 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improvement as Coherence Optimization: A Theoretical Account
Jan 20, 2026Can language models improve their accuracy without external supervision? Methods such as debate, bootstrap, and internal coherence maximization achieve this surprising feat, even matching golden finetuning performance. Yet why they work remains theoretically unclear. We show that they are all special cases of coherence optimization: finding a context-to-behavior mapping that's most compressible and jointly predictable. We prove that coherence optimization is equivalent to description-length regularization, and that among all such regularization schemes, it is optimal for semi-supervised learning when the regularizer is derived from a pretrained model. Our theory, supported by preliminary experiments, explains why feedback-free self-improvement works and predicts when it should succeed or fail.
The Lock-in Hypothesis: Stagnation by Algorithm
Jun 06, 2025The training and deployment of large language models (LLMs) create a feedback loop with human users: models learn human beliefs from data, reinforce these beliefs with generated content, reabsorb the reinforced beliefs, and feed them back to users again and again. This dynamic resembles an echo chamber. We hypothesize that this feedback loop entrenches the existing values and beliefs of users, leading to a loss of diversity and potentially the lock-in of false beliefs. We formalize this hypothesis and test it empirically with agent-based LLM simulations and real-world GPT usage data. Analysis reveals sudden but sustained drops in diversity after the release of new GPT iterations, consistent with the hypothesized human-AI feedback loop. Code and data available at https://thelockinhypothesis.com
Multilevel Interpretability Of Artificial Neural Networks: Leveraging Framework And Methods From Neuroscience
Aug 26, 2024
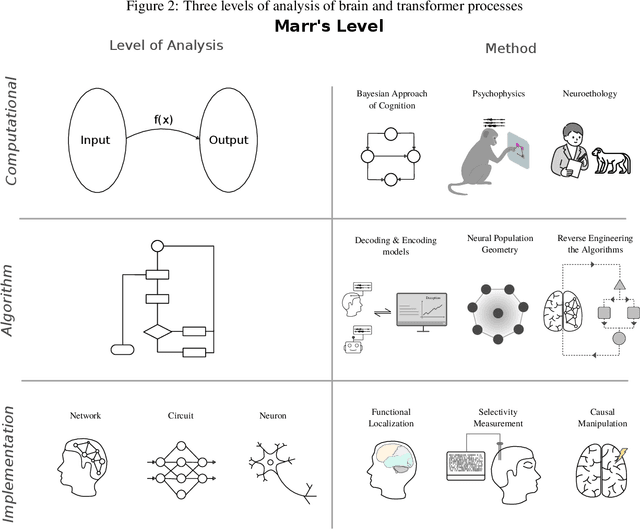
As deep learning systems are scaled up to many billions of parameters, relating their internal structure to external behaviors becomes very challenging. Although daunting, this problem is not new: Neuroscientists and cognitive scientists have accumulated decades of experience analyzing a particularly complex system - the brain. In this work, we argue that interpreting both biological and artificial neural systems requires analyzing those systems at multiple levels of analysis, with different analytic tools for each level. We first lay out a joint grand challenge among scientists who study the brain and who study artificial neural networks: understanding how distributed neural mechanisms give rise to complex cognition and behavior. We then present a series of analytical tools that can be used to analyze biological and artificial neural systems, organizing those tools according to Marr's three levels of analysis: computation/behavior, algorithm/representation, and implementation. Overall, the multilevel interpretability framework provides a principled way to tackle neural system complexity; links structure, computation, and behavior; clarifies assumptions and research priorities at each level; and paves the way toward a unified effort for understanding intelligent systems, may they be biological or artificial.
AI Alignment: A Comprehensive Survey
Nov 01, 2023AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, the potential large-scale risks associated with misaligned AI systems become salient. Hundreds of AI experts and public figures have expressed concerns about AI risks, arguing that "mitigating the risk of extinction from AI should be a global priority, alongside other societal-scale risks such as pandemics and nuclear war". To provide a comprehensive and up-to-date overview of the alignment field, in this survey paper, we delve into the core concepts, methodology, and practice of alignment. We identify the RICE principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality. Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. Forward alignment and backward alignment form a recurrent process where the alignment of AI systems from the forward process is verified in the backward process, meanwhile providing updated objectives for forward alignment in the next round. On forward alignment, we discuss learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices that apply to every stage of AI systems' lifecycle. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.