 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Prior Diffusion: A Probabilistic Framework Integrating Coarse Latent Priors with Diffusion Models
Dec 25, 2025



Diffusion models have become a central tool in deep generative modeling, but standard formulations rely on a single network and a single diffusion schedule to transform a simple prior, typically a standard normal distribution, into the target data distribution. As a result, the model must simultaneously represent the global structure of the distribution and its fine-scale local variations, which becomes difficult when these scales are strongly mismatched. This issue arises both in natural images, where coarse manifold-level structure and fine textures coexist, and in low-dimensional distributions with highly concentrated local structure. To address this issue, we propose Residual Prior Diffusion (RPD), a two-stage framework in which a coarse prior model first captures the large-scale structure of the data distribution, and a diffusion model is then trained to represent the residual between the prior and the target data distribution. We formulate RPD as an explicit probabilistic model with a tractable evidence lower bound, whose optimization reduces to the familiar objectives of noise prediction or velocity prediction. We further introduce auxiliary variables that leverage information from the prior model and theoretically analyze how they reduce the difficulty of the prediction problem in RPD. Experiments on synthetic datasets with fine-grained local structure show that standard diffusion models fail to capture local details, whereas RPD accurately captures fine-scale detail while preserving the large-scale structure of the distribution. On natural image generation tasks, RPD achieved generation quality that matched or exceeded that of representative diffusion-based baselines and it maintained strong performance even with a small number of inference steps.
CT-OT Flow: Estimating Continuous-Time Dynamics from Discrete Temporal Snapshots
May 23, 2025In many real-world scenarios, such as single-cell RNA sequencing, data are observed only as discrete-time snapshots spanning finite time intervals and subject to noisy timestamps, with no continuous trajectories available. Recovering the underlying continuous-time dynamics from these snapshots with coarse and noisy observation times is a critical and challenging task. We propose Continuous-Time Optimal Transport Flow (CT-OT Flow), which first infers high-resolution time labels via partial optimal transport and then reconstructs a continuous-time data distribution through a temporal kernel smoothing. This reconstruction enables accurate training of dynamics models such as ODEs and SDEs. CT-OT Flow consistently outperforms state-of-the-art methods on synthetic benchmarks and achieves lower reconstruction errors on real scRNA-seq and typhoon-track datasets. Our results highlight the benefits of explicitly modeling temporal discretization and timestamp uncertainty, offering an accurate and general framework for bridging discrete snapshots and continuous-time processes.
An Asymptotic Equation Linking WAIC and WBIC in Singular Models
May 21, 2025In statistical learning, models are classified as regular or singular depending on whether the mapping from parameters to probability distributions is injective. Most models with hierarchical structures or latent variables are singular, for which conventional criteria such as the Akaike Information Criterion and the Bayesian Information Criterion are inapplicable due to the breakdown of normal approximations for the likelihood and posterior. To address this, the Widely Applicable Information Criterion (WAIC) and the Widely Applicable Bayesian Information Criterion (WBIC) have been proposed. Since WAIC and WBIC are computed using posterior distributions at different temperature settings, separate posterior sampling is generally required. In this paper, we theoretically derive an asymptotic equation that links WAIC and WBIC, despite their dependence on different posteriors. This equation yields an asymptotically unbiased expression of WAIC in terms of the posterior distribution used for WBIC. The result clarifies the structural relationship between these criteria within the framework of singular learning theory, and deepens understanding of their asymptotic behavior. This theoretical contribution provides a foundation for future developments in the computational efficiency of model selection in singular models.
