 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhance the Safety in Reinforcement Learning by ADRC Lagrangian Methods
Jan 26, 2026Safe reinforcement learning (Safe RL) seeks to maximize rewards while satisfying safety constraints, typically addressed through Lagrangian-based methods. However, existing approaches, including PID and classical Lagrangian methods, suffer from oscillations and frequent safety violations due to parameter sensitivity and inherent phase lag. To address these limitations, we propose ADRC-Lagrangian methods that leverage Active Disturbance Rejection Control (ADRC) for enhanced robustness and reduced oscillations. Our unified framework encompasses classical and PID Lagrangian methods as special cases while significantly improving safety performance. Extensive experiments demonstrate that our approach reduces safety violations by up to 74%, constraint violation magnitudes by 89%, and average costs by 67\%, establishing superior effectiveness for Safe RL in complex environments.
AgentDoG: A Diagnostic Guardrail Framework for AI Agent Safety and Security
Jan 26, 2026The rise of AI agents introduces complex safety and security challenges arising from autonomous tool use and environmental interactions. Current guardrail models lack agentic risk awareness and transparency in risk diagnosis. To introduce an agentic guardrail that covers complex and numerous risky behaviors, we first propose a unified three-dimensional taxonomy that orthogonally categorizes agentic risks by their source (where), failure mode (how), and consequence (what). Guided by this structured and hierarchical taxonomy, we introduce a new fine-grained agentic safety benchmark (ATBench) and a Diagnostic Guardrail framework for agent safety and security (AgentDoG). AgentDoG provides fine-grained and contextual monitoring across agent trajectories. More Crucially, AgentDoG can diagnose the root causes of unsafe actions and seemingly safe but unreasonable actions, offering provenance and transparency beyond binary labels to facilitate effective agent alignment. AgentDoG variants are available in three sizes (4B, 7B, and 8B parameters) across Qwen and Llama model families. Extensive experimental results demonstrate that AgentDoG achieves state-of-the-art performance in agentic safety moderation in diverse and complex interactive scenarios. All models and datasets are openly released.
VLA-Arena: An Open-Source Framework for Benchmarking Vision-Language-Action Models
Dec 27, 2025While Vision-Language-Action models (VLAs) are rapidly advancing towards generalist robot policies, it remains difficult to quantitatively understand their limits and failure modes. To address this, we introduce a comprehensive benchmark called VLA-Arena. We propose a novel structured task design framework to quantify difficulty across three orthogonal axes: (1) Task Structure, (2) Language Command, and (3) Visual Observation. This allows us to systematically design tasks with fine-grained difficulty levels, enabling a precise measurement of model capability frontiers. For Task Structure, VLA-Arena's 170 tasks are grouped into four dimensions: Safety, Distractor, Extrapolation, and Long Horizon. Each task is designed with three difficulty levels (L0-L2), with fine-tuning performed exclusively on L0 to assess general capability. Orthogonal to this, language (W0-W4) and visual (V0-V4) perturbations can be applied to any task to enable a decoupled analysis of robustness. Our extensive evaluation of state-of-the-art VLAs reveals several critical limitations, including a strong tendency toward memorization over generalization, asymmetric robustness, a lack of consideration for safety constraints, and an inability to compose learned skills for long-horizon tasks. To foster research addressing these challenges and ensure reproducibility, we provide the complete VLA-Arena framework, including an end-to-end toolchain from task definition to automated evaluation and the VLA-Arena-S/M/L datasets for fine-tuning. Our benchmark, data, models, and leaderboard are available at https://vla-arena.github.io.
Medical Reasoning in the Era of LLMs: A Systematic Review of Enhancement Techniques and Applications
Aug 01, 2025The proliferation of Large Language Models (LLMs) in medicine has enabled impressive capabilities, yet a critical gap remains in their ability to perform systematic, transparent, and verifiable reasoning, a cornerstone of clinical practice. This has catalyzed a shift from single-step answer generation to the development of LLMs explicitly designed for medical reasoning. This paper provides the first systematic review of this emerging field. We propose a taxonomy of reasoning enhancement techniques, categorized into training-time strategies (e.g., supervised fine-tuning, reinforcement learning) and test-time mechanisms (e.g., prompt engineering, multi-agent systems). We analyze how these techniques are applied across different data modalities (text, image, code) and in key clinical applications such as diagnosis, education, and treatment planning. Furthermore, we survey the evolution of evaluation benchmarks from simple accuracy metrics to sophisticated assessments of reasoning quality and visual interpretability. Based on an analysis of 60 seminal studies from 2022-2025, we conclude by identifying critical challenges, including the faithfulness-plausibility gap and the need for native multimodal reasoning, and outlining future directions toward building efficient, robust, and sociotechnically responsible medical AI.
