 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAPP: Large Language Model Feedback for Preference-Driven Reinforcement Learning
Apr 21, 2025



We introduce Large Language Model-Assisted Preference Prediction (LAPP), a novel framework for robot learning that enables efficient, customizable, and expressive behavior acquisition with minimum human effort. Unlike prior approaches that rely heavily on reward engineering, human demonstrations, motion capture, or expensive pairwise preference labels, LAPP leverages large language models (LLMs) to automatically generate preference labels from raw state-action trajectories collected during reinforcement learning (RL). These labels are used to train an online preference predictor, which in turn guides the policy optimization process toward satisfying high-level behavioral specifications provided by humans. Our key technical contribution is the integration of LLMs into the RL feedback loop through trajectory-level preference prediction, enabling robots to acquire complex skills including subtle control over gait patterns and rhythmic timing. We evaluate LAPP on a diverse set of quadruped locomotion and dexterous manipulation tasks and show that it achieves efficient learning, higher final performance, faster adaptation, and precise control of high-level behaviors. Notably, LAPP enables robots to master highly dynamic and expressive tasks such as quadruped backflips, which remain out of reach for standard LLM-generated or handcrafted rewards. Our results highlight LAPP as a promising direction for scalable preference-driven robot learning.
Perception Stitching: Zero-Shot Perception Encoder Transfer for Visuomotor Robot Policies
Jun 28, 2024



Vision-based imitation learning has shown promising capabilities of endowing robots with various motion skills given visual observation. However, current visuomotor policies fail to adapt to drastic changes in their visual observations. We present Perception Stitching that enables strong zero-shot adaptation to large visual changes by directly stitching novel combinations of visual encoders. Our key idea is to enforce modularity of visual encoders by aligning the latent visual features among different visuomotor policies. Our method disentangles the perceptual knowledge with the downstream motion skills and allows the reuse of the visual encoders by directly stitching them to a policy network trained with partially different visual conditions. We evaluate our method in various simulated and real-world manipulation tasks. While baseline methods failed at all attempts, our method could achieve zero-shot success in real-world visuomotor tasks. Our quantitative and qualitative analysis of the learned features of the policy network provides more insights into the high performance of our proposed method.
Policy Stitching: Learning Transferable Robot Policies
Sep 24, 2023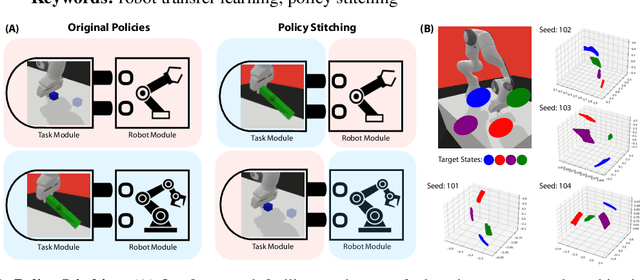
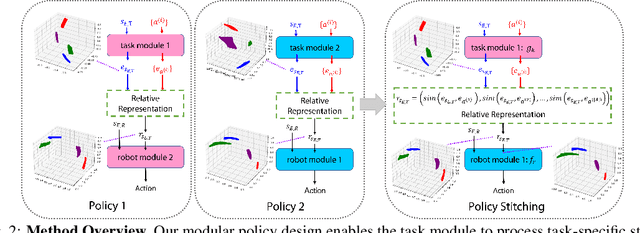

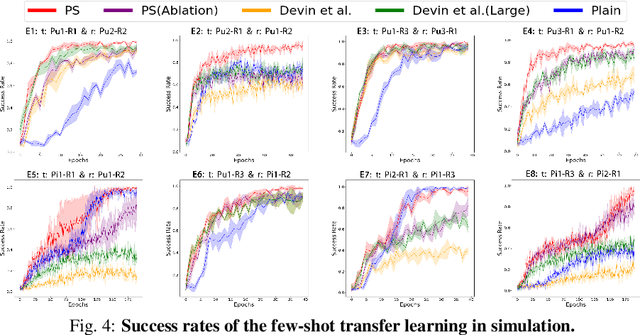
Training robots with reinforcement learning (RL) typically involves heavy interactions with the environment, and the acquired skills are often sensitive to changes in task environments and robot kinematics. Transfer RL aims to leverage previous knowledge to accelerate learning of new tasks or new body configurations. However, existing methods struggle to generalize to novel robot-task combinations and scale to realistic tasks due to complex architecture design or strong regularization that limits the capacity of the learned policy. We propose Policy Stitching, a novel framework that facilitates robot transfer learning for novel combinations of robots and tasks. Our key idea is to apply modular policy design and align the latent representations between the modular interfaces. Our method allows direct stitching of the robot and task modules trained separately to form a new policy for fast adaptation. Our simulated and real-world experiments on various 3D manipulation tasks demonstrate the superior zero-shot and few-shot transfer learning performances of our method. Our project website is at: http://generalroboticslab.com/PolicyStitching/ .
Disentangled Attention as Intrinsic Regularization for Bimanual Multi-Object Manipulation
Jul 06, 2021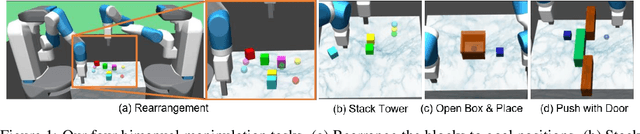

