 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Models Manipulate Manifolds: The Geometry of a Counting Task
Jan 08, 2026Language models can perceive visual properties of text despite receiving only sequences of tokens-we mechanistically investigate how Claude 3.5 Haiku accomplishes one such task: linebreaking in fixed-width text. We find that character counts are represented on low-dimensional curved manifolds discretized by sparse feature families, analogous to biological place cells. Accurate predictions emerge from a sequence of geometric transformations: token lengths are accumulated into character count manifolds, attention heads twist these manifolds to estimate distance to the line boundary, and the decision to break the line is enabled by arranging estimates orthogonally to create a linear decision boundary. We validate our findings through causal interventions and discover visual illusions--character sequences that hijack the counting mechanism. Our work demonstrates the rich sensory processing of early layers, the intricacy of attention algorithms, and the importance of combining feature-based and geometric views of interpretability.
Multilevel Interpretability Of Artificial Neural Networks: Leveraging Framework And Methods From Neuroscience
Aug 26, 2024
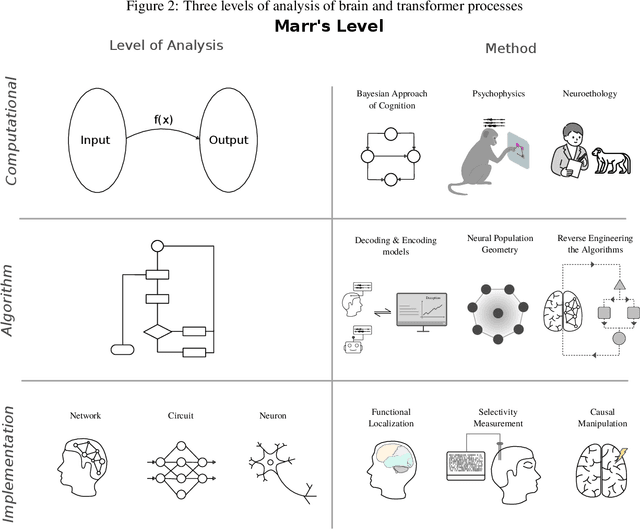
As deep learning systems are scaled up to many billions of parameters, relating their internal structure to external behaviors becomes very challenging. Although daunting, this problem is not new: Neuroscientists and cognitive scientists have accumulated decades of experience analyzing a particularly complex system - the brain. In this work, we argue that interpreting both biological and artificial neural systems requires analyzing those systems at multiple levels of analysis, with different analytic tools for each level. We first lay out a joint grand challenge among scientists who study the brain and who study artificial neural networks: understanding how distributed neural mechanisms give rise to complex cognition and behavior. We then present a series of analytical tools that can be used to analyze biological and artificial neural systems, organizing those tools according to Marr's three levels of analysis: computation/behavior, algorithm/representation, and implementation. Overall, the multilevel interpretability framework provides a principled way to tackle neural system complexity; links structure, computation, and behavior; clarifies assumptions and research priorities at each level; and paves the way toward a unified effort for understanding intelligent systems, may they be biological or artificial.
The Remarkable Robustness of LLMs: Stages of Inference?
Jun 27, 2024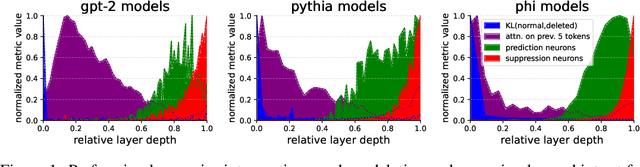
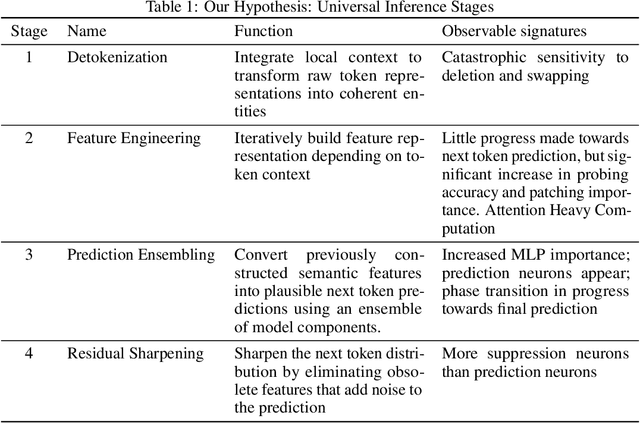
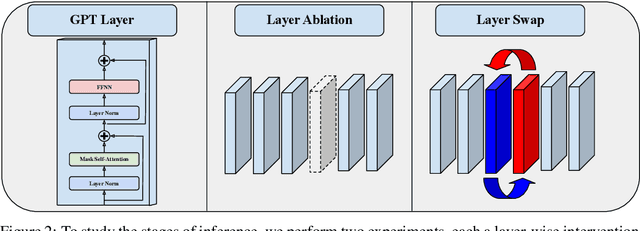

We demonstrate and investigate the remarkable robustness of Large Language Models by deleting and swapping adjacent layers. We find that deleting and swapping interventions retain 72-95\% of the original model's prediction accuracy without fine-tuning, whereas models with more layers exhibit more robustness. Based on the results of the layer-wise intervention and further experiments, we hypothesize the existence of four universal stages of inference across eight different models: detokenization, feature engineering, prediction ensembling, and residual sharpening. The first stage integrates local information, lifting raw token representations into higher-level contextual representations. Next is the iterative refinement of task and entity-specific features. Then, the second half of the model begins with a phase transition, where hidden representations align more with the vocabulary space due to specialized model components. Finally, the last layer sharpens the following token distribution by eliminating obsolete features that add noise to the prediction.
