 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme dynamic symmetry enables omnidirectional and multifunctional robots
May 28, 2026Symmetry is a central organizing principle in natural systems, yet its use as a unifying design strategy in robotics has largely remained limited to geometric form. We show that symmetry can instead be leveraged at the level of dynamic actuation capability. We introduce dynamic symmetry, the uniformity of a robot's attainable center-of-mass accelerations, and formalize it through a measure coined as dynamic isotropy. Across more than 1000 simulated morphologies, we found that higher dynamic symmetry consistently improved trajectory tracking, task success, robustness, resiliency, and energy efficiency, with the benefits becoming most pronounced as dynamic isotropy approached its theoretical limit. To study this regime systematically, we developed Argus, a family of spherical robots designed to explore the effects of increasing dynamic symmetry. Members of the Argus family vary in their actuation geometry and dynamic symmetry level while sharing a common architectural principle: radially oriented linear actuators that directly shape the robot's center-of-mass dynamics. Among them, we built a physical 20-leg Argus variant that achieved near-extreme dynamic isotropy and demonstrated orientation-invariant locomotion, agile traversal of cluttered and deformable terrain, rapid self-stabilization, and resilience to partial actuator failures. Its distributed sensing further enabled omnidirectional perception and object interaction during continuous motion. These results show that designing robots for symmetry not only in morphology but also in their attainable dynamics provides a powerful and general pathway toward agility, robustness, and multifunctionality in uncertain terrestrial and extraterrestrial environments.
* Published in Science Robotics (2026). Our project website is at:https://generalroboticslab.com/Argus
MiraBench: Evaluating Action-Conditioned Reliability in Robotic World Models
May 28, 2026Action-conditioned world models are increasingly used as scalable simulators for robot learning, yet current evaluations provide limited evidence that their predictions are reliable under the actions they condition on. Existing benchmarks largely emphasize visual fidelity, leaving unclear whether predicted futures are physically plausible, faithful to commanded actions, and calibrated to failure when actions should not succeed. We introduce \textsc{MiraBench}, a hierarchical benchmark that defines \emph{action-conditioned reliability} as a core evaluation target for robotic world models. MiraBench decomposes this target into three progressively demanding levels: \emph{Physics Adherence}, which evaluates reference-free physical consistency; \emph{Action-Following Fidelity}, which measures whether predictions respect task-relevant action inputs; and \emph{Optimism Bias Detection}, which probes the tendency to predict successful outcomes under failure-inducing actions. To support this evaluation, we curate a human-annotated corpus with over 16,000 judgments across tasks, failure categories, and leading world models. We evaluate 12 representative model configurations spanning vector-conditioned robotic world models, text-conditioned generative world models, open-weight systems, closed-source systems, and multiple model scales. Across this broad model landscape, MiraBench reveals three central findings: visual fidelity is a poor proxy for action fidelity; increasing model scale does not reliably improve action following; and optimism bias is pervasive across current systems. By shifting evaluation from appearance to action-conditioned reliability, MiraBench provides a diagnostic foundation for assessing and improving robotic world models as faithful simulators.
CEER: Compliant End-Effector and Root Control as a Unified Interface for Hierarchical Humanoid Loco-Manipulation
May 19, 2026Humanoid robots have achieved impressive locomotion performance, yet contact-rich and long-horizon manipulation remains a major bottleneck. Manipulation is inherently contact-rich and demands compliant whole-body control for stable interaction, while its diversity and long-horizon nature favor modular, planner-compatible interfaces over joint-space tracking. We propose CEER, a compliant end-effector-root (EE-root) control abstraction for modular humanoid loco-manipulation within a hierarchical planning framework. CEER enables compliance-aware whole-body control in an interpretable task space defined by root motion commands and end-effector pose targets, and supports plug-and-play integration with heterogeneous high-level planners. A teacher-student framework is adopted to distill a general motion-tracking controller into a low-level policy that consumes only EE-root commands. We further construct a hierarchical system that integrates heterogeneous planners and task modules through the EE-root interface, enabling diverse manipulation tasks without retraining the underlying whole-body policy. Experiments in simulation and on hardware demonstrate 3.3 cm end-effector tracking accuracy with substantially reduced jerk compared to baselines, stable contact-rich manipulation under teleoperation, and up to 70% success in simulated single-object loco-manipulation tasks within a room-scale environment. These results indicate that compliant EE-root control provides a practical abstraction for humanoid loco-manipulation, enabling modular and scalable integration of diverse skills.
