 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel Interpretability Of Artificial Neural Networks: Leveraging Framework And Methods From Neuroscience
Aug 26, 2024
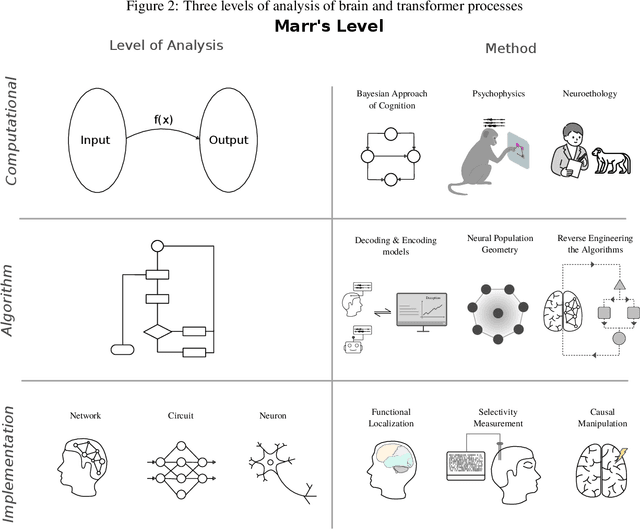
As deep learning systems are scaled up to many billions of parameters, relating their internal structure to external behaviors becomes very challenging. Although daunting, this problem is not new: Neuroscientists and cognitive scientists have accumulated decades of experience analyzing a particularly complex system - the brain. In this work, we argue that interpreting both biological and artificial neural systems requires analyzing those systems at multiple levels of analysis, with different analytic tools for each level. We first lay out a joint grand challenge among scientists who study the brain and who study artificial neural networks: understanding how distributed neural mechanisms give rise to complex cognition and behavior. We then present a series of analytical tools that can be used to analyze biological and artificial neural systems, organizing those tools according to Marr's three levels of analysis: computation/behavior, algorithm/representation, and implementation. Overall, the multilevel interpretability framework provides a principled way to tackle neural system complexity; links structure, computation, and behavior; clarifies assumptions and research priorities at each level; and paves the way toward a unified effort for understanding intelligent systems, may they be biological or artificial.
Successor Heads: Recurring, Interpretable Attention Heads In The Wild
Dec 14, 2023In this work we present successor heads: attention heads that increment tokens with a natural ordering, such as numbers, months, and days. For example, successor heads increment 'Monday' into 'Tuesday'. We explain the successor head behavior with an approach rooted in mechanistic interpretability, the field that aims to explain how models complete tasks in human-understandable terms. Existing research in this area has found interpretable language model components in small toy models. However, results in toy models have not yet led to insights that explain the internals of frontier models and little is currently understood about the internal operations of large language models. In this paper, we analyze the behavior of successor heads in large language models (LLMs) and find that they implement abstract representations that are common to different architectures. They form in LLMs with as few as 31 million parameters, and at least as many as 12 billion parameters, such as GPT-2, Pythia, and Llama-2. We find a set of 'mod-10 features' that underlie how successor heads increment in LLMs across different architectures and sizes. We perform vector arithmetic with these features to edit head behavior and provide insights into numeric representations within LLMs. Additionally, we study the behavior of successor heads on natural language data, identifying interpretable polysemanticity in a Pythia successor head.