 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Fine-tuning for Few-shot Learning
Paper and Code
Oct 03, 2019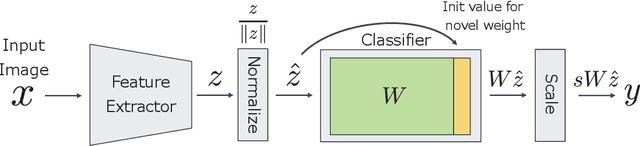
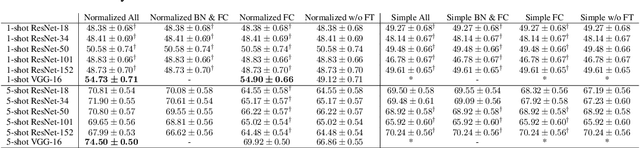
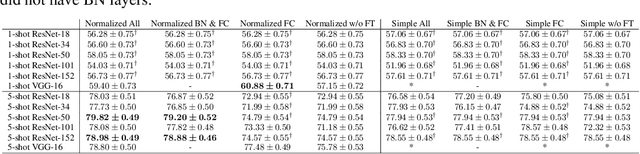
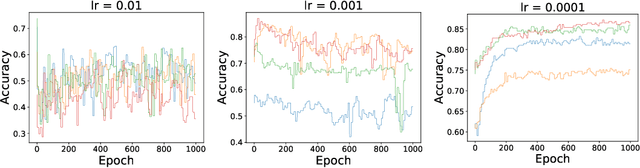
Few-shot learning is the process of learning novel classes using only a few examples and it remains a challenging task in machine learning. Many sophisticated few-shot learning algorithms have been proposed based on the notion that networks can easily overfit to novel examples if they are simply fine-tuned using only a few examples. In this study, we show that in the commonly used low-resolution mini-ImageNet dataset, the fine-tuning method achieves higher accuracy than common few-shot learning algorithms in the 1-shot task and nearly the same accuracy as that of the state-of-the-art algorithm in the 5-shot task. We then evaluate our method with more practical tasks, namely the high-resolution single-domain and cross-domain tasks. With both tasks, we show that our method achieves higher accuracy than common few-shot learning algorithms. We further analyze the experimental results and show that: 1) the retraining process can be stabilized by employing a low learning rate, 2) using adaptive gradient optimizers during fine-tuning can increase test accuracy, and 3) test accuracy can be improved by updating the entire network when a large domain-shift exists between base and novel classes.