Confidence Regulation Neurons in Language Models
Jun 24, 2024Despite their widespread use, the mechanisms by which large language models (LLMs) represent and regulate uncertainty in next-token predictions remain largely unexplored. This study investigates two critical components believed to influence this uncertainty: the recently discovered entropy neurons and a new set of components that we term token frequency neurons. Entropy neurons are characterized by an unusually high weight norm and influence the final layer normalization (LayerNorm) scale to effectively scale down the logits. Our work shows that entropy neurons operate by writing onto an unembedding null space, allowing them to impact the residual stream norm with minimal direct effect on the logits themselves. We observe the presence of entropy neurons across a range of models, up to 7 billion parameters. On the other hand, token frequency neurons, which we discover and describe here for the first time, boost or suppress each token's logit proportionally to its log frequency, thereby shifting the output distribution towards or away from the unigram distribution. Finally, we present a detailed case study where entropy neurons actively manage confidence in the setting of induction, i.e. detecting and continuing repeated subsequences.
Refusal in Language Models Is Mediated by a Single Direction
Jun 17, 2024



Conversational large language models are fine-tuned for both instruction-following and safety, resulting in models that obey benign requests but refuse harmful ones. While this refusal behavior is widespread across chat models, its underlying mechanisms remain poorly understood. In this work, we show that refusal is mediated by a one-dimensional subspace, across 13 popular open-source chat models up to 72B parameters in size. Specifically, for each model, we find a single direction such that erasing this direction from the model's residual stream activations prevents it from refusing harmful instructions, while adding this direction elicits refusal on even harmless instructions. Leveraging this insight, we propose a novel white-box jailbreak method that surgically disables refusal with minimal effect on other capabilities. Finally, we mechanistically analyze how adversarial suffixes suppress propagation of the refusal-mediating direction. Our findings underscore the brittleness of current safety fine-tuning methods. More broadly, our work showcases how an understanding of model internals can be leveraged to develop practical methods for controlling model behavior.
