 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy-Preserving Calibration via Statistical Modeling on Probability Simplex
Feb 21, 2024Classification models based on deep neural networks (DNNs) must be calibrated to measure the reliability of predictions. Some recent calibration methods have employed a probabilistic model on the probability simplex. However, these calibration methods cannot preserve the accuracy of pre-trained models, even those with a high classification accuracy. We propose an accuracy-preserving calibration method using the Concrete distribution as the probabilistic model on the probability simplex. We theoretically prove that a DNN model trained on cross-entropy loss has optimality as the parameter of the Concrete distribution. We also propose an efficient method that synthetically generates samples for training probabilistic models on the probability simplex. We demonstrate that the proposed method can outperform previous methods in accuracy-preserving calibration tasks using benchmarks.
StyleDiff: Attribute Comparison Between Unlabeled Datasets in Latent Disentangled Space
Mar 09, 2023One major challenge in machine learning applications is coping with mismatches between the datasets used in the development and those obtained in real-world applications. These mismatches may lead to inaccurate predictions and errors, resulting in poor product quality and unreliable systems. In this study, we propose StyleDiff to inform developers of the differences between the two datasets for the steady development of machine learning systems. Using disentangled image spaces obtained from recently proposed generative models, StyleDiff compares the two datasets by focusing on attributes in the images and provides an easy-to-understand analysis of the differences between the datasets. The proposed StyleDiff performs in $O (d N\log N)$, where $N$ is the size of the datasets and $d$ is the number of attributes, enabling the application to large datasets. We demonstrate that StyleDiff accurately detects differences between datasets and presents them in an understandable format using, for example, driving scenes datasets.
Revisiting Fine-tuning for Few-shot Learning
Oct 03, 2019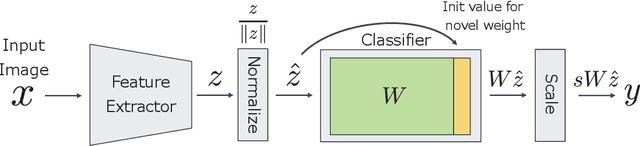
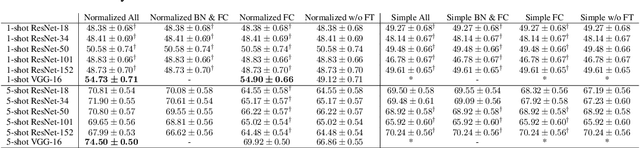
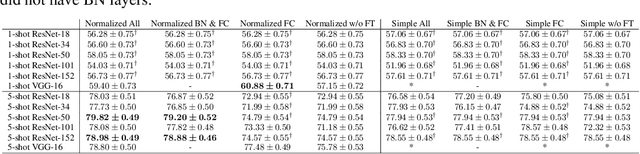
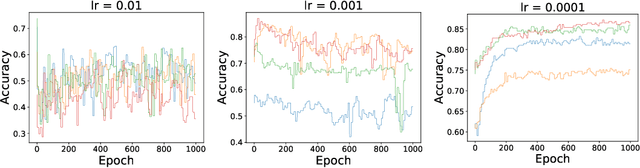
Few-shot learning is the process of learning novel classes using only a few examples and it remains a challenging task in machine learning. Many sophisticated few-shot learning algorithms have been proposed based on the notion that networks can easily overfit to novel examples if they are simply fine-tuned using only a few examples. In this study, we show that in the commonly used low-resolution mini-ImageNet dataset, the fine-tuning method achieves higher accuracy than common few-shot learning algorithms in the 1-shot task and nearly the same accuracy as that of the state-of-the-art algorithm in the 5-shot task. We then evaluate our method with more practical tasks, namely the high-resolution single-domain and cross-domain tasks. With both tasks, we show that our method achieves higher accuracy than common few-shot learning algorithms. We further analyze the experimental results and show that: 1) the retraining process can be stabilized by employing a low learning rate, 2) using adaptive gradient optimizers during fine-tuning can increase test accuracy, and 3) test accuracy can be improved by updating the entire network when a large domain-shift exists between base and novel classes.
Noise-Level Estimation from Single Color Image Using Correlations Between Textures in RGB Channels
Apr 04, 2019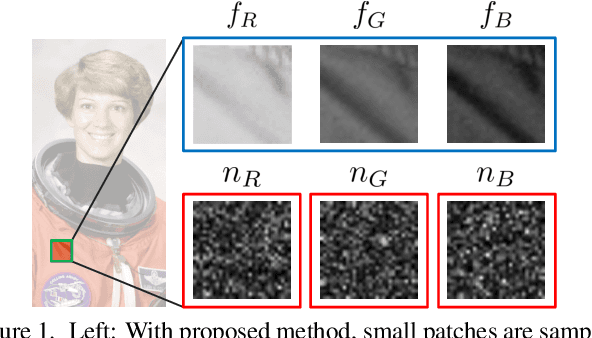
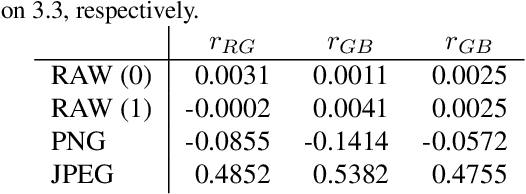
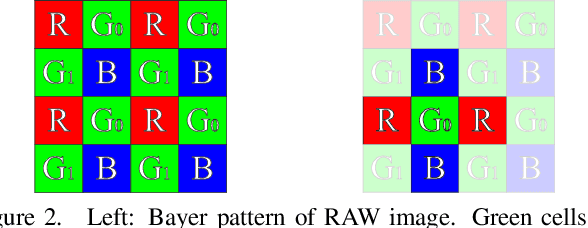

We propose a simple method for estimating noise level from a single color image. In most image-denoising algorithms, an accurate noise-level estimate results in good denoising performance; however, it is difficult to estimate noise level from a single image because it is an ill-posed problem. We tackle this problem by using prior knowledge that textures are highly correlated between RGB channels and noise is uncorrelated to other signals. We also extended our method for RAW images because they are available in almost all digital cameras and often used in practical situations. Experiments show the high noise-estimation performance of our method in synthetic noisy images. We also applied our method to natural images including RAW images and achieved better noise-estimation performance than conventional methods.