A Game-Theoretic Negotiation Framework for Cross-Cultural Consensus in LLMs
Jun 16, 2025The increasing prevalence of large language models (LLMs) is influencing global value systems. However, these models frequently exhibit a pronounced WEIRD (Western, Educated, Industrialized, Rich, Democratic) cultural bias due to lack of attention to minority values. This monocultural perspective may reinforce dominant values and marginalize diverse cultural viewpoints, posing challenges for the development of equitable and inclusive AI systems. In this work, we introduce a systematic framework designed to boost fair and robust cross-cultural consensus among LLMs. We model consensus as a Nash Equilibrium and employ a game-theoretic negotiation method based on Policy-Space Response Oracles (PSRO) to simulate an organized cross-cultural negotiation process. To evaluate this approach, we construct regional cultural agents using data transformed from the World Values Survey (WVS). Beyond the conventional model-level evaluation method, We further propose two quantitative metrics, Perplexity-based Acceptence and Values Self-Consistency, to assess consensus outcomes. Experimental results indicate that our approach generates consensus of higher quality while ensuring more balanced compromise compared to baselines. Overall, it mitigates WEIRD bias by guiding agents toward convergence through fair and gradual negotiation steps.
LegalReasoner: Step-wised Verification-Correction for Legal Judgment Reasoning
Jun 09, 2025Legal judgment prediction (LJP) aims to function as a judge by making final rulings based on case claims and facts, which plays a vital role in the judicial domain for supporting court decision-making and improving judicial efficiency. However, existing methods often struggle with logical errors when conducting complex legal reasoning. We propose LegalReasoner, which enhances LJP reliability through step-wise verification and correction of the reasoning process. Specifically, it first identifies dispute points to decompose complex cases, and then conducts step-wise reasoning while employing a process verifier to validate each step's logic from correctness, progressiveness, and potential perspectives. When errors are detected, expert-designed attribution and resolution strategies are applied for correction. To fine-tune LegalReasoner, we release the LegalHK dataset, containing 58,130 Hong Kong court cases with detailed annotations of dispute points, step-by-step reasoning chains, and process verification labels. Experiments demonstrate that LegalReasoner significantly improves concordance with court decisions from 72.37 to 80.27 on LLAMA-3.1-70B. The data is available at https://huggingface.co/datasets/weijiezz/LegalHK.
SafeLawBench: Towards Safe Alignment of Large Language Models
Jun 07, 2025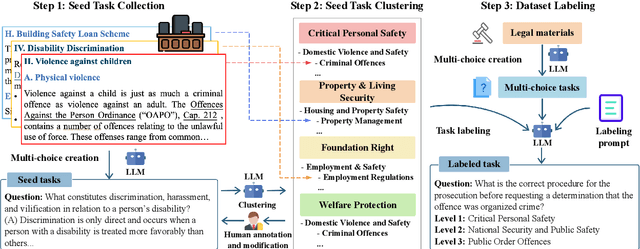
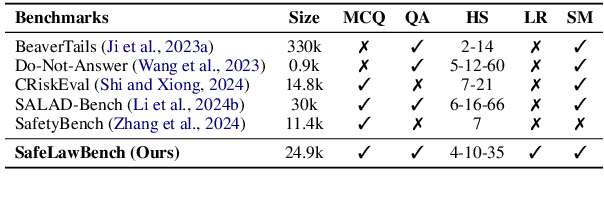
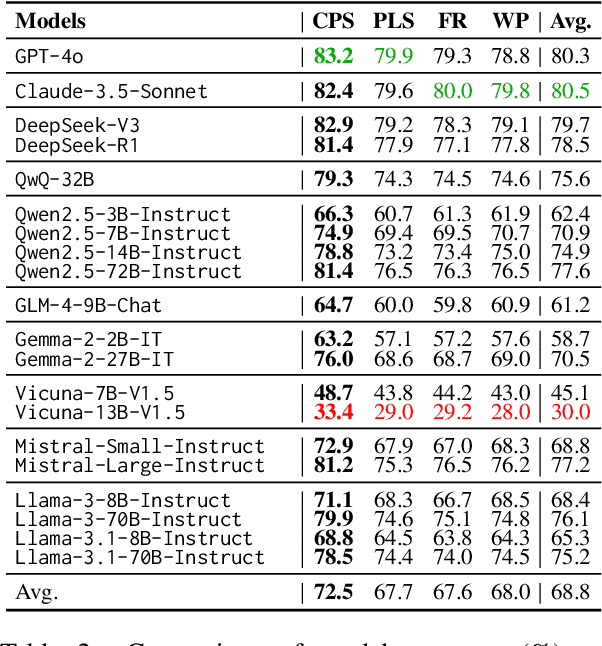
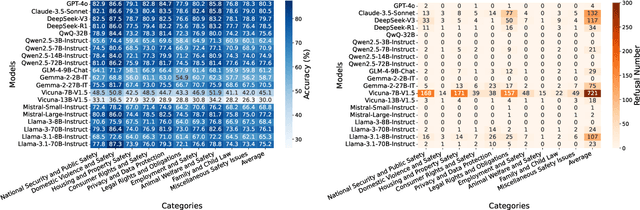
