph{Abrupt learning} is commonly observed in neural networks, where long plateaus in network performance are followed by rapid convergence to a desirable solution. Yet, despite its common occurrence, the complex interplay of task, network architecture, and learning rule has made it difficult to understand the underlying mechanisms. Here, we introduce a minimal dynamical system trained on a delayed-activation task and demonstrate analytically how even a one-dimensional system can exhibit abrupt learning through ghost points rather than bifurcations. Through our toy model, we show that the emergence of a ghost point destabilizes learning dynamics. We identify a critical learning rate that prevents learning through two distinct loss landscape features: a no-learning zone and an oscillatory minimum. Testing these predictions in recurrent neural networks (RNNs), we confirm that ghost points precede abrupt learning and accompany the destabilization of learning. We demonstrate two complementary remedies: lowering the model output confidence prevents the network from getting stuck in no-learning zones, while increasing trainable ranks beyond task requirements (\textit{i.e.}, adding sloppy parameters) provides more stable learning trajectories. Our model reveals a bifurcation-free mechanism for abrupt learning and illustrates the importance of both deliberate uncertainty and redundancy in stabilizing learning dynamics.
ICLR: In-Context Learning of Representations
Dec 29, 2024



Recent work has demonstrated that semantics specified by pretraining data influence how representations of different concepts are organized in a large language model (LLM). However, given the open-ended nature of LLMs, e.g., their ability to in-context learn, we can ask whether models alter these pretraining semantics to adopt alternative, context-specified ones. Specifically, if we provide in-context exemplars wherein a concept plays a different role than what the pretraining data suggests, do models reorganize their representations in accordance with these novel semantics? To answer this question, we take inspiration from the theory of conceptual role semantics and define a toy "graph tracing" task wherein the nodes of the graph are referenced via concepts seen during training (e.g., apple, bird, etc.) and the connectivity of the graph is defined via some predefined structure (e.g., a square grid). Given exemplars that indicate traces of random walks on the graph, we analyze intermediate representations of the model and find that as the amount of context is scaled, there is a sudden re-organization from pretrained semantic representations to in-context representations aligned with the graph structure. Further, we find that when reference concepts have correlations in their semantics (e.g., Monday, Tuesday, etc.), the context-specified graph structure is still present in the representations, but is unable to dominate the pretrained structure. To explain these results, we analogize our task to energy minimization for a predefined graph topology, providing evidence towards an implicit optimization process to infer context-specified semantics. Overall, our findings indicate scaling context-size can flexibly re-organize model representations, possibly unlocking novel capabilities.
Forking Paths in Neural Text Generation
Dec 10, 2024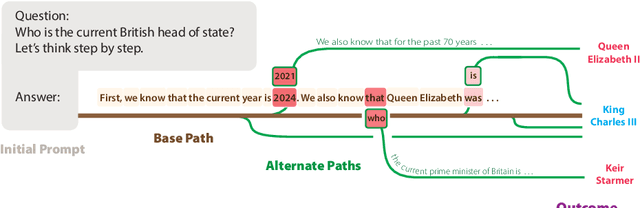
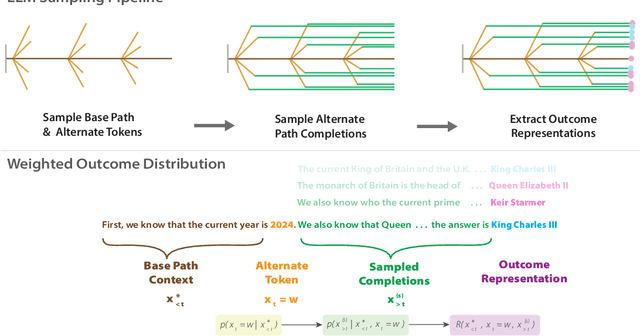
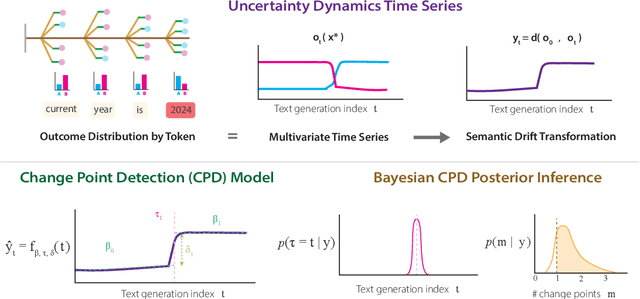
Estimating uncertainty in Large Language Models (LLMs) is important for properly evaluating LLMs, and ensuring safety for users. However, prior approaches to uncertainty estimation focus on the final answer in generated text, ignoring intermediate steps that might dramatically impact the outcome. We hypothesize that there exist key forking tokens, such that re-sampling the system at those specific tokens, but not others, leads to very different outcomes. To test this empirically, we develop a novel approach to representing uncertainty dynamics across individual tokens of text generation, and applying statistical models to test our hypothesis. Our approach is highly flexible: it can be applied to any dataset and any LLM, without fine tuning or accessing model weights. We use our method to analyze LLM responses on 7 different tasks across 4 domains, spanning a wide range of typical use cases. We find many examples of forking tokens, including surprising ones such as punctuation marks, suggesting that LLMs are often just a single token away from saying something very different.
Competition Dynamics Shape Algorithmic Phases of In-Context Learning
Dec 01, 2024



In-Context Learning (ICL) has significantly expanded the general-purpose nature of large language models, allowing them to adapt to novel tasks using merely the inputted context. This has motivated a series of papers that analyze tractable synthetic domains and postulate precise mechanisms that may underlie ICL. However, the use of relatively distinct setups that often lack a sequence modeling nature to them makes it unclear how general the reported insights from such studies are. Motivated by this, we propose a synthetic sequence modeling task that involves learning to simulate a finite mixture of Markov chains. As we show, models trained on this task reproduce most well-known results on ICL, hence offering a unified setting for studying the concept. Building on this setup, we demonstrate we can explain a model's behavior by decomposing it into four broad algorithms that combine a fuzzy retrieval vs. inference approach with either unigram or bigram statistics of the context. These algorithms engage in a competition dynamics to dominate model behavior, with the precise experimental conditions dictating which algorithm ends up superseding others: e.g., we find merely varying context size or amount of training yields (at times sharp) transitions between which algorithm dictates the model behavior, revealing a mechanism that explains the transient nature of ICL. In this sense, we argue ICL is best thought of as a mixture of different algorithms, each with its own peculiarities, instead of a monolithic capability. This also implies that making general claims about ICL that hold universally across all settings may be infeasible.