Not All Language Model Features Are Linear
May 23, 2024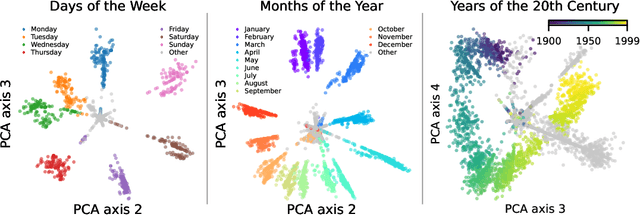
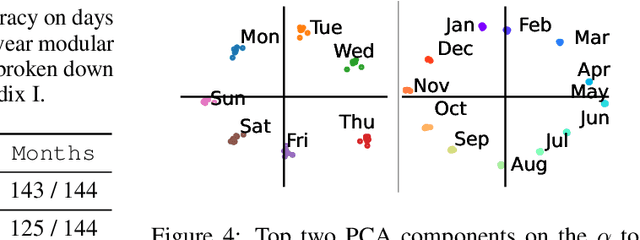
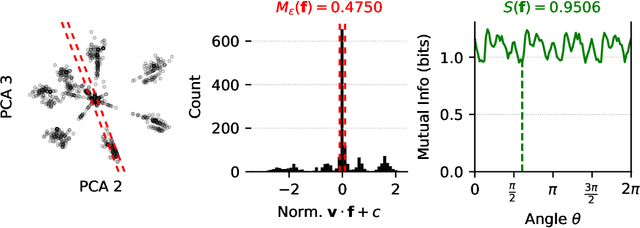
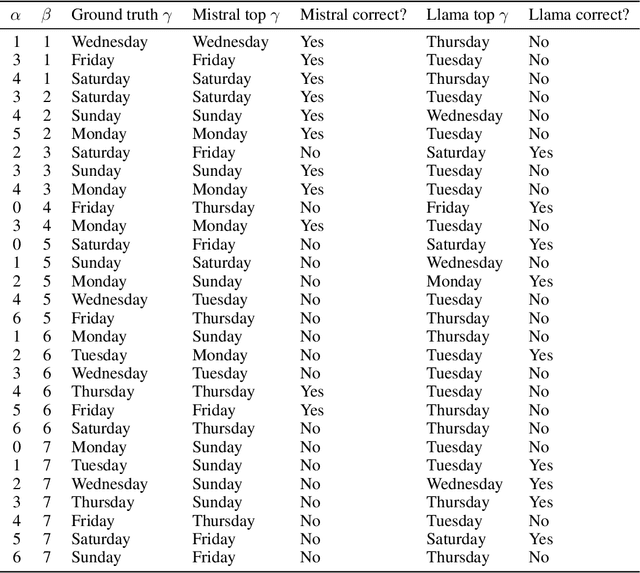
Recent work has proposed the linear representation hypothesis: that language models perform computation by manipulating one-dimensional representations of concepts ("features") in activation space. In contrast, we explore whether some language model representations may be inherently multi-dimensional. We begin by developing a rigorous definition of irreducible multi-dimensional features based on whether they can be decomposed into either independent or non-co-occurring lower-dimensional features. Motivated by these definitions, we design a scalable method that uses sparse autoencoders to automatically find multi-dimensional features in GPT-2 and Mistral 7B. These auto-discovered features include strikingly interpretable examples, e.g. circular features representing days of the week and months of the year. We identify tasks where these exact circles are used to solve computational problems involving modular arithmetic in days of the week and months of the year. Finally, we provide evidence that these circular features are indeed the fundamental unit of computation in these tasks with intervention experiments on Mistral 7B and Llama 3 8B, and we find further circular representations by breaking down the hidden states for these tasks into interpretable components.
Universal Neurons in GPT2 Language Models
Jan 22, 2024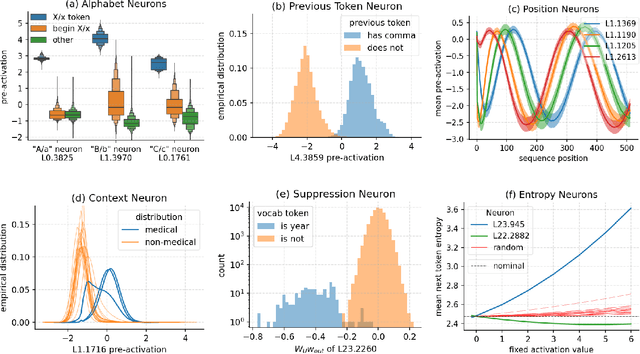
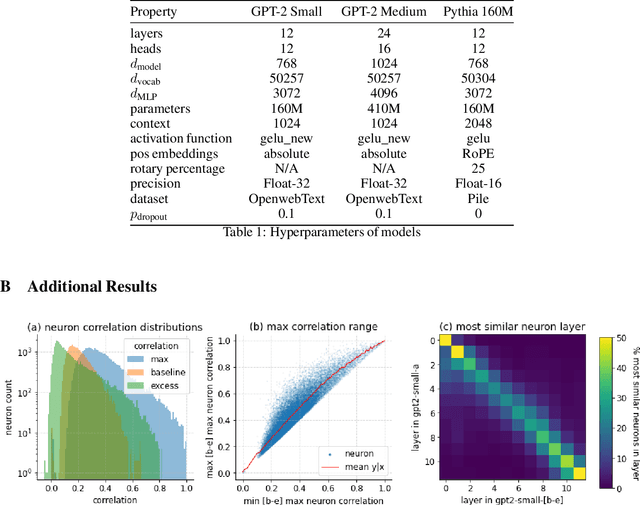
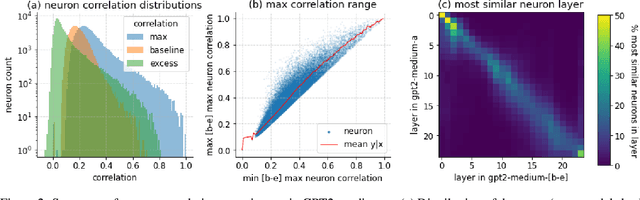
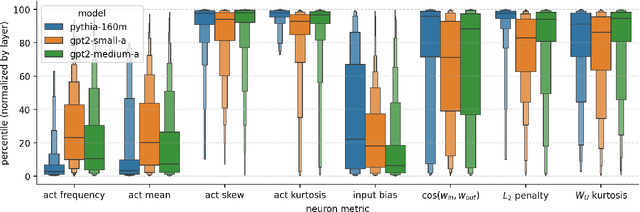
A basic question within the emerging field of mechanistic interpretability is the degree to which neural networks learn the same underlying mechanisms. In other words, are neural mechanisms universal across different models? In this work, we study the universality of individual neurons across GPT2 models trained from different initial random seeds, motivated by the hypothesis that universal neurons are likely to be interpretable. In particular, we compute pairwise