Generalized Diffusion Model with Adjusted Offset Noise
Dec 04, 2024Diffusion models have become fundamental tools for modeling data distributions in machine learning and have applications in image generation, drug discovery, and audio synthesis. Despite their success, these models face challenges when generating data with extreme brightness values, as evidenced by limitations in widely used frameworks like Stable Diffusion. Offset noise has been proposed as an empirical solution to this issue, yet its theoretical basis remains insufficiently explored. In this paper, we propose a generalized diffusion model that naturally incorporates additional noise within a rigorous probabilistic framework. Our approach modifies both the forward and reverse diffusion processes, enabling inputs to be diffused into Gaussian distributions with arbitrary mean structures. We derive a loss function based on the evidence lower bound, establishing its theoretical equivalence to offset noise with certain adjustments, while broadening its applicability. Experiments on synthetic datasets demonstrate that our model effectively addresses brightness-related challenges and outperforms conventional methods in high-dimensional scenarios.
One-Shot Domain Incremental Learning
Mar 25, 2024



Domain incremental learning (DIL) has been discussed in previous studies on deep neural network models for classification. In DIL, we assume that samples on new domains are observed over time. The models must classify inputs on all domains. In practice, however, we may encounter a situation where we need to perform DIL under the constraint that the samples on the new domain are observed only infrequently. Therefore, in this study, we consider the extreme case where we have only one sample from the new domain, which we call one-shot DIL. We first empirically show that existing DIL methods do not work well in one-shot DIL. We have analyzed the reason for this failure through various investigations. According to our analysis, we clarify that the difficulty of one-shot DIL is caused by the statistics in the batch normalization layers. Therefore, we propose a technique regarding these statistics and demonstrate the effectiveness of our technique through experiments on open datasets.
Accuracy-Preserving Calibration via Statistical Modeling on Probability Simplex
Feb 21, 2024Classification models based on deep neural networks (DNNs) must be calibrated to measure the reliability of predictions. Some recent calibration methods have employed a probabilistic model on the probability simplex. However, these calibration methods cannot preserve the accuracy of pre-trained models, even those with a high classification accuracy. We propose an accuracy-preserving calibration method using the Concrete distribution as the probabilistic model on the probability simplex. We theoretically prove that a DNN model trained on cross-entropy loss has optimality as the parameter of the Concrete distribution. We also propose an efficient method that synthetically generates samples for training probabilistic models on the probability simplex. We demonstrate that the proposed method can outperform previous methods in accuracy-preserving calibration tasks using benchmarks.
How many views does your deep neural network use for prediction?
Feb 02, 2024



The generalization ability of Deep Neural Networks (DNNs) is still not fully understood, despite numerous theoretical and empirical analyses. Recently, Allen-Zhu & Li (2023) introduced the concept of multi-views to explain the generalization ability of DNNs, but their main target is ensemble or distilled models, and no method for estimating multi-views used in a prediction of a specific input is discussed. In this paper, we propose Minimal Sufficient Views (MSVs), which is similar to multi-views but can be efficiently computed for real images. MSVs is a set of minimal and distinct features in an input, each of which preserves a model's prediction for the input. We empirically show that there is a clear relationship between the number of MSVs and prediction accuracy across models, including convolutional and transformer models, suggesting that a multi-view like perspective is also important for understanding the generalization ability of (non-ensemble or non-distilled) DNNs.
Supervised Contrastive Learning with Heterogeneous Similarity for Distribution Shifts
Apr 07, 2023Distribution shifts are problems where the distribution of data changes between training and testing, which can significantly degrade the performance of a model deployed in the real world. Recent studies suggest that one reason for the degradation is a type of overfitting, and that proper regularization can mitigate the degradation, especially when using highly representative models such as neural networks. In this paper, we propose a new regularization using the supervised contrastive learning to prevent such overfitting and to train models that do not degrade their performance under the distribution shifts. We extend the cosine similarity in contrastive loss to a more general similarity measure and propose to use different parameters in the measure when comparing a sample to a positive or negative example, which is analytically shown to act as a kind of margin in contrastive loss. Experiments on benchmark datasets that emulate distribution shifts, including subpopulation shift and domain generalization, demonstrate the advantage of the proposed method over existing regularization methods.
