 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning the Preferences of a Learning Agent
May 09, 2026For AI systems to be useful to humans, they must understand and act in accordance with our values and preferences. Since specifying preferences is a hard task, inverse reinforcement learning (IRL) aims to develop methods that allow for inferring preferences from observed behavior. However, IRL assumes the human to be approximately optimal. This is a big limitation in cases where the human themselves may be learning to act optimally in an environment. In this paper, we formalize the problem of learning the preferences of a learning agent: a predictor observes a learner acting online and tries to infer the underlying reward function being (initially suboptimally) optimized by the learner. We model the learner as either being no-regret, or as converging to an optimal Boltzmann policy over time. In each of these settings, we establish theoretical guarantees for various preference learning algorithms, or otherwise show that such guarantees are impossible.
Continuous-Time Analysis of Adaptive Optimization and Normalization
Nov 08, 2024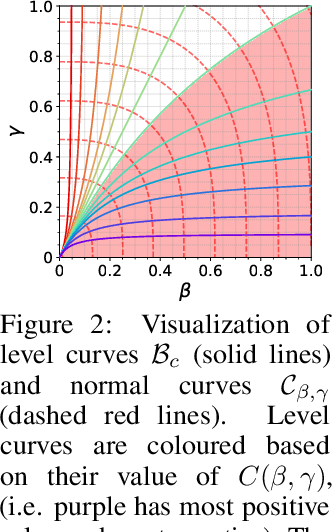
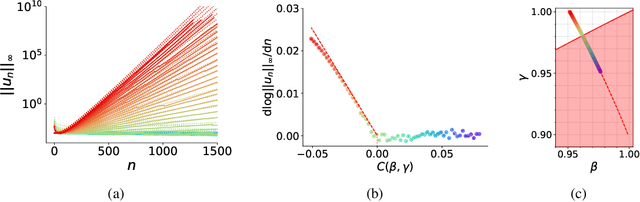
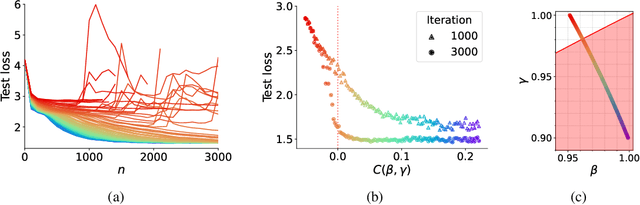
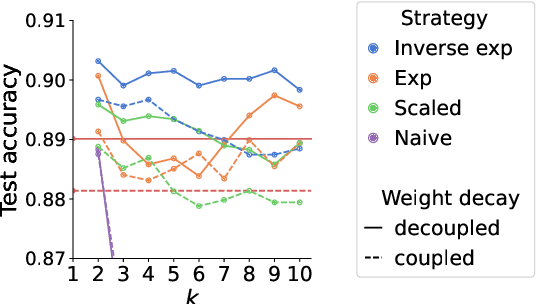
Adaptive optimization algorithms, particularly Adam and its variant AdamW, are fundamental components of modern deep learning. However, their training dynamics lack comprehensive theoretical understanding, with limited insight into why common practices - such as specific hyperparameter choices and normalization layers - contribute to successful generalization. This work presents a continuous-time formulation of Adam and AdamW, facilitating a tractable analysis of training dynamics that can shed light on such practical questions. We theoretically derive a stable region for Adam's hyperparameters $(\beta, \gamma)$ that ensures bounded updates, empirically verifying these predictions by observing unstable exponential growth of parameter updates outside this region. Furthermore, we theoretically justify the success of normalization layers by uncovering an implicit meta-adaptive effect of scale-invariant architectural components. This insight leads to an explicit optimizer, $2$-Adam, which we generalize to $k$-Adam - an optimizer that applies an adaptive normalization procedure $k$ times, encompassing Adam (corresponding to $k=1$) and Adam with a normalization layer (corresponding to $k=2$). Overall, our continuous-time formulation of Adam facilitates a principled analysis, offering deeper understanding of optimal hyperparameter choices and architectural decisions in modern deep learning.
Successor Heads: Recurring, Interpretable Attention Heads In The Wild
Dec 14, 2023In this work we present successor heads: attention heads that increment tokens with a natural ordering, such as numbers, months, and days. For example, successor heads increment 'Monday' into 'Tuesday'. We explain the successor head behavior with an approach rooted in mechanistic interpretability, the field that aims to explain how models complete tasks in human-understandable terms. Existing research in this area has found interpretable language model components in small toy models. However, results in toy models have not yet led to insights that explain the internals of frontier models and little is currently understood about the internal operations of large language models. In this paper, we analyze the behavior of successor heads in large language models (LLMs) and find that they implement abstract representations that are common to different architectures. They form in LLMs with as few as 31 million parameters, and at least as many as 12 billion parameters, such as GPT-2, Pythia, and Llama-2. We find a set of 'mod-10 features' that underlie how successor heads increment in LLMs across different architectures and sizes. We perform vector arithmetic with these features to edit head behavior and provide insights into numeric representations within LLMs. Additionally, we study the behavior of successor heads on natural language data, identifying interpretable polysemanticity in a Pythia successor head.