correlations of neuron activations over 100 million tokens for every neuron pair across five different seeds and find that 1-5\% of neurons are universal, that is, pairs of neurons which consistently activate on the same inputs. We then study these universal neurons in detail, finding that they usually have clear interpretations and taxonomize them into a small number of neuron families. We conclude by studying patterns in neuron weights to establish several universal functional roles of neurons in simple circuits: deactivating attention heads, changing the entropy of the next token distribution, and predicting the next token to (not) be within a particular set.
Training Dynamics of Contextual N-Grams in Language Models
Nov 01, 2023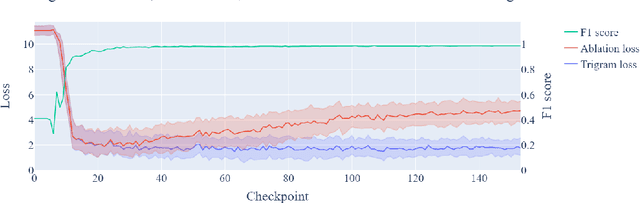
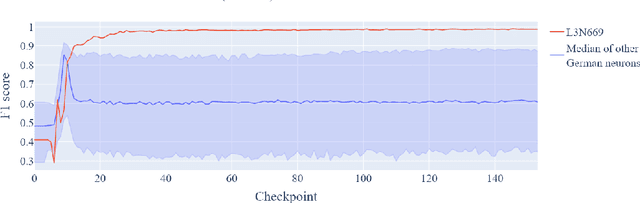
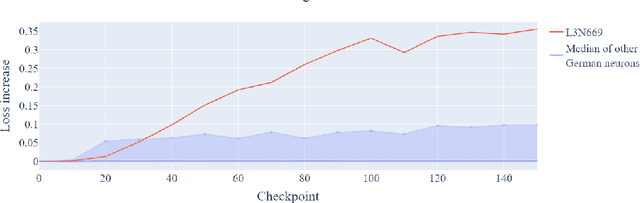
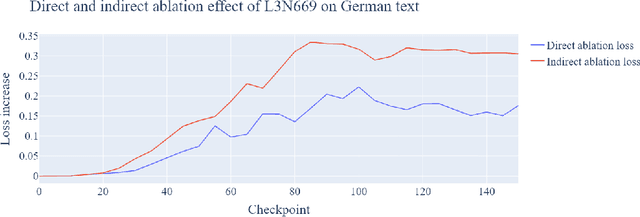
Prior work has shown the existence of contextual neurons in language models, including a neuron that activates on German text. We show that this neuron exists within a broader contextual n-gram circuit: we find late layer neurons which recognize and continue n-grams common in German text, but which only activate if the German neuron is active. We investigate the formation of this circuit throughout training and find that it is an example of what we call a second-order circuit. In particular, both the constituent n-gram circuits and the German detection circuit which culminates in the German neuron form with independent functions early in training - the German detection circuit partially through modeling German unigram statistics, and the n-grams by boosting appropriate completions. Only after both circuits have already formed do they fit together into a second-order circuit. Contrary to the hypotheses presented in prior work, we find that the contextual n-gram circuit forms gradually rather than in a sudden phase transition. We further present a range of anomalous observations such as a simultaneous phase transition in many tasks coinciding with the learning rate warm-up, and evidence that many context neurons form simultaneously early in training but are later unlearned.