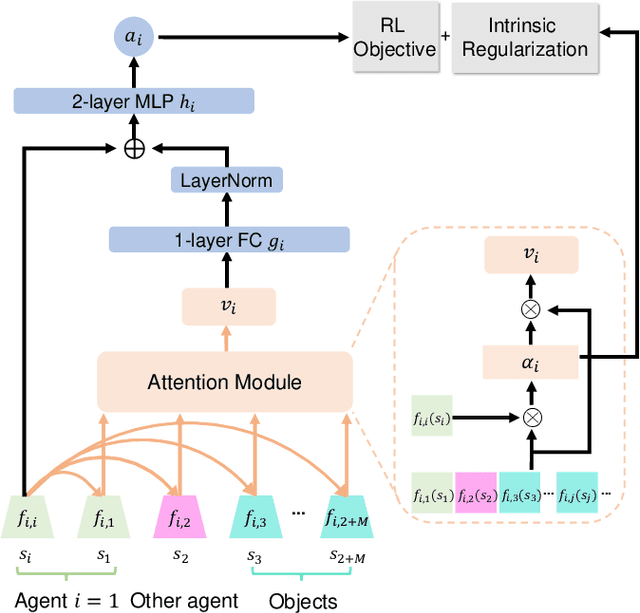

We address the problem of solving complex bimanual robot manipulation tasks on multiple objects with sparse rewards. Such complex tasks can be decomposed into sub-tasks that are accomplishable by different robots concurrently or sequentially for better efficiency. While previous reinforcement learning approaches primarily focus on modeling the compositionality of sub-tasks, two fundamental issues are largely ignored particularly when learning cooperative strategies for two robots: (i) domination, i.e., one robot may try to solve a task by itself and leaves the other idle; (ii) conflict, i.e., one robot can easily interrupt another's workspace when executing different sub-tasks simultaneously. To tackle these two issues, we propose a novel technique called disentangled attention, which provides an intrinsic regularization for two robots to focus on separate sub-tasks and objects. We evaluate our method on four bimanual manipulation tasks. Experimental results show that our proposed intrinsic regularization successfully avoids domination and reduces conflicts for the policies, which leads to significantly more effective cooperative strategies than all the baselines. Our project page with videos is at https://mehooz.github.io/bimanual-attention.
Adversarial Skill Learning for Robust Manipulation
Nov 06, 2020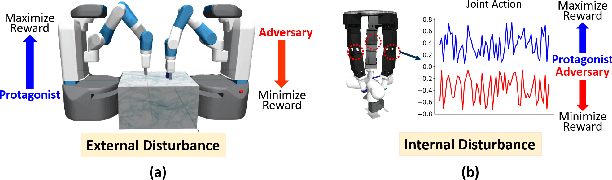
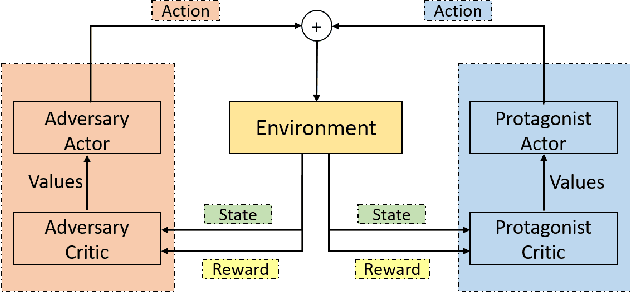

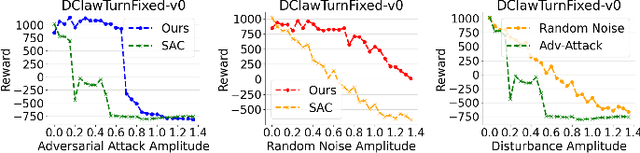
Deep reinforcement learning has made significant progress in robotic manipulation tasks and it works well in the ideal disturbance-free environment. However, in a real-world environment, both internal and external disturbances are inevitable, thus the performance of the trained policy will dramatically drop. To improve the robustness of the policy, we introduce the adversarial training mechanism to the robotic manipulation tasks in this paper, and an adversarial skill learning algorithm based on soft actor-critic (SAC) is proposed for robust manipulation. Extensive experiments are conducted to demonstrate that the learned policy is robust to internal and external disturbances. Additionally, the proposed algorithm is evaluated in both the simulation environment and on the real robotic platform.