 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-OT Flow: Estimating Continuous-Time Dynamics from Discrete Temporal Snapshots
May 23, 2025In many real-world scenarios, such as single-cell RNA sequencing, data are observed only as discrete-time snapshots spanning finite time intervals and subject to noisy timestamps, with no continuous trajectories available. Recovering the underlying continuous-time dynamics from these snapshots with coarse and noisy observation times is a critical and challenging task. We propose Continuous-Time Optimal Transport Flow (CT-OT Flow), which first infers high-resolution time labels via partial optimal transport and then reconstructs a continuous-time data distribution through a temporal kernel smoothing. This reconstruction enables accurate training of dynamics models such as ODEs and SDEs. CT-OT Flow consistently outperforms state-of-the-art methods on synthetic benchmarks and achieves lower reconstruction errors on real scRNA-seq and typhoon-track datasets. Our results highlight the benefits of explicitly modeling temporal discretization and timestamp uncertainty, offering an accurate and general framework for bridging discrete snapshots and continuous-time processes.
One-Shot Domain Incremental Learning
Mar 25, 2024



Domain incremental learning (DIL) has been discussed in previous studies on deep neural network models for classification. In DIL, we assume that samples on new domains are observed over time. The models must classify inputs on all domains. In practice, however, we may encounter a situation where we need to perform DIL under the constraint that the samples on the new domain are observed only infrequently. Therefore, in this study, we consider the extreme case where we have only one sample from the new domain, which we call one-shot DIL. We first empirically show that existing DIL methods do not work well in one-shot DIL. We have analyzed the reason for this failure through various investigations. According to our analysis, we clarify that the difficulty of one-shot DIL is caused by the statistics in the batch normalization layers. Therefore, we propose a technique regarding these statistics and demonstrate the effectiveness of our technique through experiments on open datasets.
Accuracy-Preserving Calibration via Statistical Modeling on Probability Simplex
Feb 21, 2024Classification models based on deep neural networks (DNNs) must be calibrated to measure the reliability of predictions. Some recent calibration methods have employed a probabilistic model on the probability simplex. However, these calibration methods cannot preserve the accuracy of pre-trained models, even those with a high classification accuracy. We propose an accuracy-preserving calibration method using the Concrete distribution as the probabilistic model on the probability simplex. We theoretically prove that a DNN model trained on cross-entropy loss has optimality as the parameter of the Concrete distribution. We also propose an efficient method that synthetically generates samples for training probabilistic models on the probability simplex. We demonstrate that the proposed method can outperform previous methods in accuracy-preserving calibration tasks using benchmarks.
StyleDiff: Attribute Comparison Between Unlabeled Datasets in Latent Disentangled Space
Mar 09, 2023One major challenge in machine learning applications is coping with mismatches between the datasets used in the development and those obtained in real-world applications. These mismatches may lead to inaccurate predictions and errors, resulting in poor product quality and unreliable systems. In this study, we propose StyleDiff to inform developers of the differences between the two datasets for the steady development of machine learning systems. Using disentangled image spaces obtained from recently proposed generative models, StyleDiff compares the two datasets by focusing on attributes in the images and provides an easy-to-understand analysis of the differences between the datasets. The proposed StyleDiff performs in $O (d N\log N)$, where $N$ is the size of the datasets and $d$ is the number of attributes, enabling the application to large datasets. We demonstrate that StyleDiff accurately detects differences between datasets and presents them in an understandable format using, for example, driving scenes datasets.
Theoretical Analysis of the Advantage of Deepening Neural Networks
Sep 24, 2020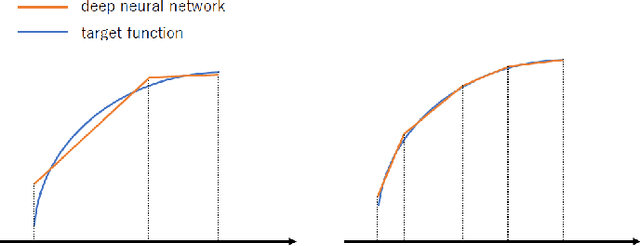
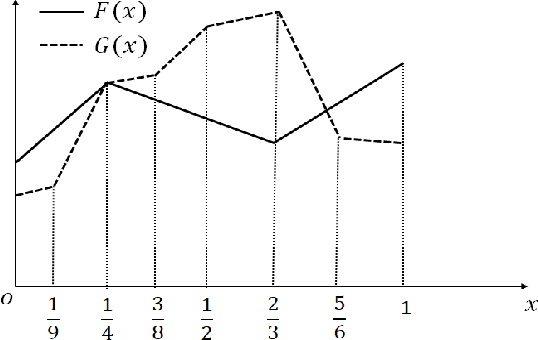
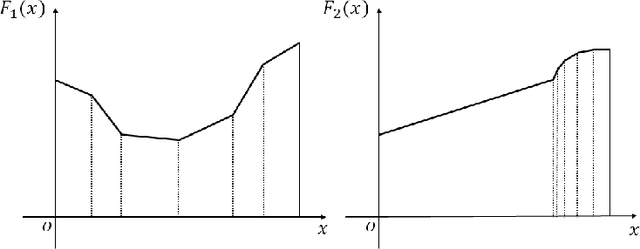
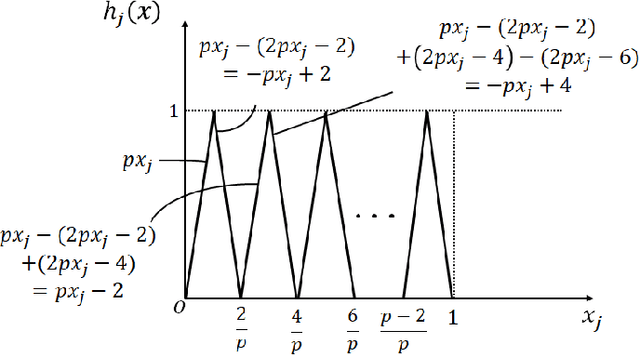
We propose two new criteria to understand the advantage of deepening neural networks. It is important to know the expressivity of functions computable by deep neural networks in order to understand the advantage of deepening neural networks. Unless deep neural networks have enough expressivity, they cannot have good performance even though learning is successful. In this situation, the proposed criteria contribute to understanding the advantage of deepening neural networks since they can evaluate the expressivity independently from the efficiency of learning. The first criterion shows the approximation accuracy of deep neural networks to the target function. This criterion has the background that the goal of deep learning is approximating the target function by deep neural networks. The second criterion shows the property of linear regions of functions computable by deep neural networks. This criterion has the background that deep neural networks whose activation functions are piecewise linear are also piecewise linear. Furthermore, by the two criteria, we show that to increase layers is more effective than to increase units at each layer on improving the expressivity of deep neural networks.