Language Models Represent Space and Time
Oct 03, 2023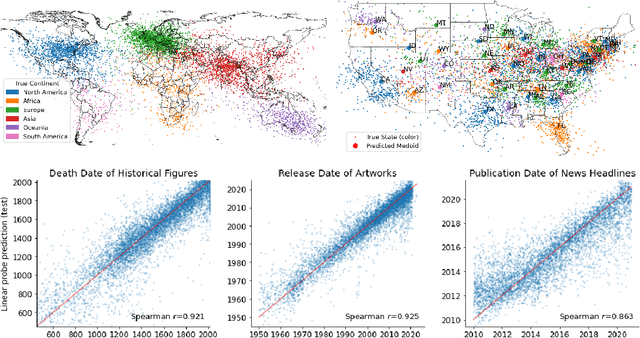
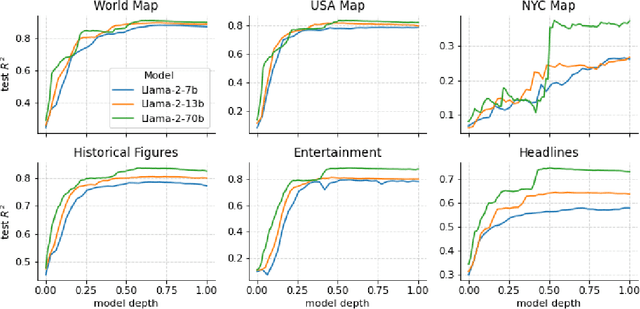
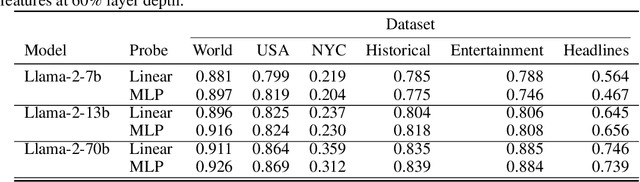
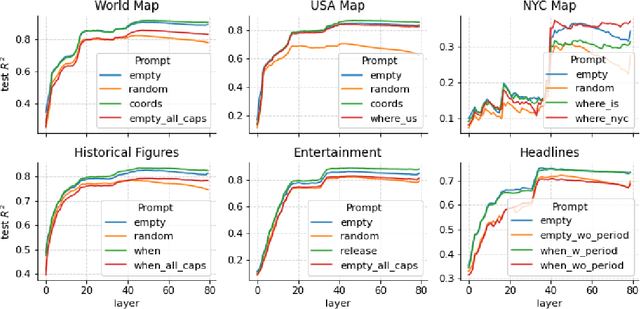
The capabilities of large language models (LLMs) have sparked debate over whether such systems just learn an enormous collection of superficial statistics or a coherent model of the data generating process -- a world model. We find evidence for the latter by analyzing the learned representations of three spatial datasets (world, US, NYC places) and three temporal datasets (historical figures, artworks, news headlines) in the Llama-2 family of models. We discover that LLMs learn linear representations of space and time across multiple scales. These representations are robust to prompting variations and unified across different entity types (e.g. cities and landmarks). In addition, we identify individual ``space neurons'' and ``time neurons'' that reliably encode spatial and temporal coordinates. Our analysis demonstrates that modern LLMs acquire structured knowledge about fundamental dimensions such as space and time, supporting the view that they learn not merely superficial statistics, but literal world models.
Finding Neurons in a Haystack: Case Studies with Sparse Probing
May 02, 2023Despite rapid adoption and deployment of large language models (LLMs), the internal computations of these models remain opaque and poorly understood. In this work, we seek to understand how high-level human-interpretable features are represented within the internal neuron activations of LLMs. We train $k$-sparse linear classifiers (probes) on these internal activations to predict the presence of features in the input; by varying the value of $k$ we study the sparsity of learned representations and how this varies with model scale. With $k=1$, we localize individual neurons which are highly relevant for a particular feature, and perform a number of case studies to illustrate general properties of LLMs. In particular, we show that early layers make use of sparse combinations of neurons to represent many features in superposition, that middle layers have seemingly dedicated neurons to represent higher-level contextual features, and that increasing scale causes representational sparsity to increase on average, but there are multiple types of scaling dynamics. In all, we probe for over 100 unique features comprising 10 different categories in 7 different models spanning 70 million to 6.9 billion parameters.