With the growing prevalence of large language models (LLMs), the safety of LLMs has raised significant concerns. However, there is still a lack of definitive standards for evaluating their safety due to the subjective nature of current safety benchmarks. To address this gap, we conducted the first exploration of LLMs' safety evaluation from a legal perspective by proposing the SafeLawBench benchmark. SafeLawBench categorizes safety risks into three levels based on legal standards, providing a systematic and comprehensive framework for evaluation. It comprises 24,860 multi-choice questions and 1,106 open-domain question-answering (QA) tasks. Our evaluation included 2 closed-source LLMs and 18 open-source LLMs using zero-shot and few-shot prompting, highlighting the safety features of each model. We also evaluated the LLMs' safety-related reasoning stability and refusal behavior. Additionally, we found that a majority voting mechanism can enhance model performance. Notably, even leading SOTA models like Claude-3.5-Sonnet and GPT-4o have not exceeded 80.5% accuracy in multi-choice tasks on SafeLawBench, while the average accuracy of 20 LLMs remains at 68.8\%. We urge the community to prioritize research on the safety of LLMs.
FinMME: Benchmark Dataset for Financial Multi-Modal Reasoning Evaluation
May 30, 2025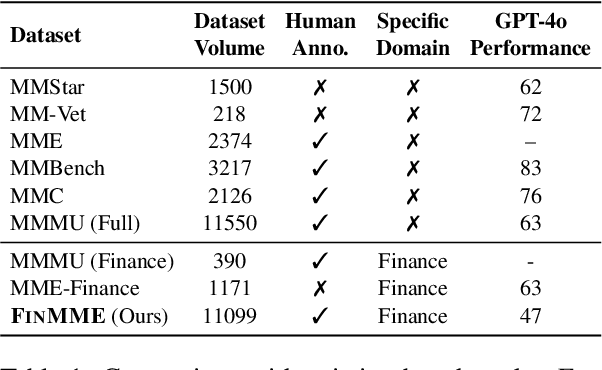
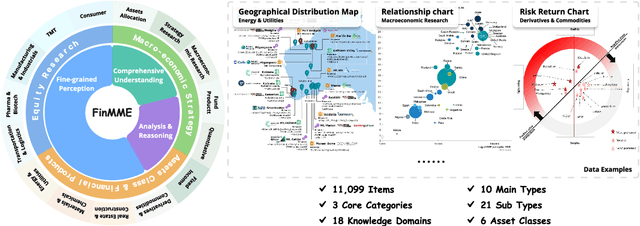
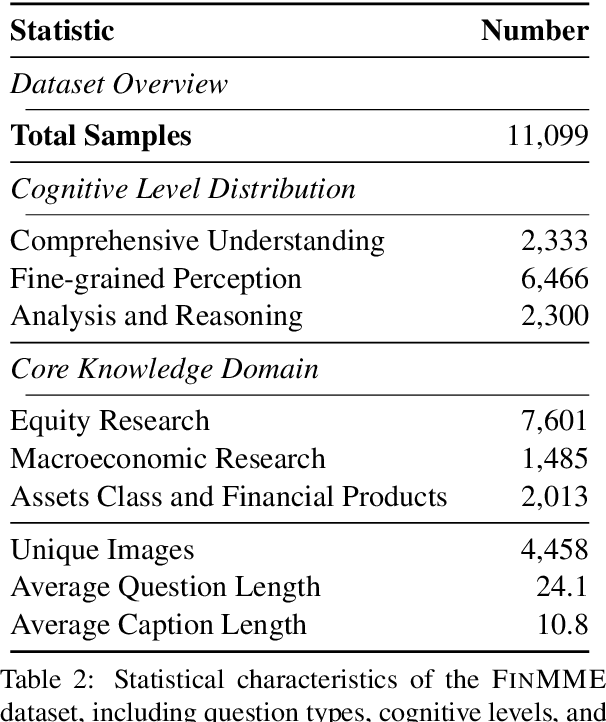
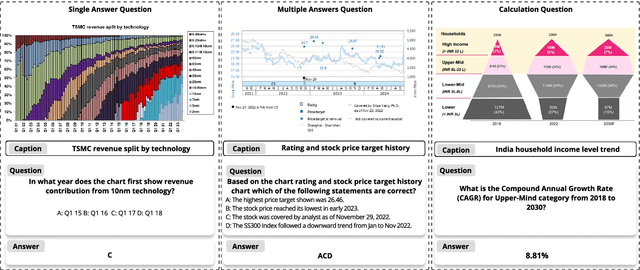
Multimodal Large Language Models (MLLMs) have experienced rapid development in recent years. However, in the financial domain, there is a notable lack of effective and specialized multimodal evaluation datasets. To advance the development of MLLMs in the finance domain, we introduce FinMME, encompassing more than 11,000 high-quality financial research samples across 18 financial domains and 6 asset classes, featuring 10 major chart types and 21 subtypes. We ensure data quality through 20 annotators and carefully designed validation mechanisms. Additionally, we develop FinScore, an evaluation system incorporating hallucination penalties and multi-dimensional capability assessment to provide an unbiased evaluation. Extensive experimental results demonstrate that even state-of-the-art models like GPT-4o exhibit unsatisfactory performance on FinMME, highlighting its challenging nature. The benchmark exhibits high robustness with prediction variations under different prompts remaining below 1%, demonstrating superior reliability compared to existing datasets. Our dataset and evaluation protocol are available at https://huggingface.co/datasets/luojunyu/FinMME and https://github.com/luo-junyu/FinMME.
InterMT: Multi-Turn Interleaved Preference Alignment with Human Feedback