RAVEN: Retrieval-Augmented Vulnerability Exploration Network for Memory Corruption Analysis in User Code and Binary Programs
Apr 20, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities across various cybersecurity tasks, including vulnerability classification, detection, and patching. However, their potential in automated vulnerability report documentation and analysis remains underexplored. We present RAVEN (Retrieval Augmented Vulnerability Exploration Network), a framework leveraging LLM agents and Retrieval Augmented Generation (RAG) to synthesize comprehensive vulnerability analysis reports. Given vulnerable source code, RAVEN generates reports following the Google Project Zero Root Cause Analysis template. The framework uses four modules: an Explorer agent for vulnerability identification, a RAG engine retrieving relevant knowledge from curated databases including Google Project Zero reports and CWE entries, an Analyst agent for impact and exploitation assessment, and a Reporter agent for structured report generation. To ensure quality, RAVEN includes a task specific LLM Judge evaluating reports across structural integrity, ground truth alignment, code reasoning quality, and remediation quality. We evaluate RAVEN on 105 vulnerable code samples covering 15 CWE types from the NIST-SARD dataset. Results show an average quality score of 54.21%, supporting the effectiveness of our approach for automated vulnerability documentation.
RAFL: Generalizable Sim-to-Real of Soft Robots with Residual Acceleration Field Learning
Mar 23, 2026Differentiable simulators enable gradient-based optimization of soft robots over material parameters, control, and morphology, but accurately modeling real systems remains challenging due to the sim-to-real gap. This issue becomes more pronounced when geometry is itself a design variable. System identification reduces discrepancies by fitting global material parameters to data; however, when constitutive models are misspecified or observations are sparse, identified parameters often absorb geometry-dependent effects rather than reflect intrinsic material behavior. More expressive constitutive models can improve accuracy but substantially increase computational cost, limiting practicality. We propose a residual acceleration field learning (RAFL) framework that augments a base simulator with a transferable, element-level corrective dynamics field. Operating on shared local features, the model is agnostic to global mesh topology and discretization. Trained end-to-end through a differentiable simulator using sparse marker observations, the learned residual generalizes across shapes. In both sim-to-sim and sim-to-real experiments, our method achieves consistent zero-shot improvements on unseen morphologies, while system identification frequently exhibits negative transfer. The framework also supports continual refinement, enabling simulation accuracy to accumulate during morphology optimization.
GroundCount: Grounding Vision-Language Models with Object Detection for Mitigating Counting Hallucinations
Mar 11, 2026Vision Language Models (VLMs) exhibit persistent hallucinations in counting tasks, with accuracy substantially lower than other visual reasoning tasks (excluding sentiment). This phenomenon persists even in state-of-the-art reasoning-capable VLMs. Conversely, CNN-based object detection models (ODMs) such as YOLO excel at spatial localization and instance counting with minimal computational overhead. We propose GroundCount, a framework that augments VLMs with explicit spatial grounding from ODMs to mitigate counting hallucinations. In the best case, our prompt-based augmentation strategy achieves 81.3% counting accuracy on the best-performing model (Ovis2.5-2B) - a 6.6pp improvement - while reducing inference time by 22% through elimination of hallucination-driven reasoning loops for stronger models. We conduct comprehensive ablation studies demonstrating that positional encoding is a critical component, being beneficial for stronger models but detrimental for weaker ones. Confidence scores, by contrast, introduce noise for most architectures and their removal improves performance in four of five evaluated models. We further evaluate feature-level fusion architectures, finding that explicit symbolic grounding via structured prompts outperforms implicit feature fusion despite sophisticated cross-attention mechanisms. Our approach yields consistent improvements across four of five evaluated VLM architectures (6.2--7.5pp), with one architecture exhibiting degraded performance due to incompatibility between its iterative reflection mechanisms and structured prompts. These results suggest that counting failures stem from fundamental spatial-semantic integration limitations rather than architecture-specific deficiencies, while highlighting the importance of architectural compatibility in augmentation strategies.