StyleDiff: Attribute Comparison Between Unlabeled Datasets in Latent Disentangled Space
Mar 09, 2023One major challenge in machine learning applications is coping with mismatches between the datasets used in the development and those obtained in real-world applications. These mismatches may lead to inaccurate predictions and errors, resulting in poor product quality and unreliable systems. In this study, we propose StyleDiff to inform developers of the differences between the two datasets for the steady development of machine learning systems. Using disentangled image spaces obtained from recently proposed generative models, StyleDiff compares the two datasets by focusing on attributes in the images and provides an easy-to-understand analysis of the differences between the datasets. The proposed StyleDiff performs in $O (d N\log N)$, where $N$ is the size of the datasets and $d$ is the number of attributes, enabling the application to large datasets. We demonstrate that StyleDiff accurately detects differences between datasets and presents them in an understandable format using, for example, driving scenes datasets.
Neural Time Warping For Multiple Sequence Alignment
Jun 29, 2020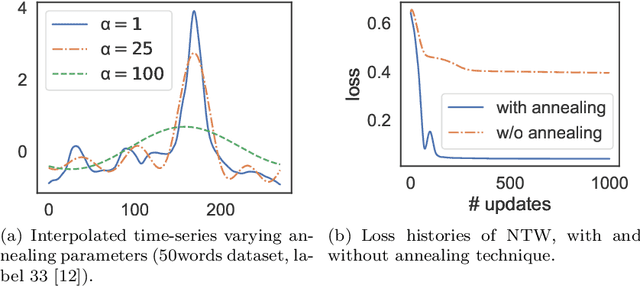
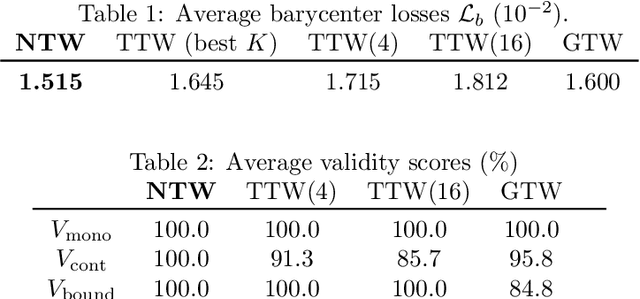
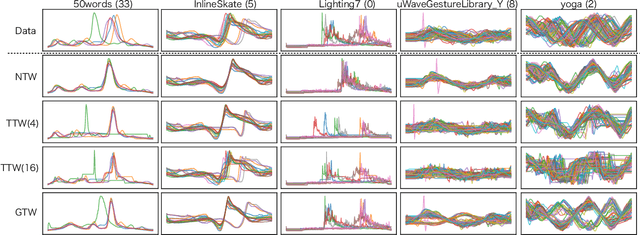
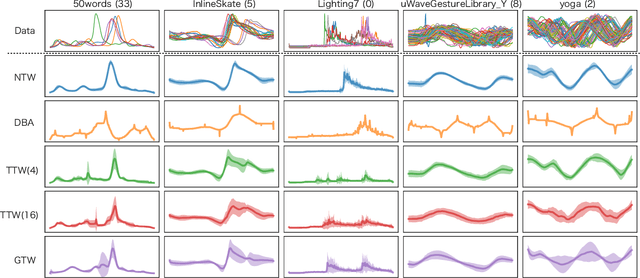
Multiple sequences alignment (MSA) is a traditional and challenging task for time-series analyses. The MSA problem is formulated as a discrete optimization problem and is typically solved by dynamic programming. However, the computational complexity increases exponentially with respect to the number of input sequences. In this paper, we propose neural time warping (NTW) that relaxes the original MSA to a continuous optimization and obtains the alignments using a neural network. The solution obtained by NTW is guaranteed to be a feasible solution for the original discrete optimization problem under mild conditions. Our experimental results show that NTW successfully aligns a hundred time-series and significantly outperforms existing methods for solving the MSA problem. In addition, we show a method for obtaining average time-series data as one of applications of NTW. Compared to the existing barycenters, the mean time series data retains the features of the input time-series data.