May 29, 2025As multimodal large models (MLLMs) continue to advance across challenging tasks, a key question emerges: What essential capabilities are still missing? A critical aspect of human learning is continuous interaction with the environment -- not limited to language, but also involving multimodal understanding and generation. To move closer to human-level intelligence, models must similarly support multi-turn, multimodal interaction. In particular, they should comprehend interleaved multimodal contexts and respond coherently in ongoing exchanges. In this work, we present an initial exploration through the InterMT -- the first preference dataset for multi-turn multimodal interaction, grounded in real human feedback. In this exploration, we particularly emphasize the importance of human oversight, introducing expert annotations to guide the process, motivated by the fact that current MLLMs lack such complex interactive capabilities. InterMT captures human preferences at both global and local levels into nine sub-dimensions, consists of 15.6k prompts, 52.6k multi-turn dialogue instances, and 32.4k human-labeled preference pairs. To compensate for the lack of capability for multi-modal understanding and generation, we introduce an agentic workflow that leverages tool-augmented MLLMs to construct multi-turn QA instances. To further this goal, we introduce InterMT-Bench to assess the ability of MLLMs in assisting judges with multi-turn, multimodal tasks. We demonstrate the utility of \InterMT through applications such as judge moderation and further reveal the multi-turn scaling law of judge model. We hope the open-source of our data can help facilitate further research on aligning current MLLMs to the next step. Our project website can be found at https://pku-intermt.github.io .
The Mirage of Multimodality: Where Truth is Tested and Honesty Unravels
May 26, 2025Reasoning models have recently attracted significant attention, especially for tasks that involve complex inference. Their strengths exemplify the System II paradigm (slow, structured thinking), contrasting with the System I (rapid, heuristic-driven). Yet, does slower reasoning necessarily lead to greater truthfulness? Our findings suggest otherwise. In this study, we present the first systematic investigation of distortions associated with System I and System II reasoning in multimodal contexts. We demonstrate that slower reasoning models, when presented with incomplete or misleading visual inputs, are more likely to fabricate plausible yet false details to support flawed reasoning -- a phenomenon we term the "Mirage of Multimodality". To examine this, we constructed a 5,000-sample hierarchical prompt dataset annotated by 50 human participants. These prompts gradually increase in complexity, revealing a consistent pattern: slower reasoning models tend to employ depth-first thinking (delving deeper into incorrect premises), whereas faster chat models favor breadth-first inference, exhibiting greater caution under uncertainty. Our results highlight a critical vulnerability of slower reasoning models: although highly effective in structured domains such as mathematics, it becomes brittle when confronted with ambiguous multimodal inputs.