Beyond Tokens: Semantic-Aware Speculative Decoding for Efficient Inference by Probing Internal States
Feb 03, 2026Large Language Models (LLMs) achieve strong performance across many tasks but suffer from high inference latency due to autoregressive decoding. The issue is exacerbated in Large Reasoning Models (LRMs), which generate lengthy chains of thought. While speculative decoding accelerates inference by drafting and verifying multiple tokens in parallel, existing methods operate at the token level and ignore semantic equivalence (i.e., different token sequences expressing the same meaning), leading to inefficient rejections. We propose SemanticSpec, a semantic-aware speculative decoding framework that verifies entire semantic sequences instead of tokens. SemanticSpec introduces a semantic probability estimation mechanism that probes the model's internal hidden states to assess the likelihood of generating sequences with specific meanings.Experiments on four benchmarks show that SemanticSpec achieves up to 2.7x speedup on DeepSeekR1-32B and 2.1x on QwQ-32B, consistently outperforming token-level and sequence-level baselines in both efficiency and effectiveness.
Learning Legged MPC with Smooth Neural Surrogates
Jan 17, 2026Deep learning and model predictive control (MPC) can play complementary roles in legged robotics. However, integrating learned models with online planning remains challenging. When dynamics are learned with neural networks, three key difficulties arise: (1) stiff transitions from contact events may be inherited from the data; (2) additional non-physical local nonsmoothness can occur; and (3) training datasets can induce non-Gaussian model errors due to rapid state changes. We address (1) and (2) by introducing the smooth neural surrogate, a neural network with tunable smoothness designed to provide informative predictions and derivatives for trajectory optimization through contact. To address (3), we train these models using a heavy-tailed likelihood that better matches the empirical error distributions observed in legged-robot dynamics. Together, these design choices substantially improve the reliability, scalability, and generalizability of learned legged MPC. Across zero-shot locomotion tasks of increasing difficulty, smooth neural surrogates with robust learning yield consistent reductions in cumulative cost on simple, well-conditioned behaviors (typically 10-50%), while providing substantially larger gains in regimes where standard neural dynamics often fail outright. In these regimes, smoothing enables reliable execution (from 0/5 to 5/5 success) and produces about 2-50x lower cumulative cost, reflecting orders-of-magnitude absolute improvements in robustness rather than incremental performance gains.
Large Video Planner Enables Generalizable Robot Control
Dec 17, 2025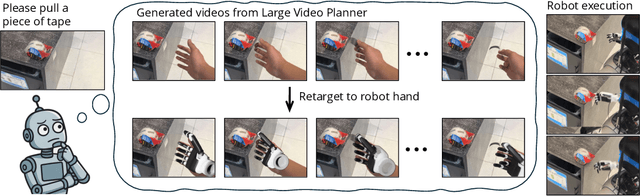
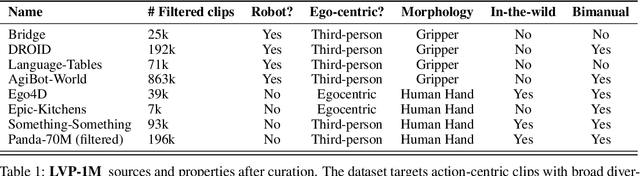
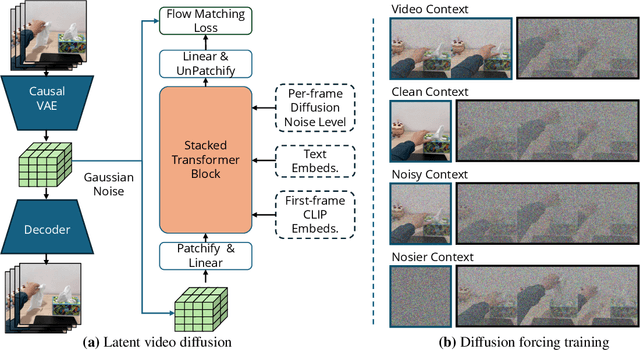

General-purpose robots require decision-making models that generalize across diverse tasks and environments. Recent works build robot foundation models by extending multimodal large language models (MLLMs) with action outputs, creating vision-language-action (VLA) systems. These efforts are motivated by the intuition that MLLMs' large-scale language and image pretraining can be effectively transferred to the action output modality. In this work, we explore an alternative paradigm of using large-scale video pretraining as a primary modality for building robot foundation models. Unlike static images and language, videos capture spatio-temporal sequences of states and actions in the physical world that are naturally aligned with robotic behavior. We curate an internet-scale video dataset of human activities and task demonstrations, and train, for the first time at a foundation-model scale, an open video model for generative robotics planning. The model produces zero-shot video plans for novel scenes and tasks, which we post-process to extract executable robot actions. We evaluate task-level generalization through third-party selected tasks in the wild and real-robot experiments, demonstrating successful physical execution. Together, these results show robust instruction following, strong generalization, and real-world feasibility. We release both the model and dataset to support open, reproducible video-based robot learning. Our website is available at https://www.boyuan.space/large-video-planner/.
Time-Aware Policy Learning for Adaptive and Punctual Robot Control
Nov 10, 2025


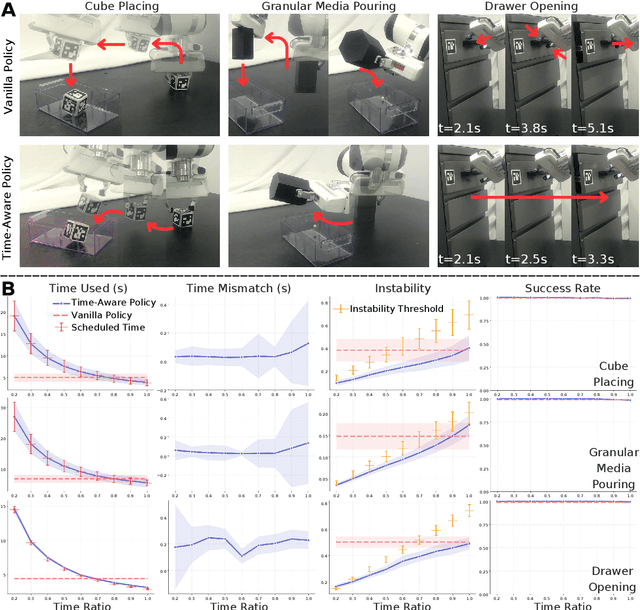
Temporal awareness underlies intelligent behavior in both animals and humans, guiding how actions are sequenced, paced, and adapted to changing goals and environments. Yet most robot learning algorithms remain blind to time. We introduce time-aware policy learning, a reinforcement learning framework that enables robots to explicitly perceive and reason with time as a first-class variable. The framework augments conventional reinforcement policies with two complementary temporal signals, the remaining time and a time ratio, which allow a single policy to modulate its behavior continuously from rapid and dynamic to cautious and precise execution. By jointly optimizing punctuality and stability, the robot learns to balance efficiency, robustness, resiliency, and punctuality without re-training or reward adjustment. Across diverse manipulation domains from long-horizon pick and place, to granular-media pouring, articulated-object handling, and multi-agent object delivery, the time-aware policy produces adaptive behaviors that outperform standard reinforcement learning baselines by up to 48% in efficiency, 8 times more robust in sim-to-real transfer, and 90% in acoustic quietness while maintaining near-perfect success rates. Explicit temporal reasoning further enables real-time human-in-the-loop control and multi-agent coordination, allowing robots to recover from disturbances, re-synchronize after delays, and align motion tempo with human intent. By treating time not as a constraint but as a controllable dimension of behavior, time-aware policy learning provides a unified foundation for efficient, robust, resilient, and human-aligned robot autonomy.